










最近我们被客户要求撰写关于量化交易的研究报告,包括一些图形和统计输出。
机器学习算法可用于找到最佳值来交易您的指标。
【视频】支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
支持向量机SVM、支持向量回归SVR和R语言网格搜索超参数优化实例
,时长07:24
相对强弱指标(RSI)是最常见的技术指标之一。它用于识别超卖和超买情况。传统上,交易者希望RSI值超过70代表超买市场状况,而低于30则代表超卖市场状况。但是,这些主张是否有效?为什么70,为什么30?此外,不同的趋势市场如何影响RSI信号?
在本文中,我们将使用一种功能强大的机器学习算法-支持向量机(SVM),在考虑到市场整体趋势的同时,探索您实际需要的RSI值。
首先,我们将简要概述SVM,然后根据算法发现的模式来构建和测试策略。
支持向量机
支持向量机基于其发现非线性模式的能力,是较流行且功能强大的机器学习算法之一。SVM通过找到一条称为“决策边界”或“超平面”的线来工作,该线可以根据类别(在我们的情况下为“看涨”或“看跌”)最好地分离数据。SVM的强大功能是可以使用一组称为“核”的数学函数将数据重新排列或映射到多维特征空间,在该空间中数据可以线性分离。
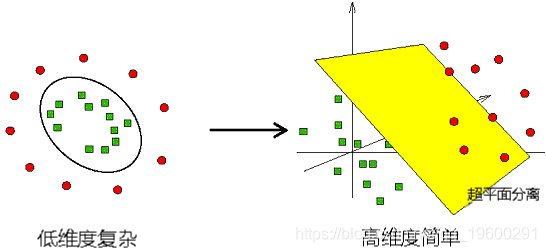
然后,SVM在较高维度的空间中绘制一条线,以最大化两个类之间的距离。将新的数据点提供给SVM后,它会计算该点落在线的哪一边并进行预测。
SVM的另一个优点是,在可以使用它之前,必须选择的参数相对较少。首先,您必须选择用于将数据转换到更高维度空间的核或映射功能。径向基函数是一种流行的选择。接下来,您需要选择gamma参数。gamma确定单个训练示例可以对决策边界产生多少影响。较低的值表示单个点将对画线的位置产生较大的影响,而较高的值表示每个点将仅对较小的影响。将gamma参数选择为模型输入数量(1 /(输入数量))是一个经验法则。最后,您需要选择正则化参数C。C确定了训练集中分类错误的示例与决策边界的简单性之间的权衡。低C会创建更平滑的决策边界并减少过度拟合,而高C会尝试正确分类训练集中的每个数据点,并可能导致过度拟合。我们希望减少模型的过拟合量,因此我们将选择一个值1。
现在,我们对支持向量机的工作原理以及如何选择其参数有了基本的了解,让我们看看是否可以使用它来计算如何交易RSI。
交易RSI
相对强弱指标(RSI)将“上涨”移动的平均大小与“下跌”移动的平均大小进行比较,并将其归一化为0到100。传统的逻辑是,一旦股价有更多的,显着的上升趋势,它已经变得超买或被高估,并且价格可能会下降。超买通常由RSI值超过70来确定,相反的情况表示RSI值为30时出现超卖或低估。
在强劲的上升趋势中,RSI值超过70可能表示趋势的延续,而在下降趋势期间的RSI值70可能意味着一个很好的切入点。问题是要找出要考虑这两个因素的确切条件。
我们可以收集成千上万个数据点,然后尝试自己找到这些关系,也可以使用支持向量机为我们完成工作。
让我们看看我们可以使用AUD / USD 每小时数据将开盘价与50期简单移动平均线(SMA)比较,从而在3期RSI中找到模式并定义趋势。
加载历史价格。
#*****************************************************************
# 载入历史数据
#******************************************************************
AUDUSD = read.xts('AUDUSD.csv', format='%m/%d/%y %H:%M', index.class = c("POSIXlt", "POSIXt"))
建立模型
使用R建立我们的模型,分析它能够找到的模式,然后进行测试以查看这些模式在实际的交易策略中是否成立。
创建指标并训练SVM:
