







深度学习:维度灾难
维度灾难的几何意义
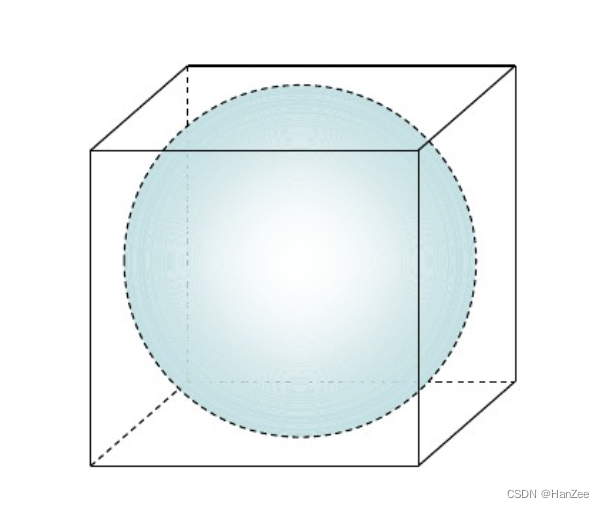
假设有一个正方形,边长为1,那么面积为1 * 1。
正方形的内接圆的边长为0.5,面积为: pai * r *r。
假设一个正方体,边长为1,那么它的体积为 1 * 1 * 1。
正方体的内接球的半径为 3/4 * pai * r * r * r
按照这个规律,我们把维度拓展的 正方形为2维,正方体为3维,按照这个规律,我们把维度拓展到 n维。
此时 n维度 几何体的体积 就是n个1相乘,结果还是1.
然后 n维度 几何球体的体积就截然不同,设常数为K,体积则是:
K
∗
r
n
K*r^n
K∗rn
因为r是小1的,所以几何球体当维度拓展到n维后,它的体积会逐渐趋近于0.
在这里我们来讨论一下如何理解体积,假设我们一个球体的体积=5,它们的总质量m是不会随着维度的升高而变化的,我们就说这个球体每单位体积中有5个数据。
当维度升高时,r=0.5,所以当维度达到足够高时,内接球体的体积会接近于0,也就是说球体的没单位体积内机会就没有数据,然而外接正方体的体积始终=1,也就是球内的数据随着维度的增加没有消失,都聚集在正方体的表面。这个定理源于各点距单位球中心距离的中间值计算公式:
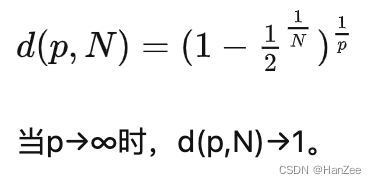
这种情况下,一些度量相异性的距离指标(如:欧式距离)效果会大大折扣,从而导致一些基于这些指标的分类器在高维度的时候表现不好。
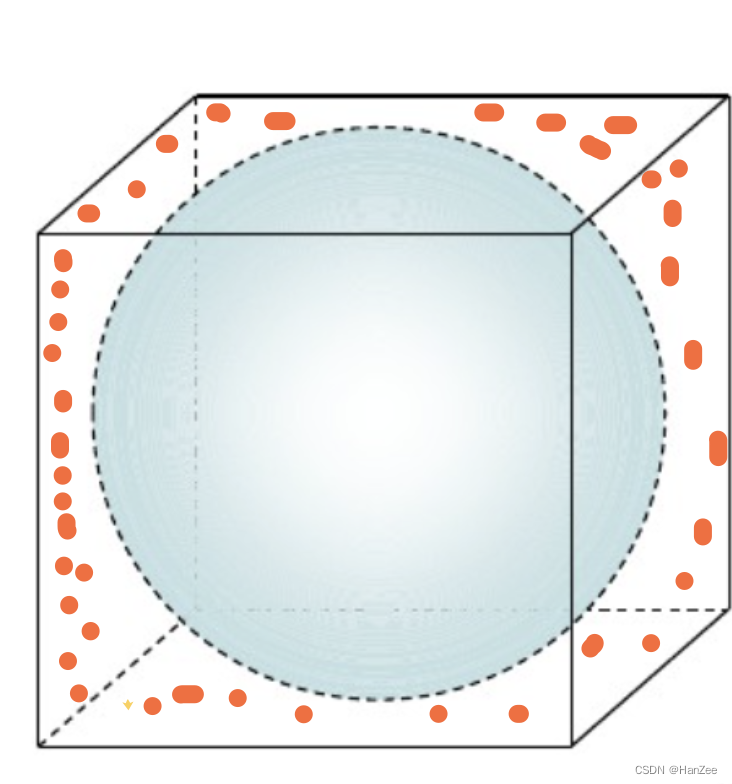
在此时,我们计算每个点
补充说明 (r 如果大于1)
我们在很多文章中可能都会看到这个例子,但是你有没有思考过,如果r>1,那么无论他的体积增大多少维度,他也不会缩小了,上面的那个理论不久作废了吗?
