






 Prefix-Tuning是一种轻量级替代Fine-tuning的方法,用于优化预训练大模型在NLG任务中的性能。通过使用连续的字符序列替换离散的prompt,该方法仅微调前缀参数,降低了大规模模型的调整成本。实验表明,直接优化前缀参数可能不稳定,因此引入了MLP层来提高训练稳定性。
Prefix-Tuning是一种轻量级替代Fine-tuning的方法,用于优化预训练大模型在NLG任务中的性能。通过使用连续的字符序列替换离散的prompt,该方法仅微调前缀参数,降低了大规模模型的调整成本。实验表明,直接优化前缀参数可能不稳定,因此引入了MLP层来提高训练稳定性。
Prefix-Tuning: Optimizing Continuous Prompts for Generation思路总结
Introduction
在当时Fine-tuning 是预训练大模型在下游任务的主要方法。在千亿级别的参数背景下,针对不同的下游任务,需要加载不同的权重并且在训练的时候需要重新设计优化目标等等步骤,这是非常不经济的,所以作者提出了Prefix- tuning,一个适用于NLG的轻量化可以替换Fine-tuning的方法。
Prefix-Tuning
Intuition
受到prompting的启发,我们像生成一个词,我们可以找到一个合适的上下文,LM为我们生成期望最高的下一个词(也可以采用束搜索),这种方法有时候会成功,有时候会失败。
直观的理解,我加prompt实际上我就是在改装输入x,期望可以指导它抽取我们想要的特征,然后影响encoder,最后影响结果y。
但是作者认为prompt它是一个离散的值,它可能不是一个明显的instructions,于是作者的方法是用一个连续的字符来替换之前的离散的instruction,这可能更具有表现力。
