






 本文通过同心圆和流动图可视化分析了2240个客户营销数据,探讨了客户投诉、教育背景、婚姻状况与促销活动接受度的关系。数据显示,未投诉的本科和恋爱/已婚客户更倾向于接受促销。最佳子集回归研究表明,有8个变量的模型具有最低预测误差,但BIC指标推荐7个变量的模型。最佳模型选择需要综合考虑调整后的R2和BIC。
本文通过同心圆和流动图可视化分析了2240个客户营销数据,探讨了客户投诉、教育背景、婚姻状况与促销活动接受度的关系。数据显示,未投诉的本科和恋爱/已婚客户更倾向于接受促销。最佳子集回归研究表明,有8个变量的模型具有最低预测误差,但BIC指标推荐7个变量的模型。最佳模型选择需要综合考虑调整后的R2和BIC。
最近我们被客户要求撰写关于营销活动可视化的研究报告,包括一些图形和统计输出。
哪种营销活动最成功?这家公司的普通客户是什么样的?营销活动没有预期的那么有效,如何分析数据了解此问题并提出数据驱动的解决方案?
”
要点提示
在竞争非常激烈的市场中,公司必须优化其潜在的可寻市场 (PAM)。使用市场细分,好处是更少花费资源(时间和金钱)。让公司通过了解他们的需求和愿望并满足他们来定位最有可能变成真正客户的特定潜在客户。
市场细分可以帮助您定义和更好地了解您的目标受众和理想客户。如果您是营销人员,这可以让您为您的产品确定合适的市场,然后更有效地定位您的营销。同样,发布商可以使用市场细分以提供更有针对性的广告选项,并为不同的受众群体定制其内容。
本文分析了 2240 个观察(客户)的营销数据(查看文末了解数据获取方式),其中包含 28 个与营销数据相关的变量:客户资料、购买的产品、营销活动成功(或失败)、渠道表现等,以最佳子集回归筛选的形式运行统计测试来回答这些问题。
主题一
客户资料和促销活动效果的关系
我们通过同心圆,可视化投诉客户与客户个人情况的层次关系。每个圆环的大小代表其对内部父类别的贡献。围绕这个中心圆(客户是否投诉)设置一个同心环(客户是否在第一次推销时就接受促销商品),来查看该项目的分解情况。

