









前一段时间的工作没来的急总结,现在总结一下!欢迎指正.......! @: kenny13141314@163.com
今天总结一篇大概是2019年的一篇文章,这篇文章在DIN 的基础之上进行了扩展,属于推荐系统中的精排部分。在DIN中的粗排选择了基于用户的协同过滤算法,因此这篇文章的实现我也采用基于用户的协同过滤算法作为粗排。实际上这篇文章比较简单,首先是通过协同过滤算法将每个用户的历史记录通过时间排序存储到字典中, 代码如下:
'''
@name: kenny adelaide
@time: 2022/4/26
@email: kenny13141314@163.com
@description:
=======================================================================================
this is a new model named DIEN, as the DIN model, it had introduced a new
GRU and AUGRU method to improve it's CTR prediction performance.
about this model that it had split into three main part of content.
1. first, we need to embedding the sort list by time of history as the embedding vectors. in the freamwork, we could
invoke the tookup function to implement that.
2. second, author constructs the extracting interest mechanism and interest evolution mechanism. named GUR and AUGUR.
here, this module has two unit named GUR and AUGUR, these units is a simply mathematical structure.
3. third, as the same of DIN, author had introduced the MLP to train the embedding information , including user's pro
-files and context features.
=======================================================================================
'''
class DataManager(object):
'''
this is a data manager.
'''
def __init__(self):
pass
# file_path = '../ratings.csv'
# self.read_data_to_tf_variable(file_path=file_path)
def read_data_to_tf_variable(self, file_path=None):
original_data = pd.read_csv(file_path)[['userId', 'movieId', 'rating', 'timestamp']]
df = pd.DataFrame(data=original_data)
original_data = np.array(df.sort_values(['userId', 'timestamp']))
original_dict = dict()
negative_samples = dict()
labels = dict()
for index, value in enumerate(original_data):
if int(value[0]) in original_dict.keys():
original_dict[int(value[0])].append(
self.arr_to_tf_Variable(value[1], 'item')
)
else:
temp = list()
temp.append(self.arr_to_tf_Variable(value[1], 'item'))
original_dict[int(value[0])] = temp
for index, value in enumerate(original_data):
if int(value[0]) not in negative_samples.keys():
temp = []
while (True):
negative_item = random.randint(1, 40815)
