






 本文深入讲解Google Cloud Spanner的查询计划生成与执行流程,通过实际案例解析查询计划,指导如何根据查询计划进行SQL优化。
本文深入讲解Google Cloud Spanner的查询计划生成与执行流程,通过实际案例解析查询计划,指导如何根据查询计划进行SQL优化。
Spanner 会为每条 SQL 生成一个或多个查询计划,并选择数据库认为最优的那个查询计划去执行,同一个 SQL,不同的查询计划最终的效率可能是千差万别的,理解查询计划是 SQL 优化的基本必备技能。
Spanner 本身有官方文档帮助大家理解查询计划,但是讲得比较精简,如果对 Spanner 不熟悉,可能理解起来比较困难,本文是这篇文档的扩展,但是会更浅显易懂、详细,有一些总结与延伸。
本文不会讲什么:
查询运算符详解(Query Operators),请自行参阅 Spanner 文档
本文会讲什么:
理解 Spanner 如何执行一个查询计划
如何看懂 GCP Console 下获取的 Spanner 的查询计划
如何基于查询计划作出优化
一、查询计划如何被执行
Spanner 是分布式数据库,因此一个数据库实例(Instance)是分布在多台 server 的,因此一条 SQL 可能意味着需要多台 server 配合才能产生最终结果。client 连接到 Spanner,Spanner 将 SQL 解析为查询计划(Query Plan),并选择一台 server 作为root server,Spanner 将 plan 发送到 root server,其他需要参与 query 的 server 称为 remote server,均被 root server 协调,它们接收 root server 下发的 subplan,然后将查询结果返回给 root server,最终由 root server 返回给 client。Root server 本身也参与 query,因此理论上有一部分 subplan 会下发给自己,也就是说 root server 本身也可以扮演 remote server。Root Server 下发 subplan 到各个 Remote Server 并从 Remote Server 收集结果的行为,在查询计划中称为Distributed Union。