图一
我们可以看到,此环已被分割以显示主要分类——投诉和未投诉。未投诉的客户占比99%,进一步在外圈细分未投诉客户,其中在第一次推销时接受促销商品的比例为6.5%。投诉的客户占比1%,其中在第一次推销时接受促销商品的比例为0%。
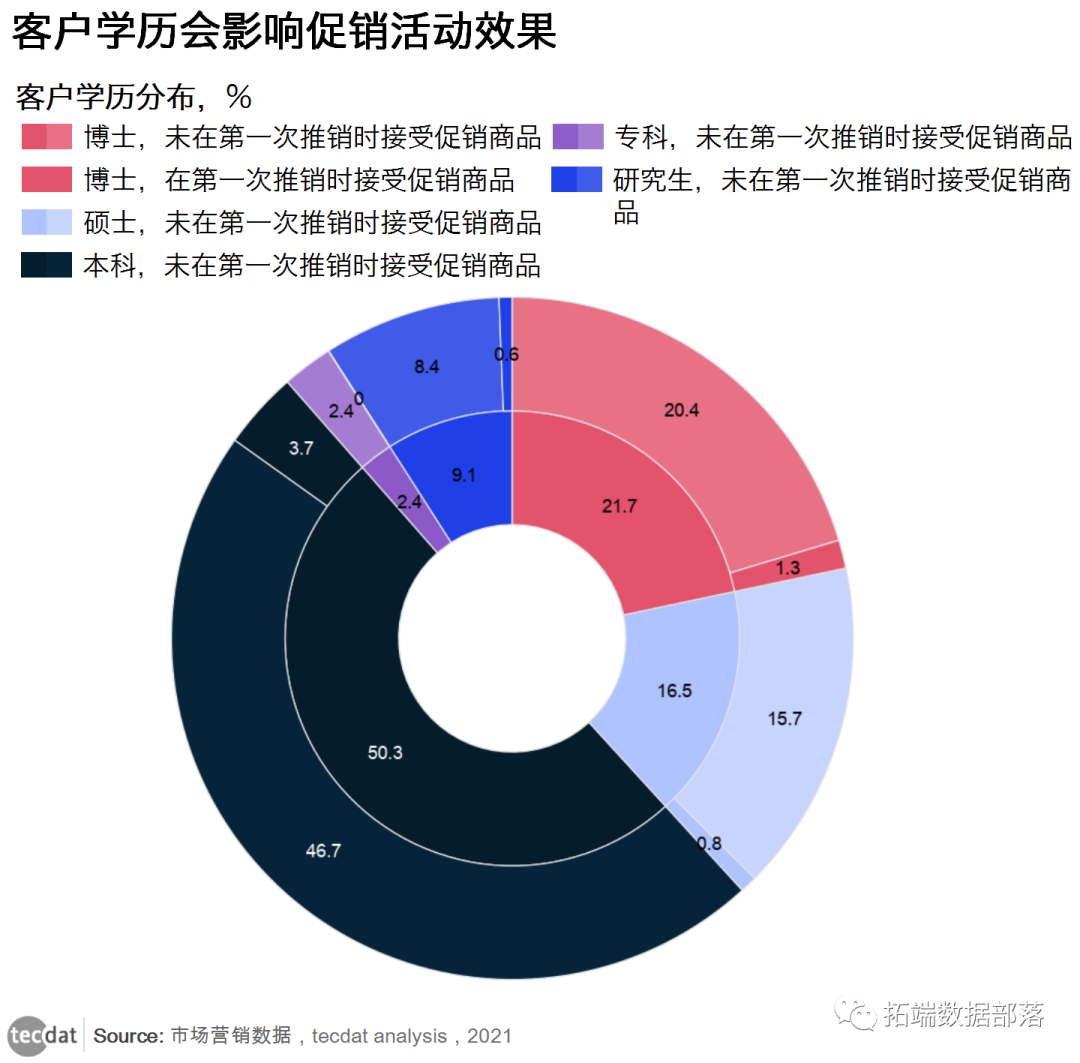
图二
本科的客户占比50.3%,其中在第一次推销时接受促销商品的比例为3.7%。博士的客户占比21.7%,其中在第一次推销时接受促销商品的比例为1.3%。硕士的客户占比16.5%,其中在第一次推销时接受促销商品的比例为0.8%。
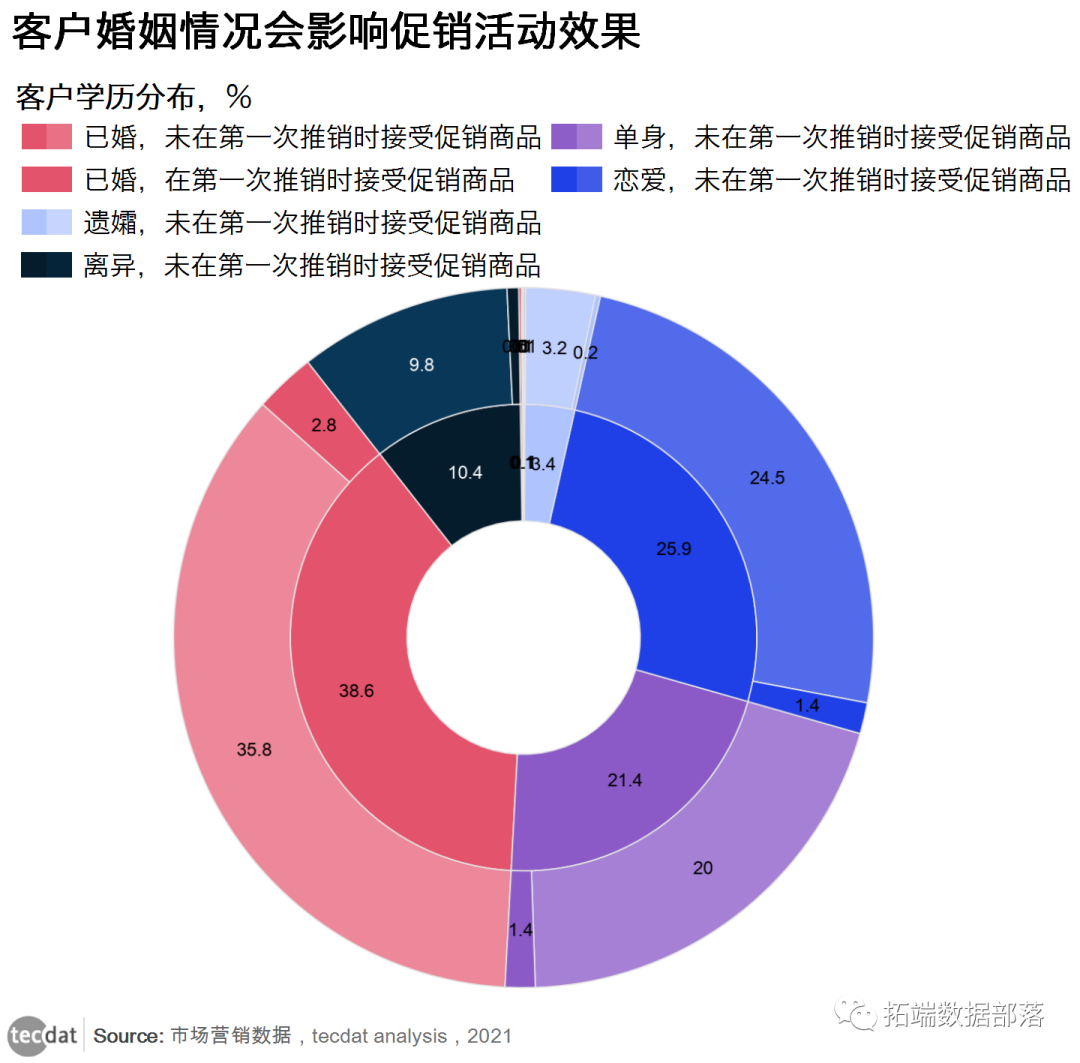
图三