这里我给出两个解释:
- 我们平时做machine learning 项目的时候,一般数据都是会做归一化的,所以会控制在1以内。
- 假设r=2,那么正方体边长就是4,我们把维度升高的10维,高纬正方体的体积就是10个4相乘=4194304,而内接球体则是一个常数K乘10个2相乘,也就是2048 * K,它们在3维的体积相差不大,随着维度的升高,它们差距在不断增大,也可近似相对认为几何球体内没有数据。
维度灾难于过拟合的关系
假设在地球上有无数只猫和狗,但由于种种原因,我们总共只有10张描述猫狗的图片。我们的最终目的是利用这10张图片训练出一个很牛的分类器,它能准确的识别我们没见过的各种无数的猫、狗。
我们首先用一维特征(比如体重):
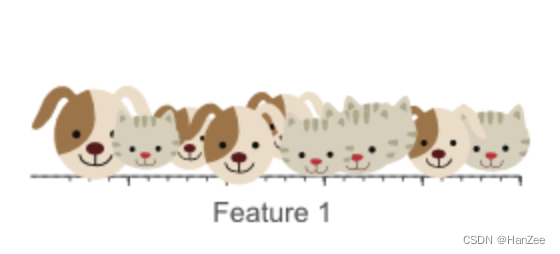
从图中我们可以在坐标轴中找到一个点来作为分类的基准点,左边是狗,右边是猫。但是我们发现这样的分类效果并不好,于是我们在增加1个特征(身高):
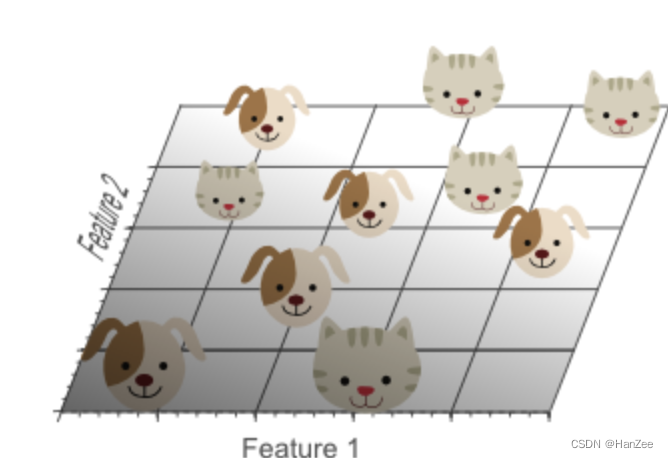