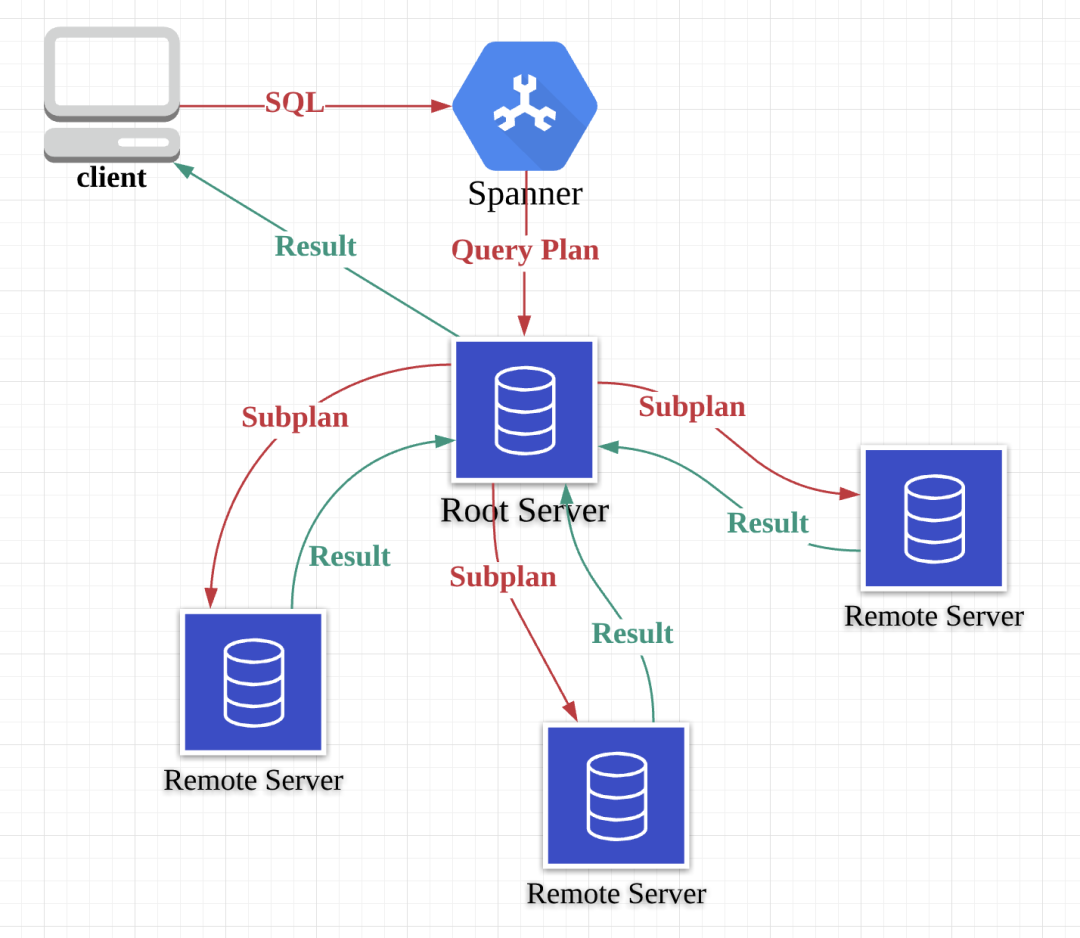 查询计划如何被分发
查询计划如何被分发
由于每台 server 都负责保存多个 splits,因此每台 remote server 收到 subplan 后,会将 subplan 再次分割为一到多个 splits 的查询计划,下发给特定的 split,每个 split 独立执行自己的计划并返回结果给 server,这个过程在查询计划中称为Local Distributed Union。
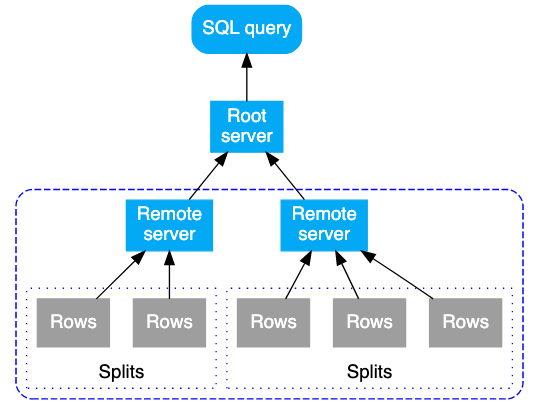 image.png
image.png
总结一下:Root Server 负责:
1\. 下发subplan到其他参与的server
2\. 等待所有server返回subplan结果给自己
3\. 汇总各个server的执行结果,如果需要的话,进行进一步处理
4\. 将汇总后的执行结果返回给client
Remote Server 负责:
1\. 接收Root Server下发的subplan
2\. 将subplan拆分成1个或多个分片的subplan并执行
3\. 汇总各个分片执行的结果
4\. 返回汇总的结果给Root Server
二、解读查询计划
1. Example — 简单查询计划
下图是摘自 Spanner 官方文档的查询计划 图中箭头由下往上,表示的是结果返回顺序,而查询计划的分发顺序恰恰相反,应该由上往下。
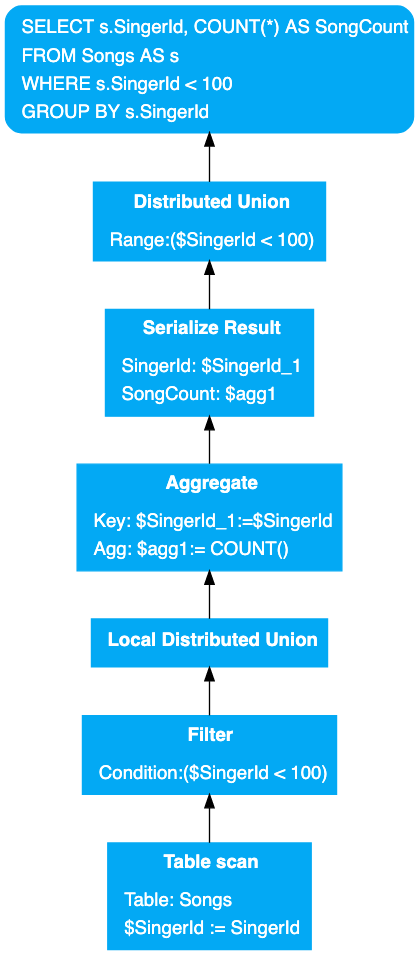 摘自 Spanner 官方文档的查询计划
摘自 Spanner 官方文档的查询计划
下发阶段
图中的查询计划表示 SQL 被解析为查询计划,发送给 Root Server,Root Server 进行Distriubted Union将 subplan 下发给 Remote Server 并等待最终结果。Serialize Result与Aggregate都是对结果进行处理的运算符,因此下发期间可以忽略。