tf_negative_item = self.arr_to_tf_Variable(negative_item, 'item')
if tf_negative_item not in original_dict[int(value[0])]:
temp.append(tf_negative_item)
if len(temp) == len(original_dict[int(value[0])]):
negative_samples[int(value[0])] = temp
label_1 = [[[tf.Variable(1, dtype=tf.int32)], [tf.Variable(0, dtype=tf.float32)]] for i in
range(0, len(temp))]
label_0 = [[[tf.Variable(0, dtype=tf.int32)], [tf.Variable(1, dtype=tf.float32)]] for i in
range(0, len(temp))]
label = np.concatenate([label_1, label_0], axis=0)
labels[int(value[0])] = label
break
self.original_dict = original_dict
return original_dict, negative_samples, labels
def arr_to_tf_Variable(self, value, category):
return tf.Variable(int(value), dtype=tf.int32, name='{}_{}'.format(category, int(value)))
def train_sample(self, postive_samples, nagative_samples, labels):
train_data = []
for index, user in enumerate(postive_samples):
postive = postive_samples[user]
negative = negative_samples[user]
label = labels[user]
for _index, embedding in enumerate(postive):
temp1 = []
temp2 = []
temp1.append(postive[_index])
temp1.append(user)
temp1.append(label[_index])
train_data.append(temp1)
temp2.append(negative[_index])
temp2.append(user)
temp2.append(label[_index + len(postive)])
train_data.append(temp2)
return train_data
我定义了一个DataManager 类作为数据预处理的前置,主要实现了协同过滤以及将数据存储到字典中,并通过时间排序以及创建MLP的最终训练标签。由于采用的CTR 预测,因此采用了二分类标签。
定义好了数据预处理之后,我们观察论文中figure1 的网络结构:
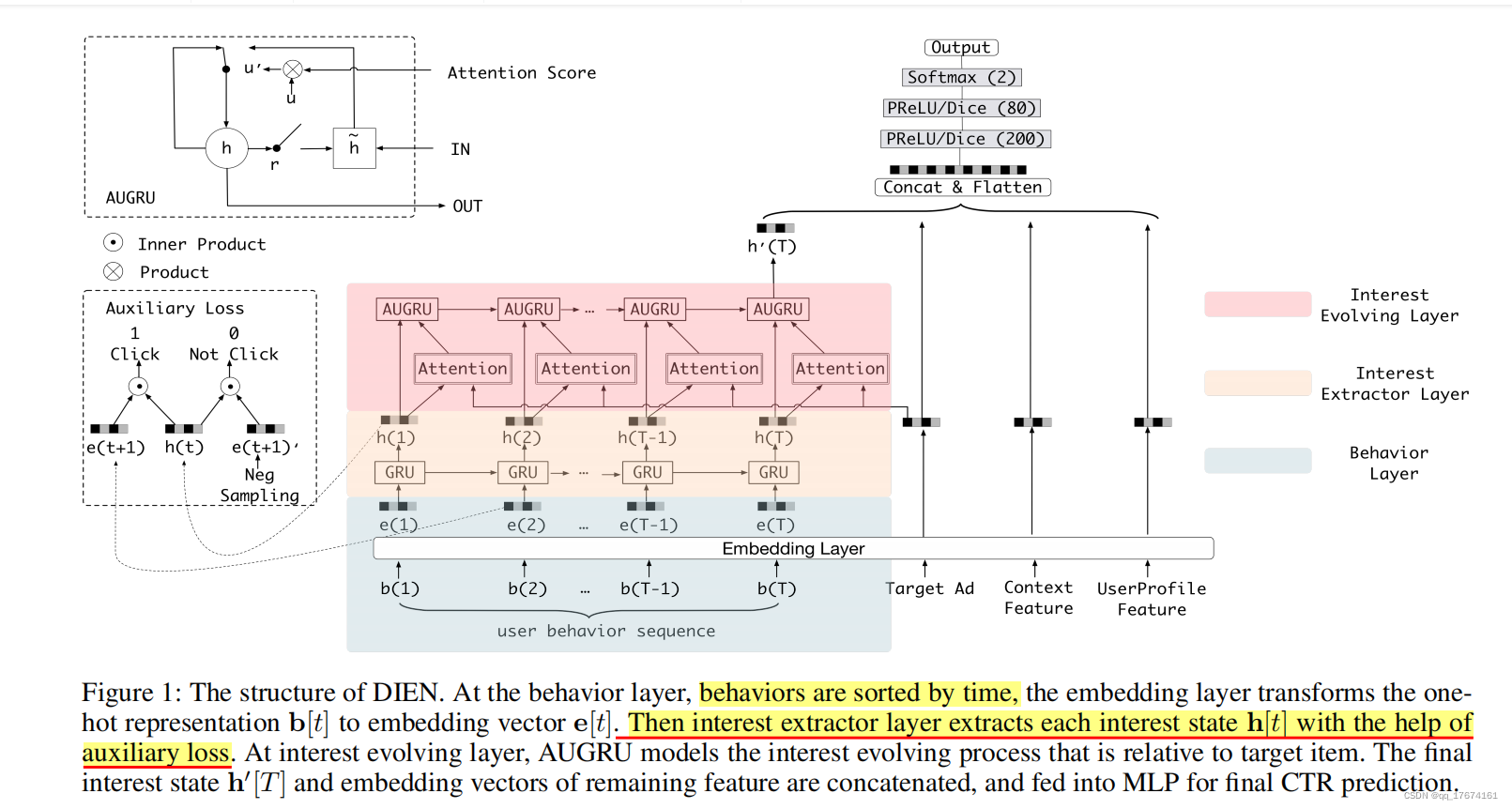
从图中可以知道,论文作者将每个用户的历史行为按照时间排序,组成了挖掘用户兴趣爱好的主体数据部分,同时新增了要预测目标的id, 上下文特征,以及用户的肖像数据, 因此数据样本的定义如下所示:
sample = [histories ads, target id, context, features, userProfile features]
samples = [sample 1, sample 2, sample 3, ..., sample i] , i=[1,2,3....n];
定义好了样本之后观察figure1 中明显接入了一个baseline 模型:MLP, 其输入为向量。
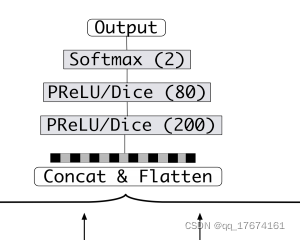
因此作者加入了一个embedding layer, 用于将ads, context feature 以及userid 转化为embedding, 在tensorflow 中采用查表的方式得到embedding vector, 原文是将数据的one-hot 表示转化为embedding ,vector我采用了类似的解决方案。直接 通过id 得到相关的embedding vector, 省去了one-hot 步骤, 定义如下:
class EmbeddingLayer(tf.keras.layers.Layer):
'''
this is a embedding layer for embeded one-hot vector to dense vector.