可以看到,已婚的客户占比38.6%,其中在第一次推销时接受促销商品的比例为2.8%。恋爱中的客户占比25.9%,其中在第一次推销时接受促销商品的比例为1.4%。单身的客户占比21.4%,其中在第一次推销时接受促销商品的比例为1.4%。
主题二
客户婚姻学历情况与促销活动效果关系
我们对促销活动效果的分布可视化。构建促销活动效果流动图,对于每个维度(学历、婚姻和是否接受促销商品),每个类别都显示一个垂直条。条形的长度表示该类别的样本数。
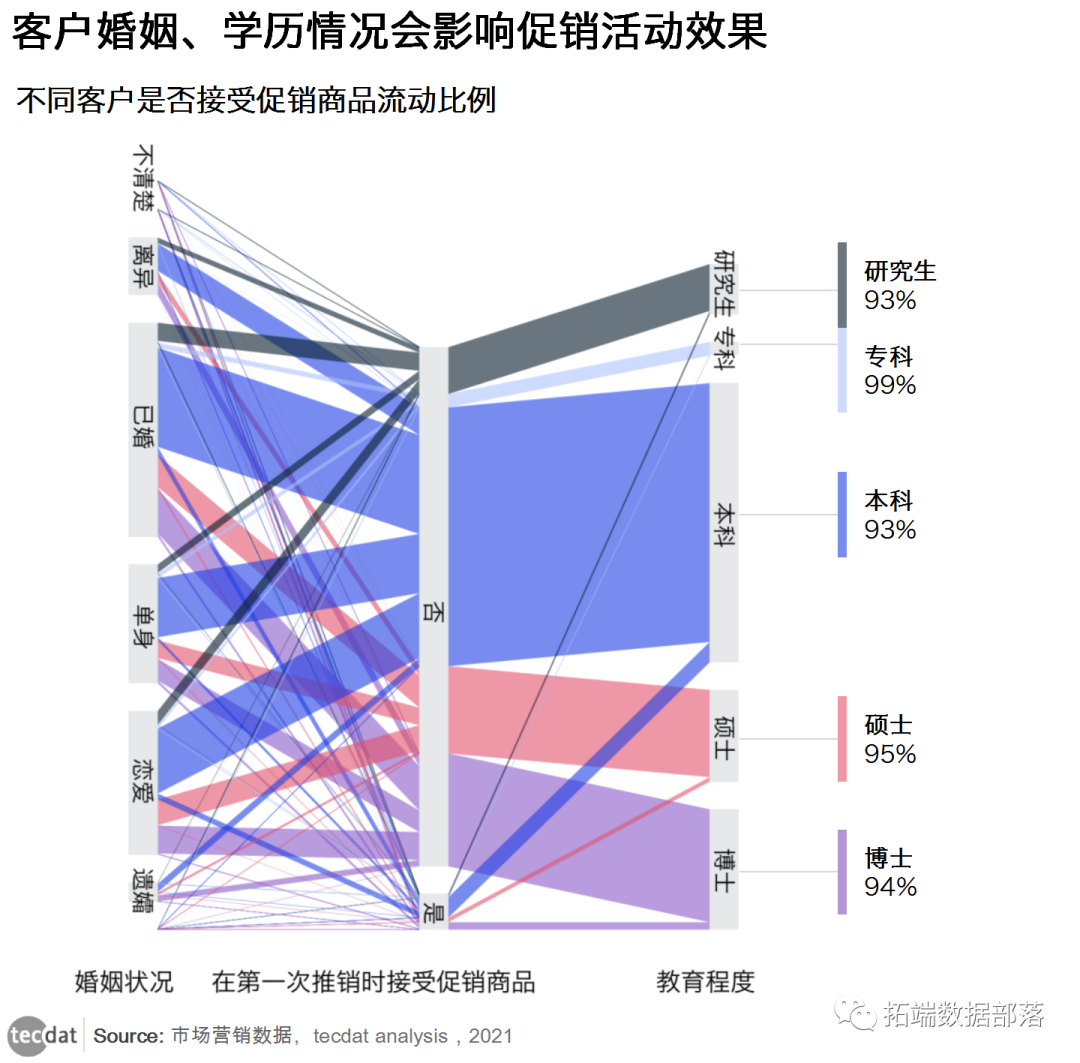
图四
从第一个维度(婚姻情况)开始,它的每个类别都连接到下一个维度中的多个类别,显示该类别是如何细分的。递归地重复这种细分,产生一棵树。
恋爱和已婚人士更容易接受促销商品?我们一眼就能看出,恋爱和已婚的相对比例远远大于单身或离异。我们还发现本科更容易接受促销商品,然后是博士学历客户,相对比例远远大于硕士研究生或专科。
主题三
最佳促销影响因素子集选择
一个自然的问题是:我们最终应该选择哪些最佳模型进行促销效果预测分析?