Remote Server(s) 收到 Root Server 的 subplan 后,将 subplan 拆分为特定 split(s) 的查询计划,交给特定的 split(s) 执行,也就是Local Distributed Union。在Local Distributed Union下就是每个 split 会进行的查询计划,此时查询计划分发完毕,我们开始从下往上读,解读执行与返回过程。
执行与返回阶段
每个 split 执行Table Scan,从 Songs 表读取 SingerId。每一个被读出的 SingerId 都会被Filter操作符根据 SingerId<100 的条件过滤,只有满足条件的,才会往上返回。被Filter返回的数据会在 Remote Server 进行Local Distributed Union,也就是结果集的合并,并且再往上返回。所有 Remote Server 都会将结果返回给Aggregator操作符,进行结果集的聚合。聚合后的结果被Serialize Result操作符组合为最终返回格式,这个操作符是每个查询计划都会有的,负责将查询出的数据转换为要发送回 client 的格式。转换为最终格式的数据,进行Distributed Union,返回 SQL 执行的最后结果。
整个查询计划结束
2. Example — 复杂查询计划
上面的简单查询计划只包括一元操作符,下面讲一下包含二元操作符的查询计划,比如进行 Join 操作。注意:下图生成的查询计划有个前提条件—— Albums 表是 Singers 表的子表,两者是 Interleave 关系。
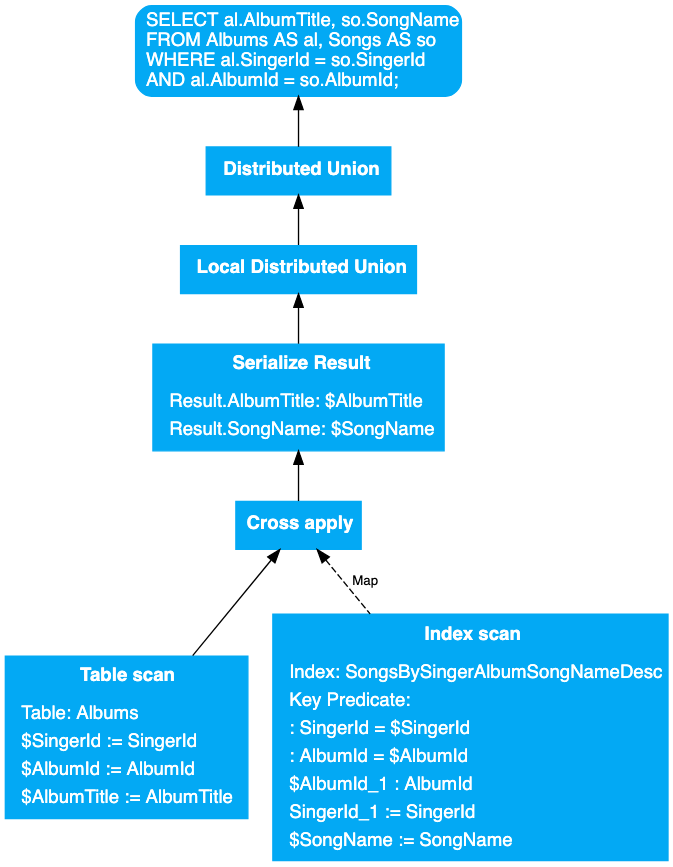 摘自 Spanner 官方文档的复杂查询计划
摘自 Spanner 官方文档的复杂查询计划
下发阶段
任何查询计划的分发都是差不多的,只有 4 个操作符涉及分发,那就是Distributed Union、Distributed Cross Apply、Distributed Outer Apply和Local Distributed Union,因此这里不再讲一遍。
执行与返回阶段