'''
def __init__(self, **kwargs):
super().__init__(**kwargs)
'''
first, we wanna implement the embedding that implemented the pool layer function before.
:param titles: feature weight name.
:param shape: the shape of weight.
:return: None
'''
self.items_embedding = tf.Variable(initial_value=tf.random.truncated_normal(shape=[206523, 32],
dtype=tf.float32),
dtype=tf.float32,
name='items_embedding', trainable=False)
self.user_embedding = tf.Variable(initial_value=tf.random.truncated_normal(shape=[973, 32],
dtype=tf.float32),
dtype=tf.float32,
name='user_embedding', trainable=False)
def call(self, inputs):
'''
return a list,
0 index is the list of history behavior,
1 index is the target that user are not visited。
2 index is the user id.
'''
items_embedding = tf.nn.embedding_lookup(self.items_embedding, inputs[0])
target_embedding = tf.nn.embedding_lookup(self.items_embedding, inputs[1])
target_embedding = tf.reshape(target_embedding, [target_embedding.shape[0], 1])
user_embedding = tf.nn.embedding_lookup(self.user_embedding, inputs[2])
user_embedding = tf.reshape(user_embedding, [user_embedding.shape[0], 1])
return items_embedding, target_embedding, user_embedding
需要注意的是, 我并没有采用context feature 作为sample 的组成部分, 因此在权重参数表定义的时候, 只定义了user 以及ad 表矩阵。
sample = [items_embedding, target_embedding, user_embedding]
文章中作者提出了一个很重要的观点, 即:DIN 中的兴趣表示不能真实的表示用户的兴趣爱好,强调用户兴趣是多样化的,它使用基于注意力的模型来捕获目标项的相对兴趣。因此作者使用了attention 作为挖掘用户兴趣的基本操作, 但是DIEN 中作者通过GUR以及AUGUR 获取用户兴趣的真实表示。同时引用了attention 机制前置挖掘用户的兴趣。设计结构如下所示:

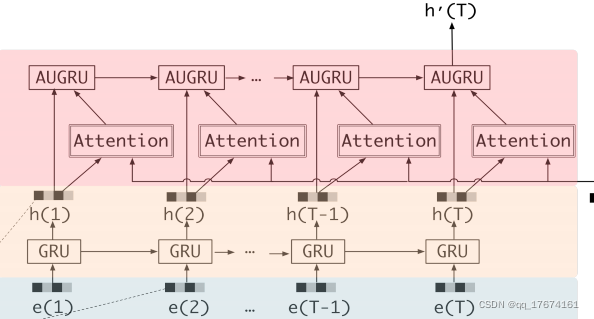
attention本来是NLP 中的一个机制,在很多文章中用于推荐系统的兴趣挖掘,采用的self-attention, 可以参考我博客中的文章了解原理,其实很简单, 定义如下所示:
class AttentionLayer(tf.keras.layers.Layer):
'''
this is a mechanism for get the attention score by vector.