#*****************************************************************
# 代码策略
#******************************************************************
load.packages('e1071,ggplot2')
indicators = as.xts(list(
RSI3 = RSI(Cl(AUDUSD), 3),
SMA50 = SMA(Op(data$AUDUSD), 50)
# 删除缺失
DataSet = DataSet[-(1:49),]
#将数据分为60%的训练集以构建模型,20%的测试集以测试我们发现的模型,以及20%的验证集将我们的策略应用于新的数据
Training = DataSet[1:4528,]
#使用径向基函数作为核,将成本或C设置为1,构建支持向量机
svm(
data=Training,
kernel="radial",
cost=1,gamma=1/2)
#在训练集中再次运行算法以可视化找到的模型
predict(SVM,Training,type="class")
# 绘图
ggplot(TrainingData, aes(x=Trend,y=RSI3))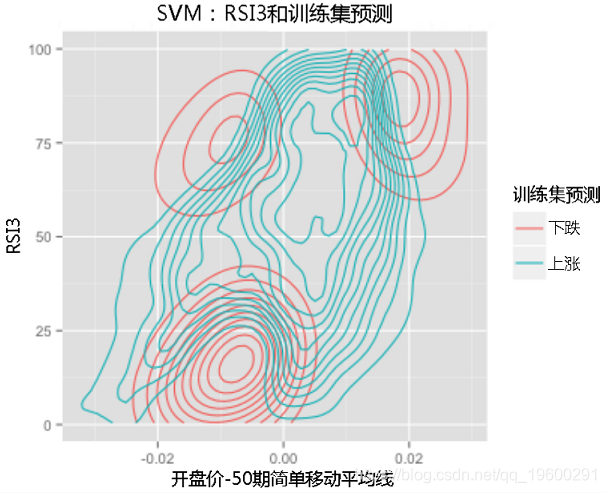
我们可以看到算法在三个不同的区域预测空头,而在中间的一个区域预测多头。
让我们进一步探索。
| 多头 | 空头 |
|---|---|
| RSI低于25,价格比SMA 50低20(准确度为56%,交易36次) | RSI小于25,且价格比SMA 50低10至5个点(准确度为54%,交易81次) |
| RSI3在50到75之间,价格比SMA 50高5到10个点之间(准确度为58%,交易104) | RSI大于70,价格比SMA 50低5个点以上(准确度为59%,交易37次) |
| RSI大于75,价格比SMA 50高出15个点(准确度为59%,交易34次) |
首先是左下角区域。在这里,价格刚刚跌破50期SMA,RSI跌破25,表明跌势突破。
但是,如果价格跌破50周期SMA下方20个点,而RSI仍低于25点,则该算法会发现有较强的信号可以转换为均值,并预测多头交易。
接下来,图左上方的短暂机会代表了RSI的传统观点。我们希望RSI超过70,而价格比50周期均线高出15点以上,以表示“超买”情况,这表明我们做空了。
左上方的区域有些不同。当价格刚刚跌破50期SMA以下且RSI超过70时,它发现了一个短暂的机会。这与第一种情况相似,但我们正在寻找看跌突破进入信号,而不是传统的“超买”条件。
最终,存在一个区域的RSI在50到75之间,而价格已经超过了50期均线,该算法发现了强烈的买入信号。
现在,我们找到了SVM发现的一组基本规则,让我们测试一下它们对新数据(测试集)的支持程度。
# 我们找到了SVM发现的一组基本规则,测试一下它们在新数据(测试集)的正确程度。
# 模式在测试集中的表现:
sum(ShortTrades$Direction == -1)/nrow(ShortTrades)*100
[1] 57.82313
sum(LongTrades$Direction ==1)/nrow(LongTrades)*100
[1] 57.14286
我们的空头交易为58%(147笔交易中的85笔正确),而我们的多头交易为57%(140笔交易中的80笔正确)。
使用支持向量机(一种功能强大的机器学习算法),我们不仅能够了解RSI的传统知识在什么条件下成立,而且还能够创建可靠的交易策略。
此过程称为从机器学习算法中得出规则,使您可以结合自己的交易经验来使用机器学习算法。



















 370
370

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