这方法类似于lora,在特定的任务上,我只需要选择不同训练好的prefix。
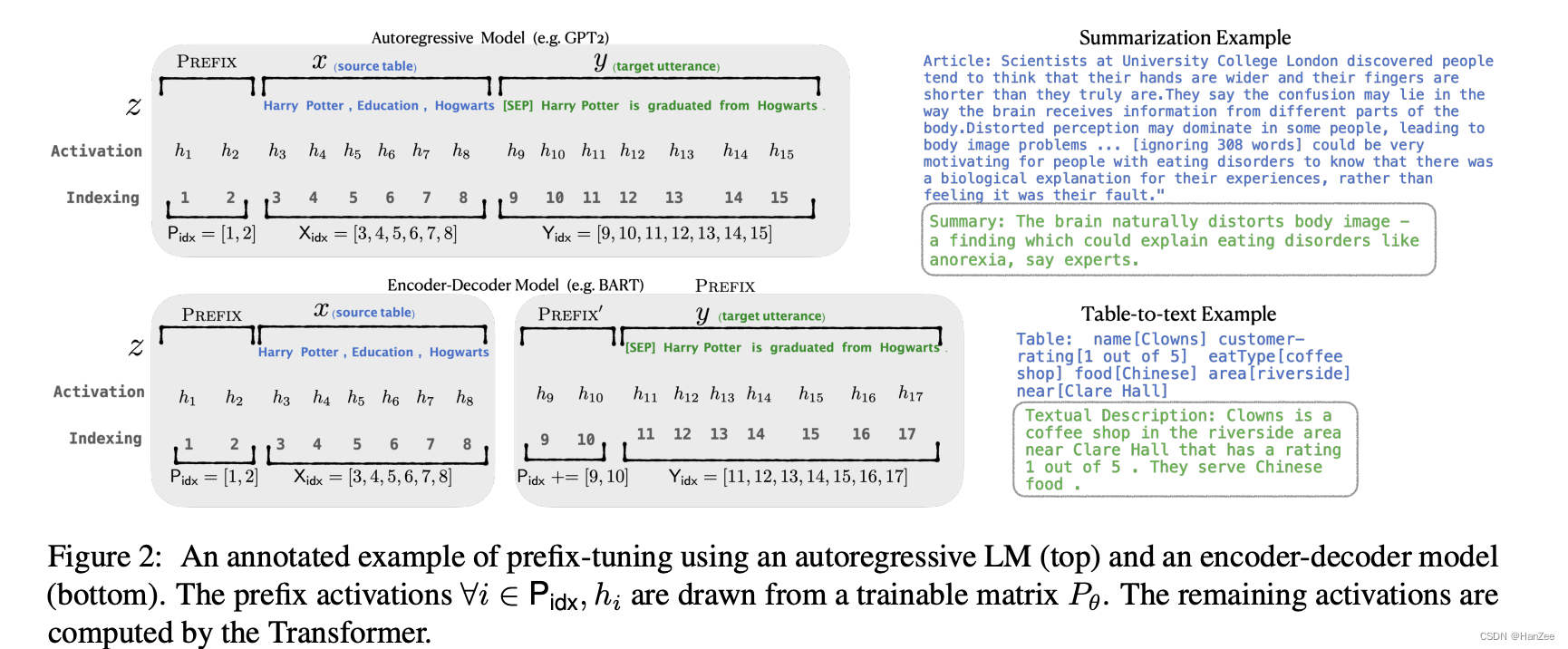
Method
这里分为Decoder-only 和 Encoder- Decoder两种情况:
第一种为:
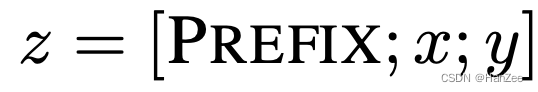
第二种为:
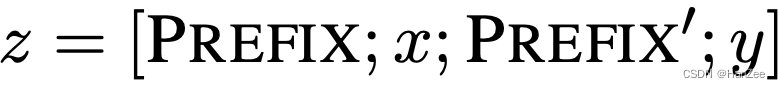
其中 P_idx表示prefix的索引,|P_idx|表示 prefix的长度,在微调的时候,冻结LM的参数,只微调prefix,它是一个可学习的矩阵P_theta,维度为|P_idx|*dim(hi),hi的选择为:
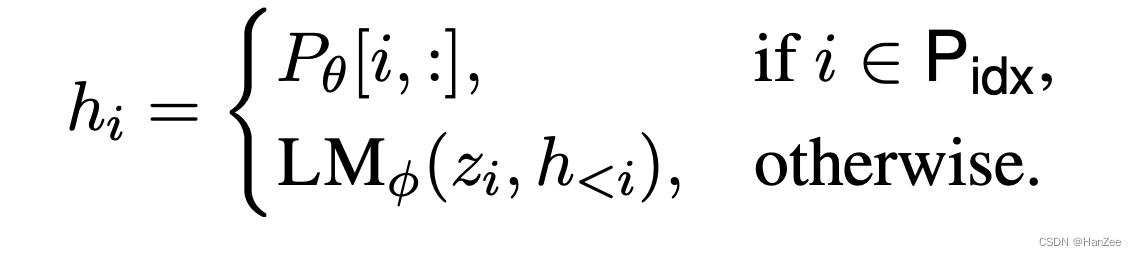
Parametrization of P_theta
通过实验作者发现直接优化P_theta训练不稳定,甚至有轻微的性能下降,于是作者套了一层MLP。
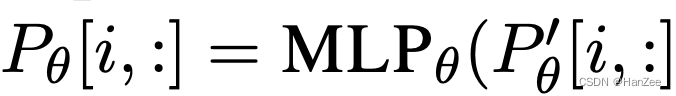
P_theta和P_theta’ 具有相同的行(即前缀长度),但不同的列。一旦训练完成,可以删除这些重处理参数MLP_theta和P_theta’,并且只需要保存前缀参数P _theta。
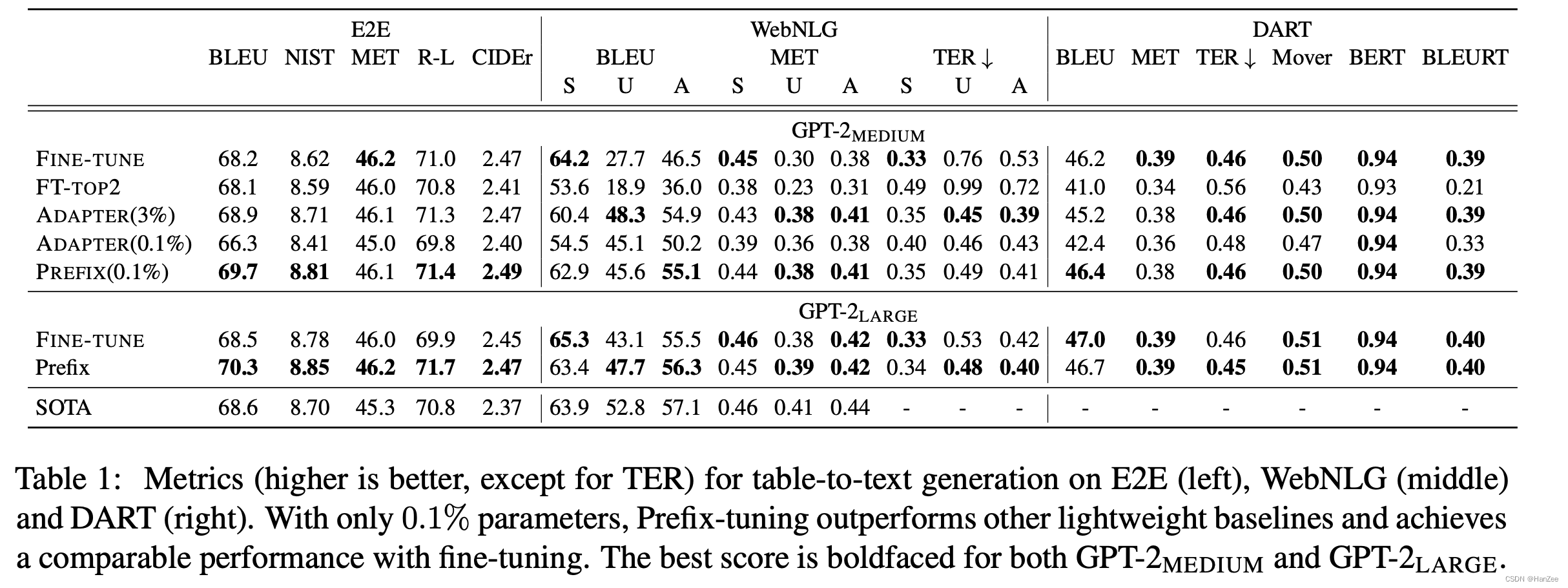
实验
参考
https://arxiv.org/pdf/2101.00190.pdf



















 779
779

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