'''
def __init__(self, **kwargs):
super().__init__(**kwargs)
def build(self, input_shape):
pass
def calculating_similarity(self, ht, target_embedding):
target_embedding = tf.reshape(target_embedding, (target_embedding.shape[0], 1))
return tf.nn.softmax(tf.matmul(ht, target_embedding, transpose_a=True))
def call(self, hts, target_embedding):
'''
inputs varable is a list:
0 index as the ht vector list.
1 index as the target embedding.
'''
ai_s = []
for _, ht in enumerate(hts):
similarity_weight = self.calculating_similarity(ht, target_embedding)
score = tf.reduce_sum(tf.multiply(similarity_weight, ht))
ai_s.append(score)
return ai_s
本质是加权求和以及通过softmax 将最终的结果进行归一化。
从结构中可以看出,与RNN 结构比较类似,但是有RNN 计算开销低,是RNN 结构计算的一中替换方式。原文如下所示:

我首先通过histories ads计算 GRU ,这是一没迭代一次就引入新参数计算的一中模式, 初始的GRU 需要有一个初始的参数, 在这里我通过自定义初始化,GUR定义如下:
class GURLayer(tf.keras.layers.Layer):
'''
this is a interest extractor layer named GUR module. if a user had visited n item order by time, and the number of
GUR is equal n, and the AUGUR is the same as n. hence , we need to get the extremely length of all user's item
number.
'''
def __init__(self, **kwargs):
super().__init__(**kwargs)
pass
def build(self, input_shape):
# this is the number of hidden state about per AUR.
self.hidden_size = 32
# this is the input's size
self.input_size = 32
self.W_U = tf.Variable(initial_value=tf.random.truncated_normal(shape=[self.hidden_size, self.input_size],
dtype=tf.float32),
dtype=tf.float32,
name='W_U', trainable=False)
self.W_R = tf.Variable(initial_value=tf.random.truncated_normal(shape=[self.hidden_size, self.input_size],
dtype=tf.float32),
dtype=tf.float32,
name='W_R', trainable=False)
self.W_H = tf.Variable(initial_value=tf.random.truncated_normal(shape=[self.hidden_size, self.input_size],
dtype=tf.float32),
dtype=tf.float32,
name='W_H', trainable=False)
self.U_Z = tf.Variable(initial_value=tf.random.truncated_normal(shape=[self.hidden_size, self.hidden_size],
dtype=tf.float32),
dtype=tf.float32,
name='U_Z', trainable=False)
self.U_R = tf.Variable(initial_value=tf.random.truncated_normal(shape=[self.hidden_size, self.hidden_size],
dtype=tf.float32),
dtype=tf.float32,
name='U_R', trainable=False)
self.U_H = tf.Variable(initial_value=tf.random.truncated_normal(shape=[self.hidden_size, self.hidden_size],
dtype=tf.float32),
dtype=tf.float32,
name='U_H', trainable=False)
self.h_t_1 = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[self.hidden_size, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=False)
self.h_t = None
self.b_u = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[self.hidden_size, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=False, name='b_u')
self.b_r = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[self.hidden_size, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=False, name='b_r')
self.b_h = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[self.hidden_size, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=False, name='b_h')
def samples_negative(self, user):
'''
this is a sample function for negative. there are two sets about item, one of them is the history item list, and
another is the whole items list, we aim at that find a complement from the whole item list name negative item
list except history item list element. and return a element from negative item list as a negative sample.