最底部是两个并排的查询计划,应该从左往右看,左边是 input,右边是对 input 进行 map 处理,也就是说,查询计划是从下往上执行,从左往右执行。先对 Albums 表进行Table Scan查出 SingerId、AlbumId、AlbumTitle 三个字段。Table Scan 的结果会返回给Cross Apply操作符,此操作符对结果进行 map,也就是为每个结果执行一次Index Scan。Index Scan查出 SongName 返回给Cross Apply。Cross Apply 将 Table Scan 与 Index Scan 的结果进行 Join,实际上Cross Apply操作符就是进行 nested loop join,由于两个参与 Join 的表是 Interleave 的,所以此 Cross Apply 只需要在本 Remote Server 上执行,否则应使用Distributed Cross Apply(将在下一个例子中说明)。Join 后的结果被Serialize Result转换为返回格式。Local Distributed Union整合此 Remote Server 上的所有 Results 返回给 Root Server。Root Server 进行Distributed Union将最终结果返回。
整个查询计划结束。
3. Example — Distributed Cross Apply 查询计划
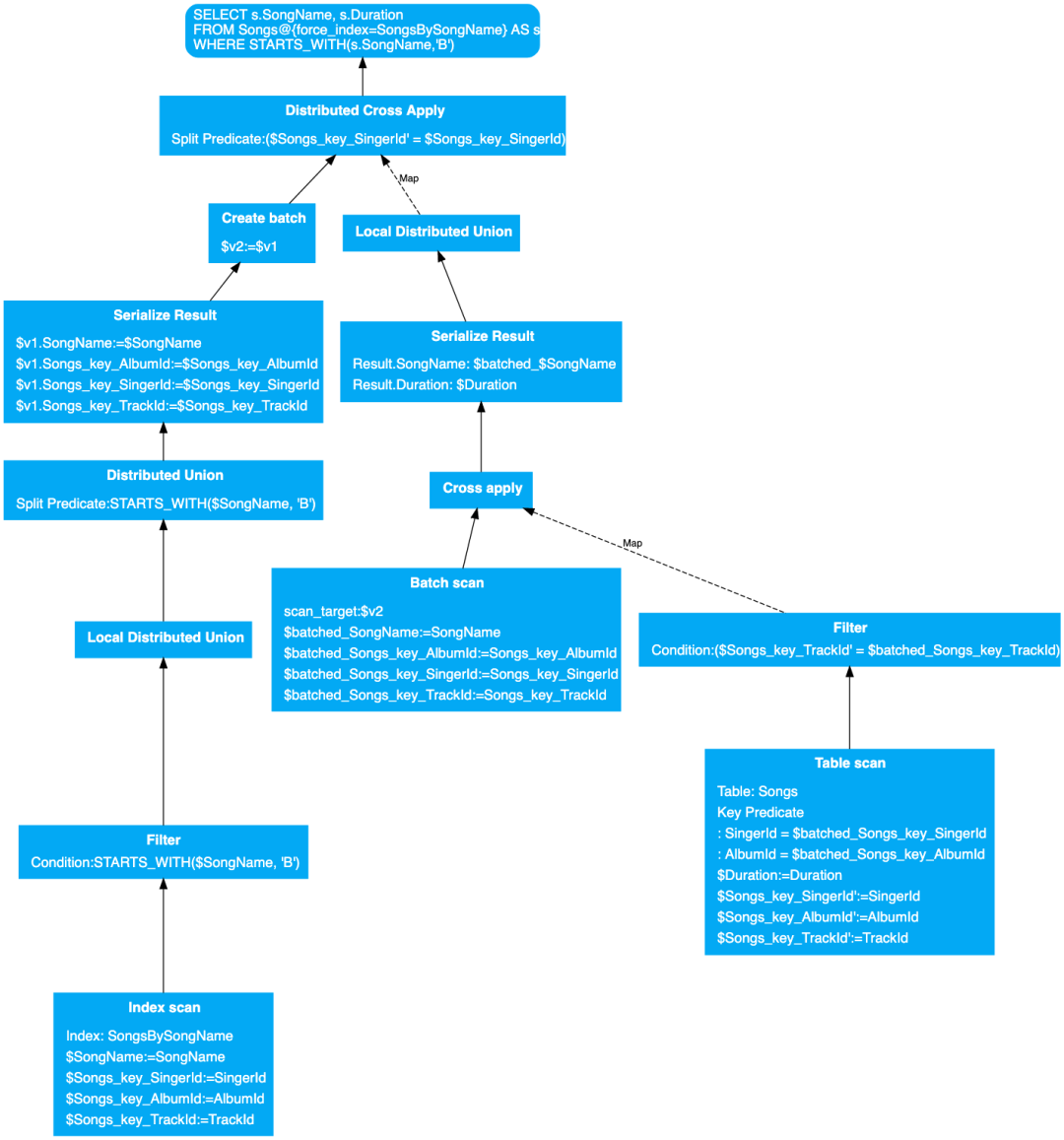 摘自 Spanner 官方文档的 Distributed Cross Apply 上图中的 SQL 需要读 2 张表,一张是索引 SongsBySongName,一张是数据表 Songs,索引无法 Interleave,所以索引和数据可以分别处于不同的分片,那么要实现这个 SQL,就不能使用
摘自 Spanner 官方文档的 Distributed Cross Apply 上图中的 SQL 需要读 2 张表,一张是索引 SongsBySongName,一张是数据表 Songs,索引无法 Interleave,所以索引和数据可以分别处于不同的分片,那么要实现这个 SQL,就不能使用(Local) Cross Apply,而需要使用Distributed Cross Apply,因此最顶层的操作符是Distributed Cross Apply。
