






最近我们被客户要求撰写关于药品的研究报告,包括一些图形和统计输出。
数据无处不在。许多政府机构、金融机构、大学和社交媒体平台通过应用编程接口(API)提供对其数据的访问。API通常在一个JavaScript对象符号(JSON)文件中返回所请求的数据。在这篇文章中,我将向你展示如何使用Python通过API采集数据,以及如何处理产生的JSON数据。
采集API和JSON数据
API是一种软件应用程序,可以用来向另一个计算系统请求数据。有许多不同种类的API,而且每个API的语法往往是独特的。但一个典型的API是由一个URL和查询选项组成的。例如,下面的URL使用openFDA API从食品和药物管理局采集药物不良事件的数据。
https://api.fda.gov/drug/event.json?我们可以在API调用中添加选项来缩小数据请求的范围。例如,下面的URL要求从2018年1月1日至2018年1月5日在美国发生的涉及芬太尼的不良事件的数量。
我们可以在网络浏览器的地址栏中输入这个API调用的URL,浏览器会将结果数据显示为一个JSON文件。
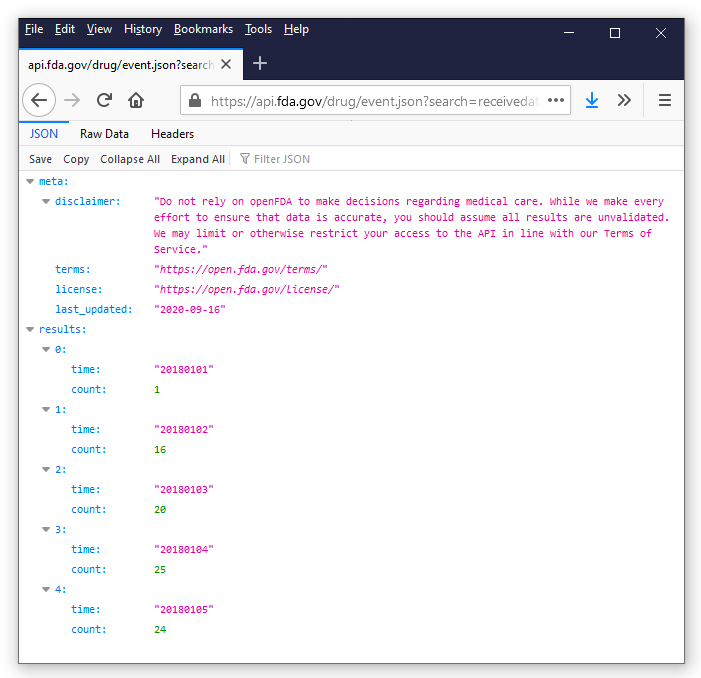
JSON数据通常是嵌套的。例如,time: "20180105 "被嵌套在4:键中。在上面的图片中,时间:键嵌套在4:键中,而4:键嵌套在结果:键中。在JSON嵌套结构的顶部有两个键:meta:和results:。
我们的目标是使用openFDA API来请求有关药物不良事件的数据,并将嵌套的JSON数据转换为Stata数据集。我们将使用request和pandas包,所以在开始之前你应该检查它们是否已经安装。
定义API调用的URL
让我们首先在Python代码块中定义一个名为URL的字符串。这个字符串URL包含使用openFDA API请求不良事件数据的URL。
python:
URL = 'https://api.fda.gov/drug/event.json'
URL
end上面代码块第三行中的语句URL显示了字符串URL的内容。
. python:
---------------------------------------- python (type end to exit) -------------
>>> URL = 'https://api.fda.gov/drug/event.json'
>>> URL
'https://api.fda.gov/drug/event.json'
>>> end
--------------------------------------------------------------------------------我们可以通过向我们的API调用添加搜索字段和值来定制我们的数据请求。你可以在openFDA网站上看到语法、可搜索字段的列表和例子。
让我们把搜索范围限制在2018年1月1日至2018年1月5日报告的不良事件,在下面的代码块中为我们的API调用添加?搜索选项。
这个语法是可行的,但是我们只添加了一个搜索字段,而且API调用的URL已经很难读懂。让我们把URL分成两个字符串。 API和日期。字符串API包含基本API调用的URL,字符串date将我们的搜索范围从2018年1月1日缩小到2018年1月5日。然后,我们可以通过输入URL = API + date来组合这些字符串。
我们的Python代码块更容易阅读,而且调用API的URL仍然是一样的。
让我们进一步将我们的查询限制在2018年1月1日至2018年1月5日发生在美国的不良事件。在下面的代码块中,字符串country包含语法,将我们的查询限制在美国。然后,我们可以将字符串API、日期和国家结合起来,指定存储在字符串URL中的完整API调用。注意,当我们定义URL时,我们必须在日期和国家之间加入 "+AND+"。
python:
API = 'https://api.fda.gov/drug/event.json?search='
date = 'receivedate:[20180101+TO+20180105]'
country = 'occurcountry:"US"'
URL = API + date + "+AND+" + country
URL
end即使我们的API调用的URL变得更加复杂,我们的代码易于阅读。
我们可以使用类似的策略,将我们的查询进一步限制在涉及药物芬太尼的不良事件上。下面代码块中的字符串drug包括指定不良事件涉及芬太尼的语法。
最后,让我们指定我们的结果包含每天发生的不良事件数量的数据。下面代码块中的字符串数据包含特定的语法,必须添加到API调用的URL的末尾。注意,字符串数据前面必须有&,而不是+AND+。