'''
pass
def calculating(self, input, h_t_1):
self.h_t_1 = h_t_1
u_t = tf.nn.softmax(tf.add(tf.matmul(self.W_U, input), tf.matmul(self.U_Z, self.h_t_1)) + self.b_u)
r_t = tf.nn.softmax(tf.add(tf.matmul(self.W_R, input), tf.matmul(self.U_R, self.h_t_1)) + self.b_r)
_h_t = tf.nn.tanh(tf.matmul(self.W_H, input) + tf.multiply(r_t, tf.matmul(self.U_H, self.h_t_1)) + self.b_h)
# self.h_t = tf.multiply((1 - u_t), self.h_t_1) + tf.multiply(u_t, _h_t)
return tf.multiply((1 - u_t), self.h_t_1) + tf.multiply(u_t, _h_t)
def call(self, inputs):
hts = []
for _, history_embedding in enumerate(inputs):
history_embedding = tf.reshape(history_embedding, (history_embedding.shape[0], 1))
if _ == 0:
hts.append(self.calculating(history_embedding, self.h_t_1))
else:
hts.append(self.calculating(history_embedding, hts[_ - 1]))
return hts
相关的计算公式表示:



上面这张图中有一个很重要的步骤:采样。每一个用户的历史行为都定义为positive sample, 为了训练MLP实现CTR预测,需要寻找到每个用户历史行为成对的负样本(用户没有点击过的 negative sample)。positive sample size as N, negative sample size = N。 这部分好像我放在数据预处理前置中完成(好像)。 
该部分定义这个功能,我目前还没有实现。等完工之后继续搞定,很简单。AUGUR 定义代码如下:
class AUGRULayer(tf.keras.layers.Layer):
'''
this is a interest evolving layer named AUGUR module.
'''
def __init__(self, **kwargs):
super().__init__(**kwargs)
def calculating_augru(self, ai, _gur_ht, _gur_h_t_1):
u_t = ai * self.u_t
u_t = tf.nn.softmax(u_t)
_ht = tf.multiply((1 - u_t), _gur_h_t_1) + tf.multiply(u_t, _gur_ht)
return _ht
def build(self, input_shape):
self.hidden_size = 32
self.u_t = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[self.hidden_size, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=False, name='u_t')
self.h_t_1 = tf.Variable(0.0, trainable=False, name='h_t_1', dtype=tf.float32)
def call(self, hts, ai_s):
_hts = []
for _, value in enumerate(hts):
if _ == 0:
_hts.append(self.calculating_augru(ai_s[_], hts[_], self.h_t_1))
else:
_hts.append(self.calculating_augru(ai_s[_], hts[_ - 1], _hts[_ - 1]))
return _hts[-1]
原文公式如下:



当然还有两个变种GUR。通过AUGUR之后最终得到一个向量表示。
sample = [h(T), target embedding, context feature, userprofile feature]. 输入MLP 中进行计算。
class MLP(tf.keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
self.layer1_weight = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[64, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=True, name='layer1_weight')
self.layer1_b = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[64, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=True, name='layer1_b')
self.layer2_weight = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[32, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=True, name='layer2_weight')
self.layer2_b = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[32, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=True, name='layer2_b')
self.layer3_weight = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[2, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=True, name='layer3_weight')
self.layer3_b = tf.Variable(
initial_value=tf.random.truncated_normal(shape=[2, 1],
dtype=tf.float32),
dtype=tf.float32,
trainable=True, name='layer3_b')
def calculating(self, w, x, b):
temp = tf.Variable(np.sum(tf.matmul(w, x, transpose_b=True).numpy()), dtype=tf.float32) + b
return self.flatten(temp)
def call(self, inputs):
inputs = self.flatten(inputs)
x = self.calculating(self.layer1_weight, inputs, self.layer1_b)
x = tf.nn.relu(x)
x = self.calculating(self.layer2_weight, x, self.layer2_b)
x = tf.nn.relu(x)
x = self.calculating(self.layer2_weight, x, self.layer3_b)
y = tf.nn.softmax(x)
return y
def build(self, input_shape):
self.flatten = tf.keras.layers.Flatten()
DIEN 定义如下:
class DIEN(tf.keras.Model):
def __init__(self, **kwargs):
super().__init__(**kwargs)
def prelu(self, _x):
"""parametric ReLU activation"""
pos = tf.nn.relu(_x)
neg = tf.multiply(self._alpha, (_x - tf.abs(_x))) * 0.5
return pos + neg
def build(self, input_shape):
self.embedding_layer = EmbeddingLayer()
self.gur_Layer = GURLayer()
self.attention_layer = AttentionLayer()
self.augru_Layer = AUGRULayer()
self.mlp = MLP()
def call(self, inputs, original_dict, data_manager):
y_preds = []
y_trues = []
features_flattens = []
for index, data in enumerate(inputs):
y_trues.append(data[2])
histories = original_dict[int(data[1].numpy())]
