









论文链接:https://arxiv.org/abs/1311.2524
作者:Ross Girshick, Jeff Donahue, Trevor Darrell, Jitendra Malik
发布时间:2013年11月发布,2014年10月最后修改
源码:https://github.com/rbgirshick/rcnn
前言
该论文是R-CNN系列的第一篇,其截取的区域图片(rigion proposals)大小不一,所以需要缩放到统一大小。后面借鉴SPP-NET提取特征的方式,可以处理不同大小的输入。
该论文的CNN结构提取特征后,分类模型使用的是多重SVM二分类模型,就是class-else模式。
IoU (Intersection over Union)
IoU,交并比,就是两个对象(这里是边框)的的交集与并集的比。
非极大值抑制
对于候选出来的边框,每个边框都有一个分数(置信度),如果有重叠(IoU达到一定阀值就可以认为重叠)的边框属于同一个类型,那么就需要丢弃一个。此时可以依据边框置信度,留下最大值的,丢弃(抑制)非最大值的重叠区域。
论文实验模型
- 在分类数据集上训练CNN网络;
- 在实验数据集上微调CNN网络;
- 输入图像,进行 rigion proposals r i g i o n p r o p o s a l s ,放入CNN网络中提取特征,将特征放入 class−special c l a s s − s p e c i a l 的 SVM S V M 分类器中分类并评分;
- 丢弃评分低于 score阈值 s c o r e 阈 值 的区域,同时每个类别按照评分执行非最大值抑制,去除重叠的区域;
- 将留下来的区域进行回归,得到最终的 bounding−box b o u n d i n g − b o x (检测边框);
从以上程序可以看出,本论文基本是三个模块:CNN网络模块以提取特征,SVM模块以得到分类,回归模块以得到检测边框。
概要
该论文前面使用的方法,基本都是从富含“高级图像特征”的内容上提取出“低级图像特征”,结合模型进行检测。该论文使用CNN模型,将Pascal VOC 2012的 mAP m A P (mean average precision)提升至 53.3% 53.3 % (提高了超过30\%)。文章有两个重点:1) 运用CNN于region proposal;2) 使用迁移学习—-先将网络用于分类,再进行微调。
引言
在CNN之前,提取特征的方式一般为SIFT(distinctive image feature)和HOG(Histograms of oriented gradients).我们知道识别系统需要发生在几个阶段后(应该是对比人在接收基本信息后的处理阶段),这也意味着可能存在用于计算特征的分层的多阶段过程,这些过程对于视觉识别更具信息性。
当时的CNN在ImageNet分类上已经取得了重大突破,此时的问题就在于CNN能在Pascal VOC目标检测上能取得怎样的效果?因为ImageNet的标记数据很多,对比起来目标检测的已标记数据就很少。
不像分类 ,目标检测需要在一张图片内检测定位。一种解决方法就是讲定位问题看做回归问题。但是,经过该论文的实验表明,那不是一个好方法(Deep neural networks for object detection在VOC 2007的mAP为30.5%,该论文达到58.5%)。一个可替代的方法是使用滑动窗口检测。
区域作为输入的CNN在目标检测和语义分割上都取得了成功。
测试时,在每张图片上截取
2000
2000
个区域,经过图片放射变换成固定大小作为CNN的输入,经过CNN的特征提取得到固定长度的特征向量(应该是除去softmax分类层的最后一个fc输出),将特征向量放入
class−else
c
l
a
s
s
−
e
l
s
e
的线性二分类SVM分类器中。因此,有了R-CNN(Regions with CNN features)。
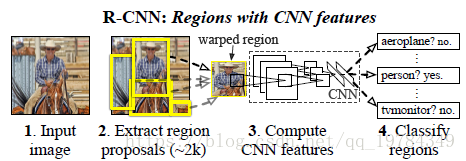
用R-CNN进行目标检测
模块设计
Region proposals的策略为selective search;候选区域的大小不一,但本论文的策略是无论候选区域的纵横比如何,都resize成统一的大小;
检测–测试时
每张图片提取2000张有独立类别的区域,历经“变形”后,经过CNN结构提取特征向量,对每个区域提取的特征向量使用二分类SVM模型对每个类别单独进行评分。对同一张图片的不同评分区域,对每一个类别进行非最大值抑制操作以丢弃多余重叠的框。
分析—运行时
本文认为有两项属性保证检测的性能:⑴ CNN参数对于每个类别的区域都是共享的;⑵ 经过CNN结构提取的特征是低维的(对比当时的其他方法)。参数共享的结果保证了提取特征的时间较短,低维向量保证了点积运算时使用的内存较小(这能保证泛化到更多的类别上)。