下发阶段
Root Server 的Distributed Cross Apply会等待Distributed Union后进行Create Batch的结果作为 input,当Distributed Cross Apply收到Create Batch的结果作为 input 后,再下发 plan 给 Remote Server,做 map 操作。这里注意,下发其实被分为了两个阶段,左边先执行完,Distributed Cross Apply 才会进行右边的下发。
执行与返回阶段
Remote Server 将 plan 分配给多个 splits 进行Index Scan。Index Scan 的结果被Filter过滤符合条件的返回。Local Distributed Union汇总本台 server 上的数据发回给 Root Server。Root Server 使用Distributed Union汇总 Remote Server 发来的数据。Serialize Result格式化数据。Create Batch操作符代表创建中间表,因为涉及到跨 server 的 join,因此需要创建中间表。将 Create Batch 创建的中间表作为 input 发给Distributed Cross Apply操作符。Distributed Cross Apply下发查询到 Remote Server(进行 Map)。Batch Scan读取中间表并返回给Cross Apply。Cross Apply根据 Batch Scan 结果进行 Join 并通过Serialize Result、Local Distributed Union后返回给 Root Server。Distributed Cross Apply根据返回结果完成 Join,返回 SQL 执行结果。
整个查询计划结束。
4. 从 GCP Console 解读查询计划