# embedding layer will be not train the weight.
items_embedding, target_embedding, user_embedding = self.embedding_layer([histories,
data[0],
data_manager.arr_to_tf_Variable(
int(data[1].numpy()),
'user')])
hts = self.gur_Layer(items_embedding)
ai_s = self.attention_layer(hts, target_embedding)
_ht = self.augru_Layer(hts, ai_s)
features_flatten = tf.concat([_ht, target_embedding], axis=0)
y_pred = self.mlp(features_flatten)
y_preds.append(y_pred)
return tf.Variable(y_preds), tf.Variable(y_trues)
接下来我们观察一下loss 函数的模型结构:

loss 由两部分组成, 第一部分为MLP 的所产生的loss, 第二部分为辅助loss 函数。
前者为概率预测,后者由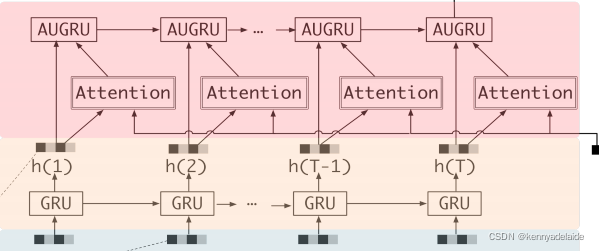
这部分产生。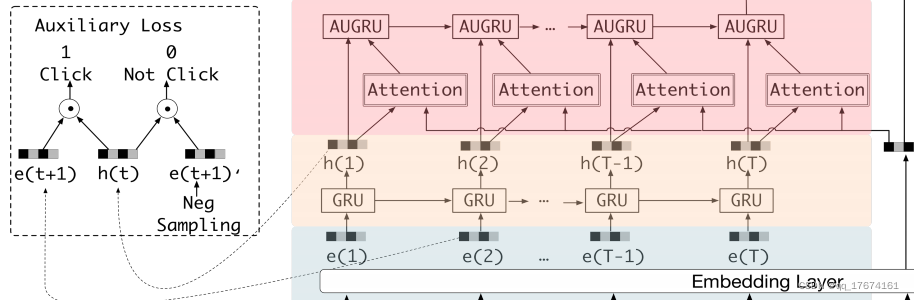
图左边对应公式6, whole loss 对用公式7.非常简单。
if __name__ == "__main__":
file_path = '../ratings.csv'
data_manager = DataManager()
original_dict, negative_samples, labels = data_manager.read_data_to_tf_variable(file_path)
train_data = data_manager.train_sample(original_dict, negative_samples, labels)
dien = DIEN()
optimizers = tf.keras.optimizers.Adadelta(learning_rate=1e-2)
losss = []
for i in range(0, 10):
with tf.GradientTape(persistent=True) as tape:
y_pred, y_true = dien(train_data, original_dict, data_manager)
_loss = tf.reduce_mean(tf.square(y_pred - y_true))
losss.append(_loss)
gradfients = tape.gradient(_loss, dien.trainable_variables)
optimizers.apply_gradients(zip(gradfients, dien.trainable_variables))
print(losss)
以上的编码过程还没有经过完全的检验, 公式6 暂时还没有实现,在假设没有辅助loss 的情况下进行训练。 希望浏览者提供代码的错误性提示, 共同进步,没来得及去检验和训练。需要注意的是,参数的更新,采用keras 的梯度计算在训练中容易出现梯度为None 的情况, 原因在于参数的计算公式keras 底层机制追踪不到,无法计算梯度。















 1069
1069











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









