








 Prefix-Tuning是一种微调方法,只需极少量参数就能达到全量微调的性能,适用于大模型如GPT-2。它通过优化连续的前缀向量,减少了对模型原有参数的修改,支持多任务和低资源场景,并且在实验中表现出与全量微调相当甚至更好的效果。
Prefix-Tuning是一种微调方法,只需极少量参数就能达到全量微调的性能,适用于大模型如GPT-2。它通过优化连续的前缀向量,减少了对模型原有参数的修改,支持多任务和低资源场景,并且在实验中表现出与全量微调相当甚至更好的效果。
Prefix-Tuning: Optimizing Continuous Prompts for Generation
前言
LLM参数有效性学习的三驾马车之一(另外两个分别是LoRA和Adapter),来自ACL 2021的prefix-tuning,受到prompt的启发,提出了一种新颖的微调范式,仅需极少的参数就能达到全量微调的性能,文章通俗易懂,但是其背后的原理才是最值得深究的地方~
Paper: https://arxiv.org/pdf/2101.00190.pdf
Code: https://github.com/XiangLi1999/PrefixTuning
Abstract
完整微调需要存储所有的参数,本文提出prefix-tuning,可以冻结语言模型参数,优化一系列连续的特定任务的向量,称为prefix。实验部分对GPT-2进行微调,仅修改0.1%的参数,就得到了可比较的性能,并且在低资源场景优于全量微调。
1. Introduction
全量微调成本高昂,比如GPT-2有774M个参数,GPT-3有175B个参数。
一个自然的解决方法是轻量级微调,即冻结大部分参数,只调整较小部分参数。如Adapter-tuning在模型层中间插入任务特定的层,在仅添加2—4%的参数就得到可比的性能。
对于大语言模型如GPT-3,可以采用上下文学习,不需要改变任何参数,但是受限于输入长度的限制,只适合小的训练集。

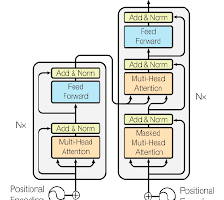
prefix-tuning将一系列连续的特定于任务的向量添加到输入中,如上图下面部分所示。这些前缀向量并不能够映射到真正的实体token,可以理解为“虚拟token”。微调过程只更新添加的前缀向量,从而减少开销。
与全量微调不同,prefix-tuning是模块化的,可以通过训练一个上游的前缀指导未修改的模型,这样一个LLM可以支持多任务。此外,这种架构可以支持一个batch中处理多用户/任务的请求。
实验部分,prefix-tuning几乎达到全量微调的效果,在低资源场景下,更是优于全量微调。
2. Related Work
2.1 Fine-tuning for natural language generation
微调已经成为自然语言生成领域训练模型的一种普遍范式。
2.2 Lightweight fine-tuning
轻量级微调方法核心思想是冻结大部分参数,只训练少量参数以尽可能达到原来效果。方法包括研究特定任务的参数掩码,插入可训练参数的模块,如adapter,但是本文的方法比该方法在参数上进一步减少了30倍。
2.3 Prompting
常见的prompt是通过手动设计提示的方式调整模型生成。但是本文的prompt为连续前缀,更具有表现力,可以优化任务特定的prefix。
2.4 Controllable generation
可控生成旨在引导预训练的语言模型匹配句子级属性,控制过程可以在训练时或者解码时进行,但是没有直接的方法对生成的内容实施细粒度的控制,如表格到文本、摘要任务等。
2.5 P*-tuning
所有P-tuning都是基于优化连续的prefix或者prompt的思想。调整软提示优于先前对离散提示优化的工作。Prompt-tuning的工作表明全量微调和P*-tuning之间的性能差距随着模型的大小增大而消失。
3. Problem Statement