python:
API = 'https://api.fda.gov/drug/event.json?search='
date = 'receivedate:[20180101+TO+20180105]'
country = 'occurcountry:"US"'
drug = 'patient.drug.openfda.brand_name:"Fentanyl"'
data = 'count=receivedate'
URL = API + date + "+AND+" + country + "+AND+" + drug + "&" + data
URL
end我们的代码块仍然很容易阅读,尽管我们的API调用的URL已经变得相当复杂。
使用API调用请求数据
现在,我们已经准备好向openFDA数据服务器提交我们的API调用。让我们从导入 requests 包开始。我们可以使用get()方法来提交我们API调用的URL。然后,我们将把生成的JSON数据存储在一个名为data的字典对象中。
我们可以像上面的代码块那样通过输入data来查看数据对象的内容。下面输出中显示的数据难以阅读,因为它们没有经过格式化显示。
我们可以使用json模块,以更可读的格式显示数据。让我们首先在下面的代码块中导入json模块。然后,我们可以使用dumps()方法对JSON数据进行编码。indent=4选项显示每一级嵌套的数据都有缩进。sort_keys=True选项对数据进行排序。print() 告诉 Python 显示 dumps() 方法的结果。
下面输出中的数据更容易阅读。我们现在可以看到,这些数据被嵌套在元键和结果键中。meta键包含一个免责声明,数据最后更新的日期,许可证的URL,以及使用条款。这是有用的信息,但我不想把它包括在我的数据集中。我只想使用存储在结果键中的数据。
将JSON数据转换为一个Stata数据集
我们可以使用get()方法来提取数据对象的结果部分,并将其放在一个名为fdadata的列表对象中。
python:
import requests
import json
API = 'https://api.fda.gov/drug/event.json?search='
date = 'receivedate:[20180101+TO+20180105]'
country = 'occurcountry:"US"'
drug = 'patient.drug.openfda.brand_name:"Fentanyl"'
data = 'count=receivedate'
URL = API + date + "+AND+" + country + "+AND+" + drug + "&" + data
data = requests.get(URL).json()
fdadata = data.get('results', [])
print(json.dumps(fdadata, indent=4, sort_keys=True))
end我们可以通过查看下面的输出来验证我们是否成功提取了数据。
. python:
-------------------------------------------- python (type end to exit) --------
>>> import requests
>>> import json
>>> API = 'https://api.fda.gov/drug/event.json?search='
>>> date = 'receivedate:[20180101+TO+20180105]'
>>> country = 'occurcountry:"US"'
>>> drug = 'patient.drug.openfda.brand_name:"Fentanyl"'
>>> data = 'count=receivedate'
>>> URL = API + date + "+AND+" + country + "+AND+" + drug + "&" + data
>>> data = requests.get(URL).json()
>>> fdadata = data.get('results', [])
>>> print(json.dumps(fdadata, indent=4, sort_keys=True))
[
{
"count": 1,
"time": "20180101"
},
{
"count": 16,
"time": "20180102"