要回答这个问题,需要一些统计指标或策略来比较模型的整体性能并选择最好的。您需要估计每个模型的预测误差并选择预测误差较低的模型。
最佳子集回归是一个模型选择方法,其由测试所述预测变量的所有可能的组合,然后根据一些统计标准选择最佳模型。调整后的 R2、 BIC允许我们确定最佳的模型,其中最佳定义为最大化调整后的 R2 和最小化预测误差 BIC。
接下来,我们根据 R2和 BIC 统计值直接绘制估计模型,比较差异。
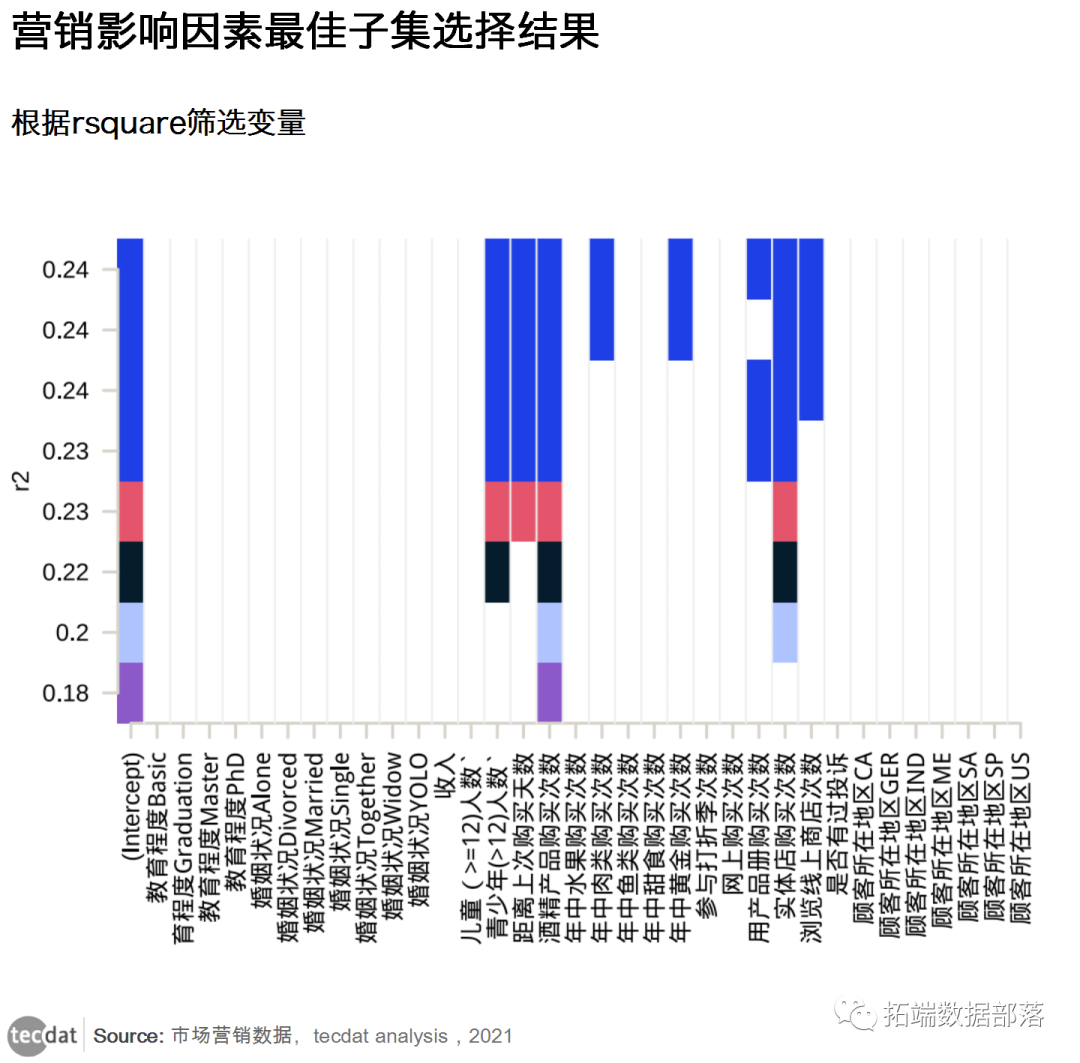
图五
调整后的 R2 表示结果中由预测变量值的变化解释的变化比例。调整后的 R2 越高,模型越好。
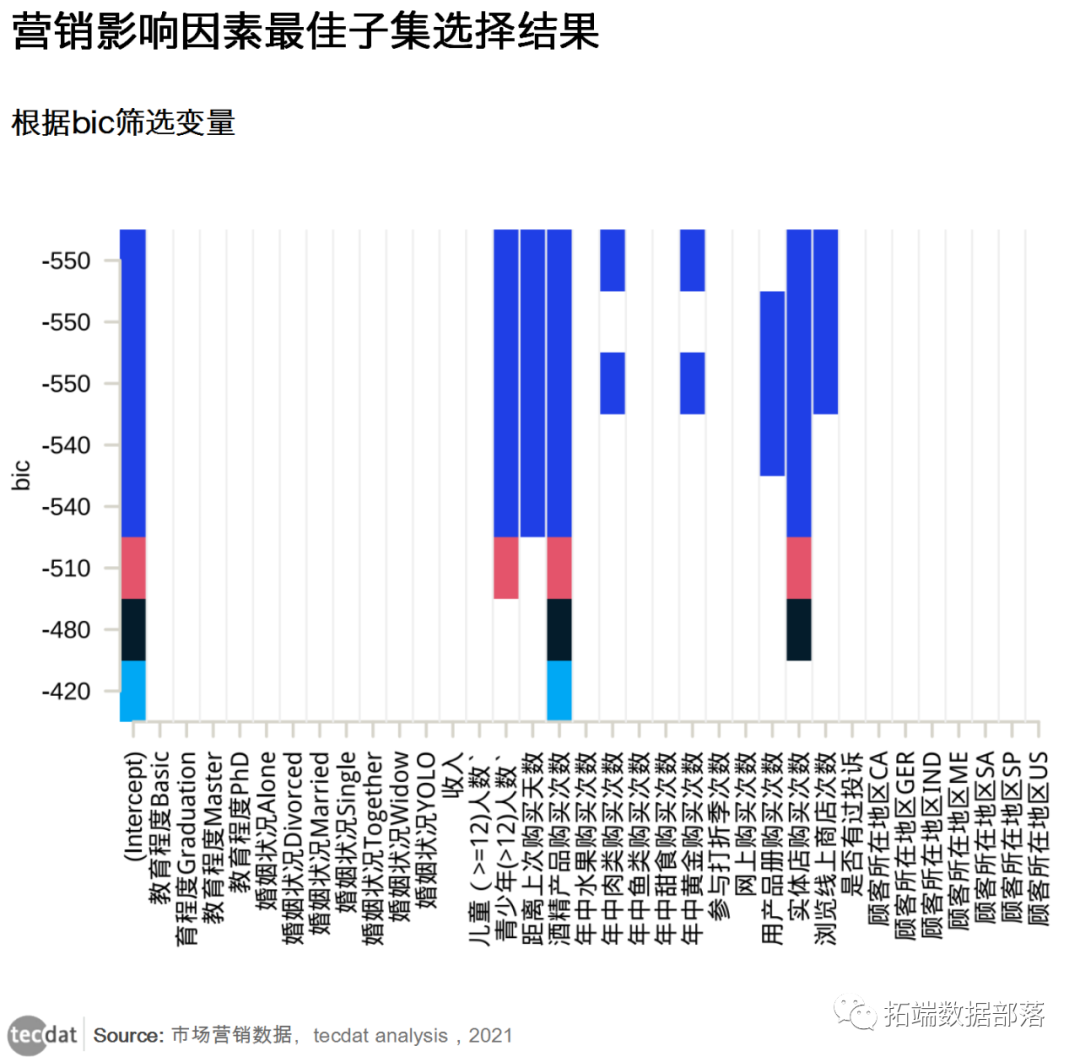
图六
在这里,调整后的 R2 告诉我们最好的模型是具有所有 8个预测变量的模型。但是,使用 BIC标准,我们应该选择具有 7 个变量的模型。
因此,根据我们考虑的指标,我们有不同的“最佳”模型。我们需要额外的策略。另请注意,调整后的 R2、BIC是根据已用于拟合模型的训练数据计算得出的。这意味着,使用这些指标的模型选择可能会过度拟合,并且在应用于新数据时可能表现不佳。更严格的方法是根据使用 k 折交叉验证技术在新测试数据上计算出的预测误差来选择模型。
最后,我们发现有8个变量的模型是最好的,它具有较低的预测误差。该模型的回归系数可以提取如下:



















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