考虑文本生成的场景,输入是文本,输出是token序列,如上图右边的文本摘要任务。
3.1 Autoregressive LM
自回归模型如上图顶部所示,
z
=
[
x
;
y
]
z=[x;y]
z=[x;y]是输入和输出concatenation的结果,时间步
i
i
i的激活向量为
h
i
∈
R
d
h_i \in \mathbb{R}^d
hi∈Rd,其中
h
i
=
[
h
i
(
1
)
;
.
.
.
;
h
i
(
n
)
]
h_i = [h_i^{(1)};...;h_i^{(n)}]
hi=[hi(1);...;hi(n)]是当前时间步所有激活层的concatenation结果。
h
i
h_i
hi的计算如下:
h
i
=
L
M
ϕ
(
z
i
,
h
<
i
)
h_i=\mathrm{LM}_{\phi}(z_i,h_{<i})
hi=LMϕ(zi,h<i)
h
i
h_i
hi的最后一层用于下一个token的分布
p
ϕ
(
z
i
+
1
∣
h
≤
i
)
=
s
o
f
t
m
a
x
(
W
ϕ
h
i
(
n
)
)
p_{\phi}(z_{i+1}|h_{\le i} )=\mathrm{softmax}(W_{\phi}h_i^{(n)})
pϕ(zi+1∣h≤i)=softmax(Wϕhi(n))。
3.2 Encoder-Decoder Architecture
此外也可以采用encoder-decoder架构的模型如BART,输入通过encoder进行编码,输出通过decoder自回归预测,如上图的下面部分所示。
3.3 Fine-tuning
全量微调更新目标如下:
max
ϕ
log
p
ϕ
(
y
∣
x
)
=
max
ϕ
∑
i
∈
Y
i
d
x
log
p
ϕ
(
z
i
∣
h
<
i
)
\max _{\phi} \log p_{\phi}(y \mid x)=\max _{\phi} \sum_{i \in Y_{\mathrm{idx}}} \log p_{\phi}\left(z_{i} \mid h_{<i}\right)
ϕmaxlogpϕ(y∣x)=ϕmaxi∈Yidx∑logpϕ(zi∣h<i)
4. Prefix-Tuning
4.1 Intuition
上下文可以引导模型生成想要的内容,但是离散的自然语言在计算上具有挑战性。因此可以考虑优化连续的词embedding,这比受限的离散的prompt更具有表现性,此外,prefix-tuning可以直接修改网络更深处的表示,从而避免跨网络深度的长计算路径(因为每一层都有)。
4.2 Method
对于自回归模型,调整
z
=
[
P
R
E
F
I
X
;
x
;
y
]
z=[\rm{PREFIX};x;y]
z=[PREFIX;x;y],对于encoder-decoder架构,调整为
z
=
[
P
R
E
F
I
X
;
x
;
P
R
E
F
I
X
′
;
y
]
z=[\rm{PREFIX};x;\rm{PREFIX}';y]
z=[PREFIX;x;PREFIX′;y],如上图所示。
P
i
d
x
\rm{P_{idx}}
Pidx表示前缀prefix的下标,此时
h
i
h_i
hi的计算如下:
h
i
=
{
P
θ
[
i
,
:
]
,
if
i
∈
P
i
d
x
L
M
ϕ
(
z
i
,
h
<
i
)
,
otherwise
h_{i}=\left\{\begin{array}{ll} P_{\theta}[i,:], & \text { if } i \in \mathrm{P}_{\mathrm{idx}} \\ \mathrm{LM}_{\phi}\left(z_{i}, h_{<i}\right), & \text { otherwise } \end{array}\right.
hi={Pθ[i,:],LMϕ(zi,h<i), if i∈Pidx otherwise
微调时,只对前缀参数进行梯度更新。
4.3 Parametrization of P θ P_{\theta} Pθ
直接更新 P θ P_{\theta} Pθ会导致优化不稳定,降低性能。因此通过一个大型的前缀神经网络 M L P θ \rm MLP_{\theta} MLPθ组成的较小矩阵 P θ ′ P_{\theta}' Pθ′重新参数化矩阵 P θ [ i , : ] = M L P θ ( P θ ′ [ i , : ] ) P_{\theta}[i,:]=\mathrm{MLP}_{\theta}(P_{\theta}'[i,:]) Pθ[i,:]=MLPθ(Pθ′[i,:])。这样可训练参数就变为了 P θ ′ P_{\theta}' Pθ′和 M L P θ \mathrm{MLP}_{\theta} MLPθ。训练结束后只保存前缀参数 P θ P_{\theta} Pθ。
5. Experimental Setup
5.1 Datasets and Metrics
作者在三个数据集上评估表格到文本的任务,在XSUM数据集上评估摘要任务,如下表所示:

5.2 Methods
对于表格到文本生成任务,作者对比了全量微调、FT-top2和adapter-tuning三种方法。此外对于每个数据集的SOTA方法也进行了对比。
5.3 Architectures and Hyperparameters
表格到文本生成任务上,作者采用
G
P
T
−
2
M
E
D
I
U
M
\mathrm{GPT-2_{MEDIUM}}
GPT−2MEDIUM和
G
P
T
−
2
L
A
R
G
E
\mathrm{GPT-2_{LARGE}}
GPT−2LARGE模型,对于文本摘要任务,采用
B
A
R
T
L
A
R
G
E
\mathrm{BART_{LARGE}}
BARTLARGE模型。
超参数的设置详见附录。训练中,无论时间还是空间效率,Prefix-tuning都要略胜一筹。
6. Main Results
6.1 Table-to-text Generation
实验发现仅仅更新0.1%的任务特定参数,就能够超越其它轻量级baseline,达到与全量微调可比的性能。

