









论文地址:https://arxiv.org/abs/1902.07837
论文总结
本文的方法名为CFA,大意就是级联特征融合,其论文中的主题思想实际上也是不断对特征的输出进行refine。与很多直接将网络进行串联或并联的方法类似,文中将多个网络进行了连接。比较不同的一点就在于这个连接上,其上一个网络结构传入下一个网络结构的输入一共有三个:某个blocks的输出,网络结构的输出,以及该网络结构上heatmap的预测,在经过处理(卷积到相同的channel)后将三者进行element-add操作。连接结构入下图所示。最后得到的关键点输出,是几个不同的网络层的heatmap在差不多是平均操作的综合输出。

CFA的方法是基于大网络建设的,多个网络的堆叠必定会很大,不会具有实时性。另外,本文的实验是在LSP和MPII下进行的,没有在COCO上进行实验,所以无法与最新的网络进行对比。
论文介绍
级联聚合方法,Cascade Feature Aggregation,由几个子网络结构级联(类似于Hourglass的)组成,意在一步步改善预测的结果。网络结构的想法,如下图所示,将不同阶段的结果进行整合起来,一步步进行refine。最后再将多个不同子网的输出进行算数平均,得到最后预测的结果。具体级联聚合的方法,如上图所示,聚合的特征包括上一个网络结构的输入、输出和预测层,不同的输入来源都经过对应的卷积操作进行调整。

最后产生的heatmap的算数平均如下面公式所示: σ f u s i o n = ∑ i = N − n N σ i 2 n \sigma_{fusion}=\frac{\sqrt{\sum\limits_{i=N-n}^N\sigma_i^2}}{n} σfusion=ni=N−n∑Nσi2
网络细节部分,采用的Hourglass的结果,即encoder-decoder的方式。上采样的deconv layer的卷积核大小为4,同时采用更深的网络架构ResNet(50,101,152都有尝试)去“改善”Hourglass,在encoder和decoder都一样。其认为更深的encoder可以捕获不同尺度的语义信息。
实验部分
网络使用的batch normal都是cross-GPU synchronized batch normal。输入图像大小为384*384,使用了多重数据增强(如旋转、翻转、缩放、亮度、对比度、饱和度、色调)。初始学习率为5e-4,学习率衰减指数为0.3,在第6/10/13个epoch时执行学习率衰减。从heatmap中取坐标的方法为最大值所在的坐标。
在MPII上进行实验时,使用了两种训练集,(1)只使用MPII训练数据集;(2)同时使用MPII训练数据集和HSSK(Human Skeletal System Keypoints)。在ImageNet上训练的模型初始化第一阶段,随机初始化其他阶段的参数。在作者的试验中,超过三个阶段的CFA很难通过随机初始化来达到收敛,这意味着首先要训练一个3 stage的CFA,然后再用3 stage的CFA模型初始化来学习一个4 stage的CFA模型。
在LIP上进行实验时,对MPII上训练的模型进行初始化。
CFA是由多个阶段(stage)的子网组成的,作者首先研究了不同的ResNet结构作为第一个阶段的骨干网络,各网络第一阶段的预测结果如如下表所示。可以看到,实验结果随ResNet深度的加深变好,综合精度和计算量,选择ResNet-101作为第一阶段的网络。

选择了ResNet-101作为第一阶段的网络,然后实验后续阶段网络的选择,试验了ResNet-50和ResNet-101,实验结果如下表所示。可以看出,ResNet-50具有可以和ResNet-101相媲美的结果,所以认为ResNet-50作为后续阶段的网络是足够的。
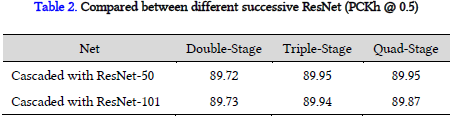
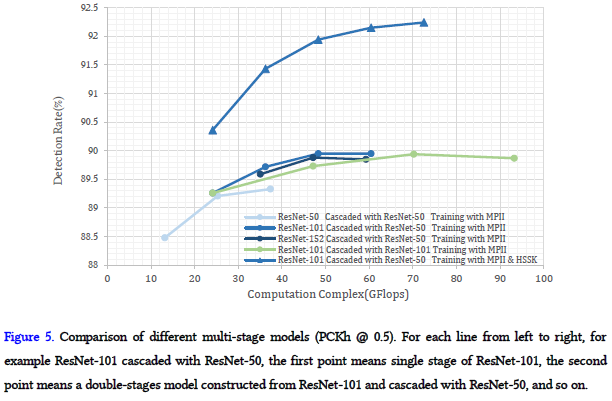
确定了网络结构的组成,然后确定CFA需要多少个stage是认为足够的。在MPII数据集上进行训练,实验结果如下图所示,在4个stage之后,性能保持稳定,对于不同网络都有一样的结果。此外,更多的数据需要更多的stager来捕捉图像到人体姿态的复杂非线性,在MPII和HSSK数据集训练,表现如下图中上面的线一样。
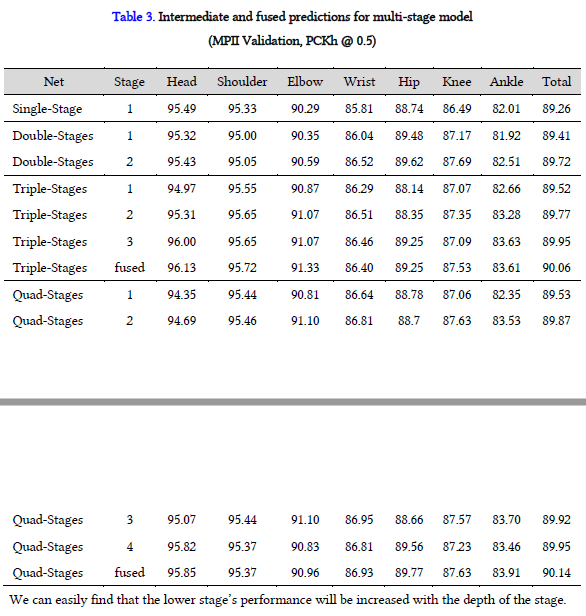
下面评估各阶段的有效性,实验结果如下表所示。可以看出,stage越深,精度越高,最后融合的heatmap更准确。
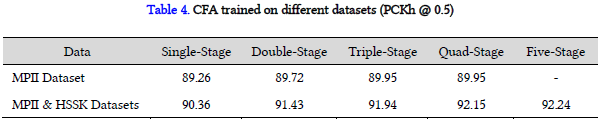
使用额外数据HSSK训练,MPII的测试集结果如下表所示。
和其他结果的对比。


下图展示了第一阶段和最后阶段的CFA结果的可视化。可以看到,最后一个阶段相较于第一阶段,在两人相交或身体部分被遮挡时会有更好的检测。

在LIP数据集上,对比结果如下表所示:

下图展示了一些CFA方法的失败案例。可以看到,对于一些光照复杂、分辨率低、运动模糊的图像,其性能下降的部分原因是由于训练集中缺乏这样的样本。















 605
605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