在 GCP Console 中可以方便地获得查询计划,但不是图片形式,没有左右关系,因此我们需要将 Console 中的 text 展示的查询计划,在脑袋中转换为图片版的。
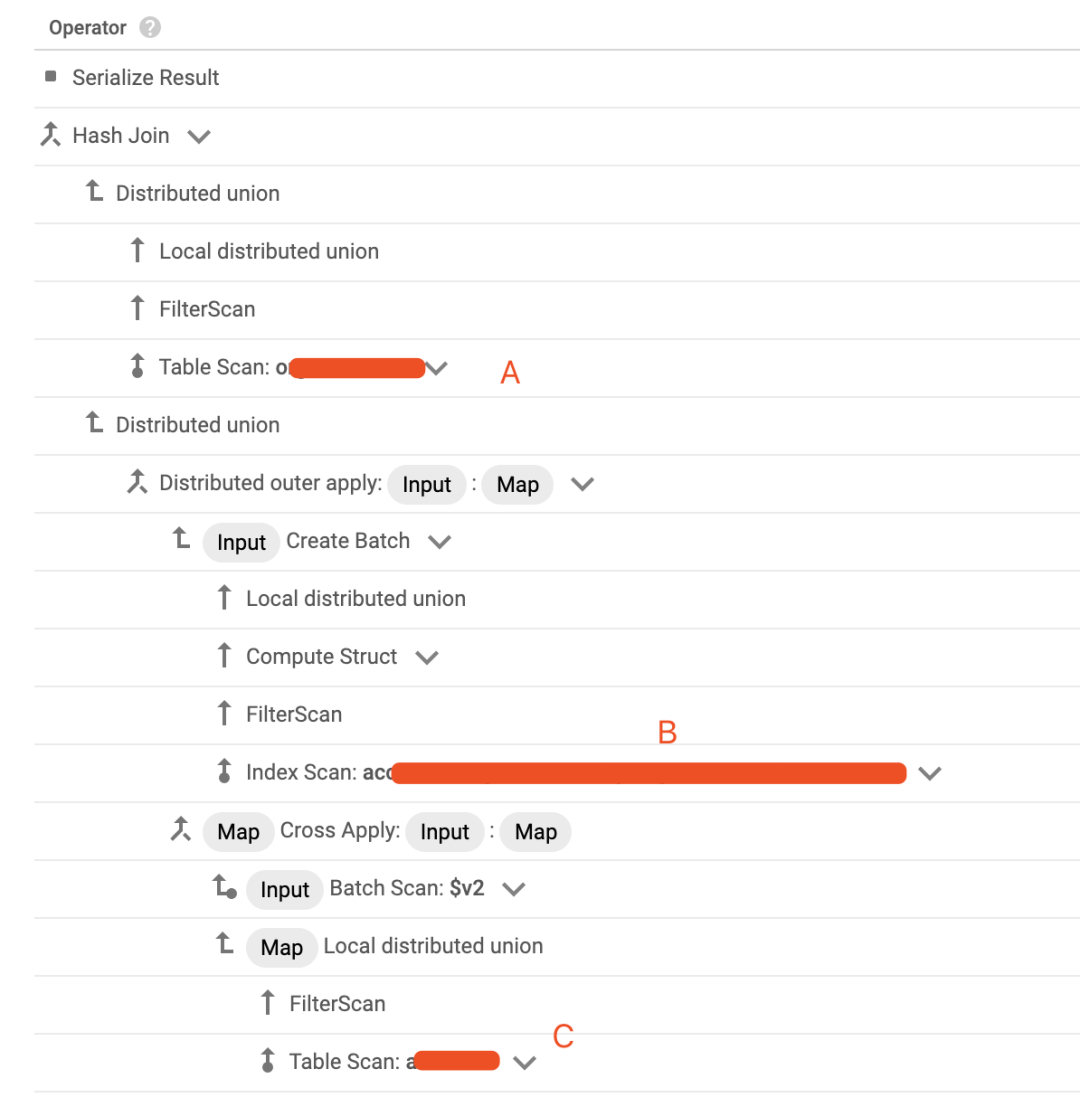 Console 查询计划
Console 查询计划
每行计划的开头都有一个小标记。转换原则是:
垂直箭头则表示上下关系。比如:
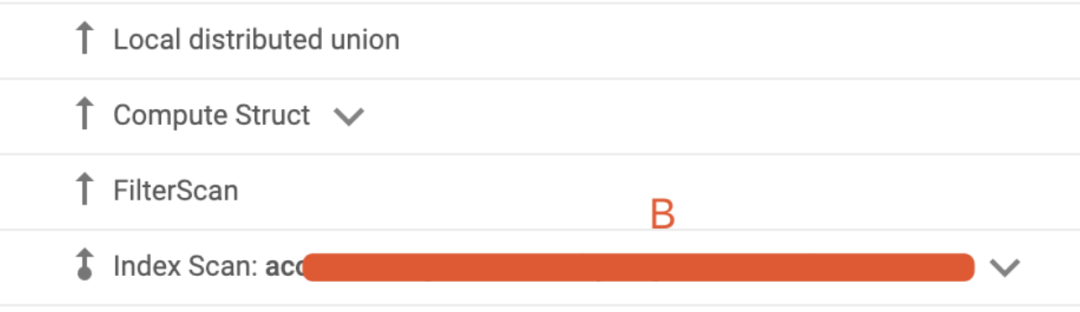 上下关系
上下关系人字型箭头代表这是一个接收多个参数的操作符,比如 Hash Join
 Hash Join 是二元操作符
Hash Join 是二元操作符直角箭头代表是父操作符的输入参数,比如图中两个 Distributed Union 不是上下级关系,而是兄弟关系,作为 Hash Join 的下级操作符,也就是 Hash Join 的输入参数,两个 Distributed Union 应该是左右排列。
对于应该左右排列的操作符,越上面出现,越左边,从左往右依次排放。
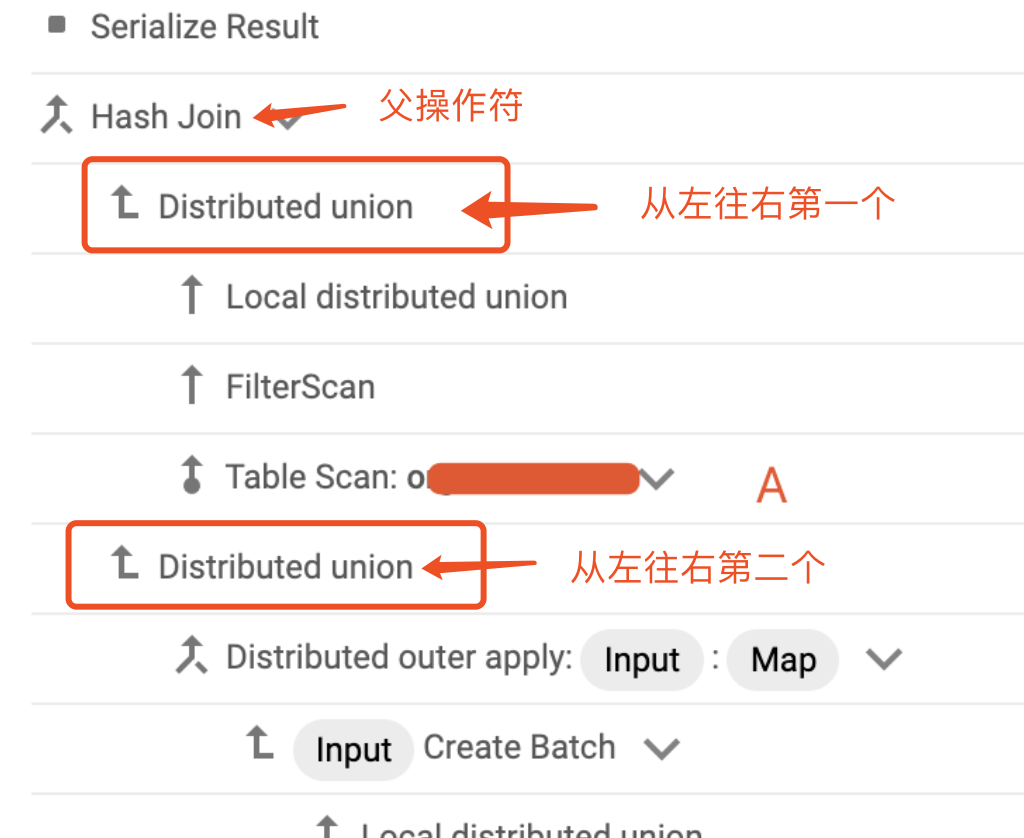 左右关系
左右关系
因此上图应该是如下:
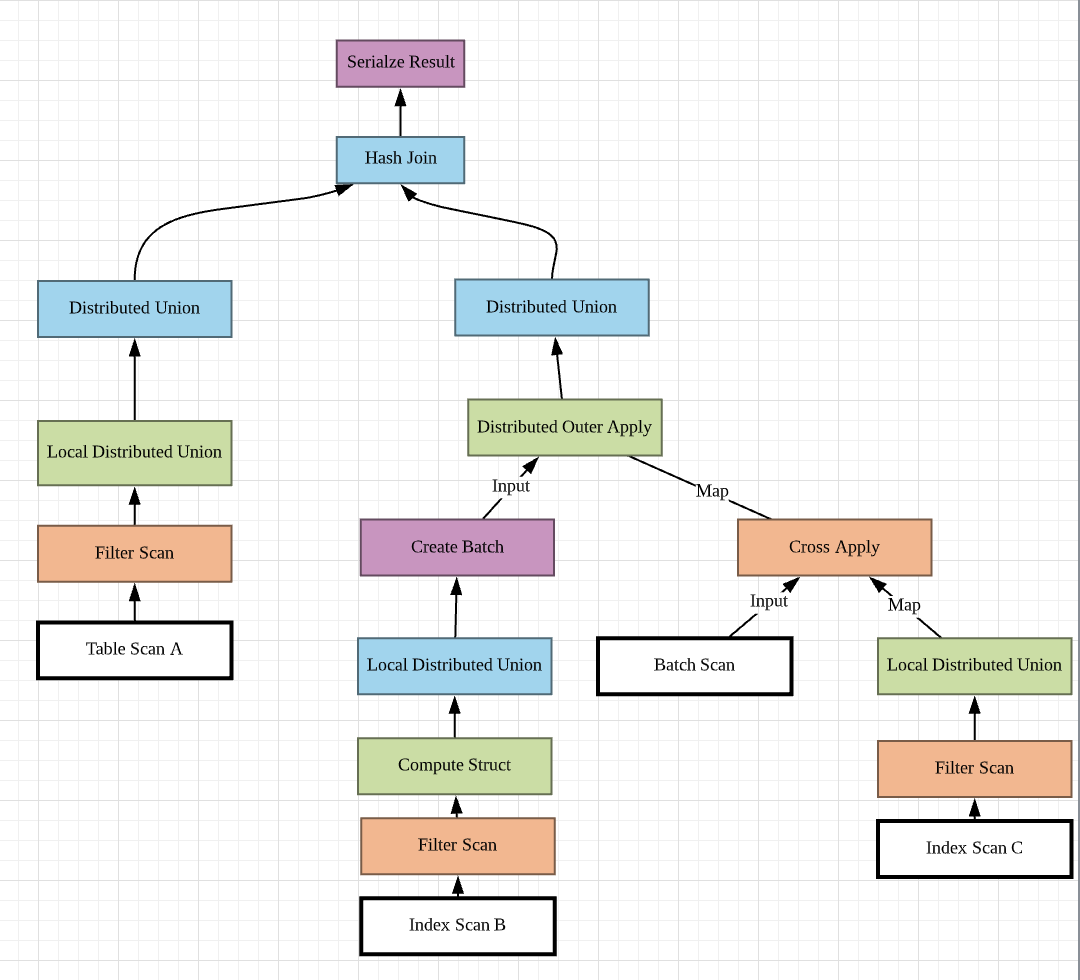 查询计划图
查询计划图
三、SQL 优化
我们可以根据查询计划对 SQL 进行优化,但是在优化之前务必尽量读懂查询计划,因此需要了解每个操作符的意义,在进行下面的阅读前最好能够先阅读 Spanner 操作符文档。
1. 为什么用了索引还是慢查询?
大家都知道全表扫描是严格禁止的(数据量特别小的表不在讨论范围),导致慢查询甚至拖垮数据库,于是往查询上面加索引,结果加了索引还是慢查询。为什么会出现这种情况,是因为大家忽略了导致慢查询的根本原因——大量磁盘 IO 导致 CPU 和内存被大量占用,全表扫描不用说,一定是大量的磁盘 IO,把表依次读一遍,实际上索引建得不好,也会有这种情况。在 Spanner 中,索引也是表,索引不过是只存储部分字段的表而已,可以理解为一个比数据表更小的表,如果查询条件不能利用索引的最左前缀原则,那么这个索引就只能被全索引扫描,Spanner 会将索引全部扫描一遍,利用 Filter 返回符合条件的行,对 CPU 和内存的占用极大。