在这里我们也并不能找到一个很好的分隔线把他们分开,于是把特征拓展到三维:
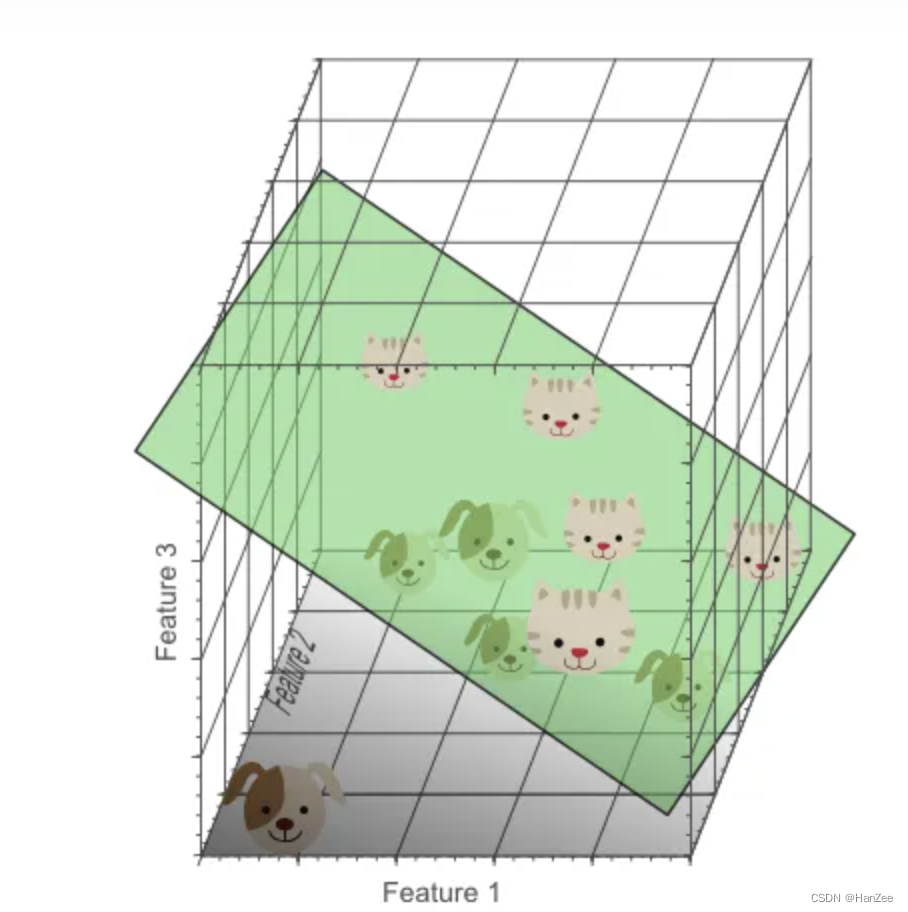
到了现在,就可以找到一个很好的平面把他们分开。
那么是不是我们就可以按照这个规律不断提升特征的维度呢,分类的效果就会越来越好呢?
结果显然是不可行的,在维度提升的同时,很容易就可以找到一个看似完美的超平面来分割数据:
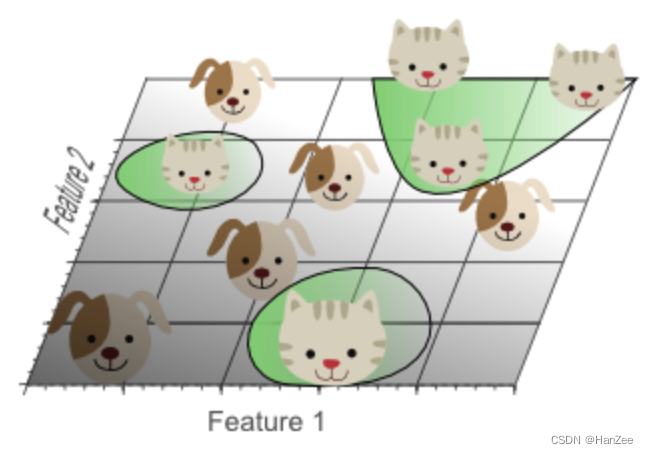
但是数据量要随着维度的增加而增加,数据本身就是有噪声的,在数据不足的时候,结果就是分类器学习到了很多数据集中的特例,因此对于现实数据往往会效果较差,因为现实数据是没有这些噪声以及异常特性的。就像上图,把分类结果映射到底维,这种现象也就是我们熟知的过拟合。
缓解方法
- 增加数据
- L1\L2正则
- DropOut
- 降维



















 495
495

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