},
{
"count": 20,
"time": "20180103"
},
{
"count": 25,
"time": "20180104"
},
{
"count": 24,
"time": "20180105"
}
]
>>> end
-------------------------------------------------------------------------------fdadata列表对象中的数据仍然是 "key:value "格式,我想把它们转换成pandas数据框的 "行和列 "格式。首先,让我们使用别名pd导入pandas模块。然后,我们可以使用read_json()方法将fdadata列表对象读取到一个名为fda_df的pandas数据框架中。
下面输出中显示的数据框fda_df包含五行三列。第一列是数据框的索引。第二列,名为 "时间",包含每个观察值的日期。第三列,名为 "计数",包含该日期在发生的涉及芬太尼的不良事件的数量。
. python:
-------------------------------------------- python (type end to exit) --------
>>> import requests
>>> import json
>>> import pandas as pd
>>> API = 'https://api.fda.gov/drug/event.json?search='
>>> date = 'receivedate:[20180101+TO+20180105]'
>>> country = 'occurcountry:"US"'
>>> drug = 'patient.drug.openfda.brand_name:"Fentanyl"'
>>> data = 'count=receivedate'
>>> URL = API + date + "+AND+" + country + "+AND+" + drug + "&" + data
>>> data = requests.get(URL).json()
>>> fdadata = data.get('results', [])
>>> fda_df = pd.read_json(json.dumps(fdadata))
>>> fda_df
time count
0 20180101 1
1 20180102 16
2 20180103 20
3 20180104 25
4 20180105 24
>>> end
-------------------------------------------------------------------------------现在,我们可以使用to_stata()方法将pandas数据框fda_df保存到一个名为fentanyl.dta的Stata数据集中。version=118选项指定数据将被存储在Stata 16数据文件中。
我们可以列出Stata数据文件fentanyl.dta的内容,以验证数据是否被正确保存。
. use fentanyl.dta, clear
. list
+--------------------------+
| index time count |
|--------------------------|
1. | 0 20180101 1 |
2. | 1 20180102 16 |
3. | 2 20180103 20 |
4. | 3 20180104 25 |
5. | 4 20180105 24 |
+--------------------------+在这一点上,我们很容易将API调用中的日期范围从2010年1月1日扩大到2020年1月1日,并将产生的数据绘制成图表(见下面的代码块)。
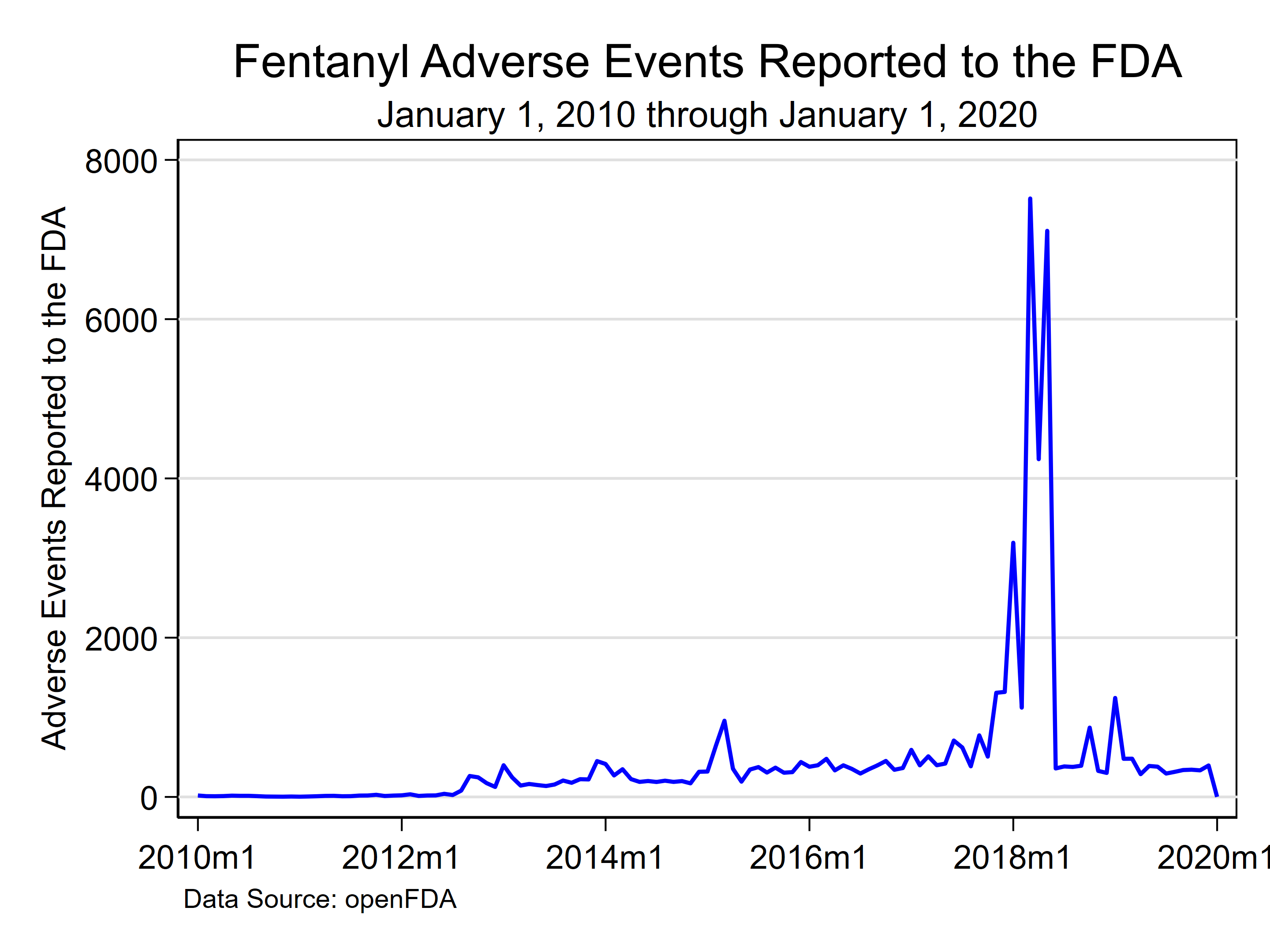
结论
我们成功了! 我们成功地向openFDA提交了一个API调用,处理了产生的JSON数据,并将JSON数据转换为Stata数据集。你可能对报告给FDA的药品不良事件不感兴趣。但你可以使用类似的步骤来下载和处理对你有用的各种数据。只要在你的搜索引擎中输入 "流行的api数据",就可以准备好大吃一惊。每个API都会有自己独特的搜索字段和语法,所以你需要阅读文档。但你的耐心和毅力将得到回报,因为你将看到一个充满数据的世界。


















 838
838

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