比如为 users 表建立一个 (user_name,email) 的索引,却使用这个索引进行 SELECT user_name FROM users WHERE email = xxx 查询,由于查询条件不包括 user_name,因此无法使用这个 Index 进行Filter Scan,也就是无法直接定位到索引所在数据页,而需要读取整个索引,进行Filter操作,也就是全表扫描(索引也是表,因此对表和索引的全扫描都可以称为全表扫描)。从 Spanner 的查询计划中可以看到是否对一个索引或者一个表使用了全表扫描,如下图:
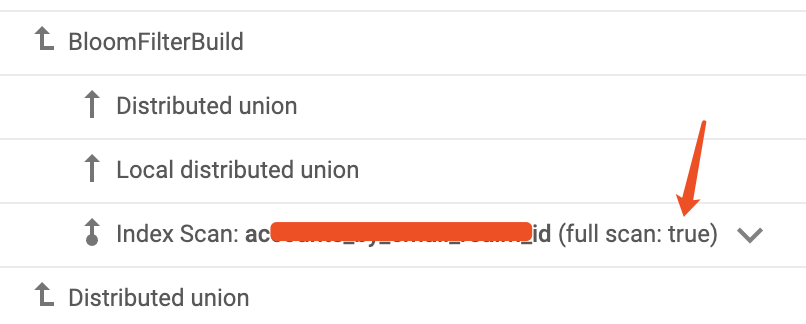 Full Scan 如果索引中有 100 万条记录,那么 100 万条都会被读入内存进行 Filter,CPU 和内存压力比较大,会出现慢查询,因此
Full Scan 如果索引中有 100 万条记录,那么 100 万条都会被读入内存进行 Filter,CPU 和内存压力比较大,会出现慢查询,因此对于查询计划中的 Full Scan 需要根据SQL运行频率、表大小进行评估,在必要的情况下建立更合适的索引避免 Full Scan。与 Full Scan 相对应的是Filter Scan,也就是直接定位到索引数据所在数据页,只读取符合条件的索引。注意,Filter Scan 与 Filter 是完全不一样的,详见官方文档。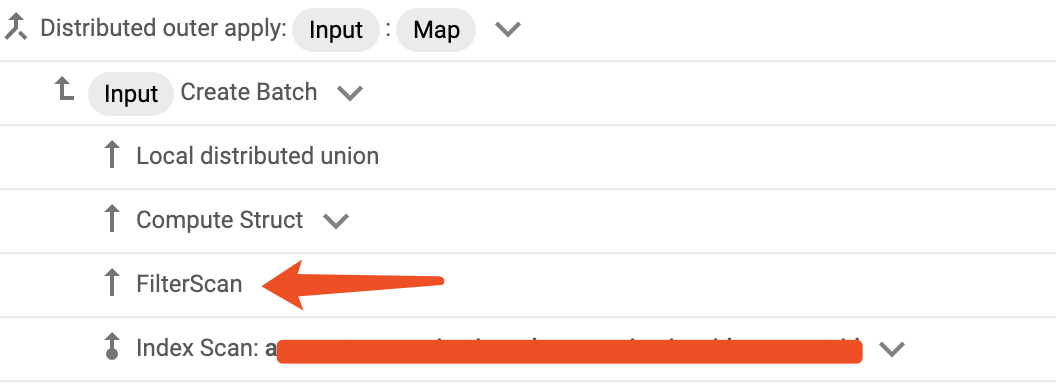 Filter Scan
Filter Scan
2. Apply Join 与 Hash Join 的选择
Apply Join
也就是 Nested Loop Join,接收一组记录作为 input,然后分别对每条 input 进行 Join,具体原理可以在网上搜到,这里就不多说。操作符Cross Apply即代表 Apply Join,它好处是,input 越小,需要进行的 join 记录数越少,读取越少,速度越快。可以说 Apply Join 是基于记录的(record-based)。