当把可训练参数都调整为0.1%时,可以发现prefix-tuning明显优于ADAPTER。此外,在DART上获得良好的性能表明prefix-tuning可以推广到不同领域的大量关系表中。
总的来说,prefix-tuning应用到自回归模型上,高效且节约时间,并且随着模型规模的夸大,性能仍能提升,说明其有潜力扩展到更大的模型。
6.2 Summarization

摘要任务结果如上表所示,prefix-tuning和全量微调还是有差距,这与文本生成任务的结果有所不同,有如下几点原因:
- XSUM数据集是三个table-to-text数据集的三倍。
- 输入的文章比table-to-text的输入长17倍。
- 摘要任务更复杂,因为需要从文本中挑选关键内容。
6.3 Low-data Setting
为了更系统探索低资源场景设置,作者的对数据集进行了二次采样,获得大小为50、100、200、500的数据,每组数据都采样五种不同的数据集。

上图右边可以看出低资源场景下prefix-tuning的性能优于全量微调,但是随着数据集增加差距会减小。
6.4 Extrapolation
这里探索泛化性能,即在未见的主题上的表现能力。作者对数据集进行了重新划分,使部分类别仅在测试时出现。table-to-text数据集分割WebNLG,摘要任务将数据集分为新闻-to-体育(新闻上训练,体育上测试),以及新闻内数据(部分领域上训练,其它领域上测试)。

结果见6.1表中间U部分和上表,prefix-tuning性能都比全量微调要好。
7. Intrinsic Evaluation
7.1 Prefix Length
较长的前缀表明可训练参数的增加,性能会随着提升。

不同任务前缀长度阈值不同,超过阈值容易过拟合。
7.2 Full vs Embedding-only

根据上表可以看出,仅微调embedding的表现力不够,但也优于离散提示优化,模型表达能力有着如下的规律:离散提示<embedding-only<prefix-tuning。
这里的full意思是指在模型的每一层前面都添加前缀,而embedding-only仅在输入embedding前加入prefix,这样的表现力是不够的。
7.3 Prefix-tuning vs Infix-tuning
此外,作者还研究了可训练的参数在序列中位置的影响。上表下面部分是Infix的结果,性能略低于prefix-tuning,可能原因是前者只能影响y,而后者可以影响x和y。
7.4 Initialization

随机初始化在低资源场景对结果有很大影响,性能低、方差大,使用真实单词初始化(特别是任务相关)可以调高生成速度。在完整训练场景下,初始化没有影响。
7.5 Data Efficiency
此外作者还比较了不同的数据规模下,prefix-tuning和全量微调的比较。

超过20%数据上,prefix-tuning比全量微调要好,10%的数据规模,随机初始化的prefix-tuning和全量微调效果类似,因此需要初始化技巧来提高性能。
8. Discussion
Personalization
当大量任务需要独立训练,又面临用户隐私问题时,可以采用prefix-tuning这种模块化方式,通过添加或删除用户的prefix来灵活添加、删除用户。
Batching across users
在相同的个性化设置下,prefix-tuning允许批量处理用户的请求,即在用户输入前面加上个性化前缀,从而提高效率。
Inductive bias of prefix-tuning
保留LM参数有助于泛化到未见过的领域,但是如何进一步改进是一个问题。prefix-tuning和adapter都保留了LM的完整,影响Transformer的激活层。但是前者只需要更少的参数就可以保持可比的性能,作者认为前缀调整尽可能保持预训练的LM完整。
阅读总结
作为LLM参数有效性学习的经典文章,prefix-tuning思路清晰,方法简单,效果惊人。作者借鉴prompt的思想,在模型的每一层前面加上可训练的前缀参数,并在训练中冻结其它参数,这种每一层都加上前缀的方式,恰如每一层都对后面的序列进行指令微调,层层递进,因此效果显著。实验部分通过两个场景的任务,先是和全量微调、adapter进行对比,再比较prefix的位置,prefix的长度,低资源场景设置,但是实验往往追求广而深,作者深度显然是够了,但是不够广,作者只在两个NLP任务、4个数据集上进行实验,要是能够在更多任务上进行对比,那么就更具有说服力了。此外,作者忽略了加入prefix,token序列长度进一步被压缩的限制。最后还有一点我个人的想法,如果能够将prefix调整的过程可视化,观察prefix究竟是怎样的变化过程,以及到底有多少参数是真正参与到微调的过程,那么就能够知道prefix最合适的长度范围了,当然这也是任务相关的。



















 783
783

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