Hash Join
与 Apply Join 相反,Hash Join 是基于集合(set-based)的,对于参与 Join 的两张表,会选择更小的那一张,完全加载入内存,建立一个 Hash 表,再读取另一张表,匹配 Hash 完成 Join。可以通过这篇文章理解 Hash Join:《如何在分布式数据库中实现 Hash Join?》
综上所述,Hash Join 适合需要整张表参与的大数据集的 Join,而 Apply Join 适合记录较少的 Join。如果 WHERE 条件筛选后只有少量记录,那么 Apply Join 是更好的选择,此时如果选择 Hash Join,即使某张表被筛选出少量记录,另一张表还是会被全表读取,效率非常低。
3. 本机 Join 可减少开销
本机的 Join 比 Distributed Join 更快、开销更少,比如 Cross Apply 比 Distributed Cross Apply 更快,因此对于常用的 Join,优化思路是进行本机 Join 避免 Distributed Join。Interleave 是记录 co-located 的强保证,因此必要的情况下,可以使用 Interleave 提升 Join 效率。但是要注意 Interleave 的 co-located 保证也导致热点不能被分散,因此需要综合业务考虑后再决定是否使用 Interleave。
4. 测试比 Explaination 更重要
查询计划不是万能的,特别是仅仅使用 Spanner Console 的Explaination Only功能,是看不到最终扫描行数和执行效率的,对于查询计划的分析仅仅限于理论,理论必须结合实践,因此非常有必要在测试环境模拟足够的数据量去进行测试、调优、验证。
作者:AmazingBillions
链接:
https://www.jianshu.com/p/9d726cfca51f
关注我!Java从此不迷路!



















 177
177

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