运行时
有监督预训练
将CNN模型放在分类数据集 ILSVRC 2012 I L S V R C 2012 上
特定领域微调
CNN使用0.001学习率的SGD训练,分类类别为 (N+1) ( N + 1 ) 个,其中N个为训练集类别,1个为背景类。如果一个region proposal具有ground-truth box的一半即标位正类,即IoU的阈值为 0.5 0.5 。统一将32个正样本,96个负样本,共128个样本作为一个小批次。
对象类别分类器
IoU阈值经过验证集的选择(在{0, 0.1, 0.2, 0.3, 0.4, 0.5}的网格搜索中)后,选定为0.3,对于所有类别都一样。这个阈值是对于训练SVM分类器的。
在附录B,文章讨论了为什么在微调SVM训练时要单独定义正负类;以及讨论了微调后的SVM与微调后的softmax作为最后分类层的区别。
Visualization, ablation, and modes of error
可视化学习到的特征
卷积层第一层卷积核可以直接可视化,而且容易去理解,它们捕获的是方向上的边缘和部件颜色(opponent color)。后面几层的可视化才是挑战。
Zeiler和Fergus
Z
e
i
l
e
r
和
F
e
r
g
u
s
提出了反卷积的方法用于可视化,本文提出一种简单(和补充complementary)的非参数方法,用于直接显示网络所学到的内容。
他们的想法是从网络中挑选特定单元(特征),把它当做对象探测器。我们在这单元的激活输出,从大到小排序,执行非最大值抑制,然后显示得分最高的区域。这样的方法通过准确触发输入,让所选单元“自己说话”。
Ablation studies
逐层展示性能(Performance),没有微调
为了明白哪一层特征对对象检测比较重要,该论文在VOC 2007上分析了CNN的最后三层(AlexNet网络中,池化层后展开的向量 p5 p 5 9216∗1 9216 ∗ 1 , 全连接层 fc6 f c 6 4096∗1 4096 ∗ 1 , softmax前的全连接层 fc7 f c 7 4096∗1 4096 ∗ 1 ),由于激活函数都是ReLu,所以这三层的激活结果都大于 0 0 。
这个段落的展示结果是经过预训练,没有经过微调的AlexNet网络(即在训练,没有在PASCAL上训练)。结果展示,如果直接将ALexNet作为类似于SIFT、HOG的特征提取器(不经过微调),将提取的特征直接用于分类,那么
p5
p
5
的精度和
fc6、fc7
f
c
6
、
f
c
7
差不多,这是令人失望的,因为计算到
p5
p
5
时,只使用了AlexNet网络的
6%
6
%
的参数;
fc6
f
c
6
的精确度比
fc7
f
c
7
要高。这表明不经过微调的AlexNet网络作为特征提取器,可以只进行到池化层。
 未经过微调AlexNet提取的特征表示
未经过微调AlexNet提取的特征表示
逐层展示性能,经过微调
网络经过微调之后,平均准确率(mAP)提升到了
54.2%
54.2
%
。这个提升主要是来自于
fc6
f
c
6
和
fc7
f
c
7
,经过微调之后,
fc7
f
c
7
做提取的特征效果比
p5、fc6
p
5
、
f
c
6
好得多。因此,可以得出一个结论:卷机网络的卷积层提取的特征是提取的通用特征,类似于SIFT和HOG
 经过微调AlexNet提取的特征表示
经过微调AlexNet提取的特征表示
网络架构选择
如果选择 VGG16 V G G 16 作为特征提取器, mAP m A P 可以从 58.5% 58.5 % 上升到 66.0% 66.0 % ,但是时间会多消耗很多。作者认为这是一种倒退。
附录
Object proposal transformations
此时卷积层的输入是固定的,该网络结构的输入大小为 227∗227 227 ∗ 227 ,此时有两种resize方式可以选择:⑴ 各向同性缩放;⑵ 各向异性缩放。
各向异性
该方法是不管输入size如何,直接扭曲图像成需要的大小,如下图的
(D)
(
D
)
所示。我们知道,图像具有空间结构,我们从空间结构提取特征,这样直接缩放会一定程度的破坏其空间结构。

各向同性
作者使用了两种方法各向同性的方法:⑴ 在原图上,以选出来的区域为中心,扩展成输入大小,如上图 (B) ( B ) 所示;⑵ 用固定背景颜色填充选出来的区域,如上图 (C) ( C ) 所示。
正负样本以及Softmax
正负样本的定义在CNN架构微调时以及训练SVM时不一样,前者定义的IoU阈值为(至少)
0.5
0.5
,后者定义的IoU阈值为(至多)
0.3
0.3
。
作者在微调AlexNet网络时,一开始使用了和后面SVM一样的
0.3
0.3
阈值,但没有现在的
0.5
0.5
阈值好。作者推断:如何定义正负类不是原则重要的,造成这个现象的原因是训练CNN的数据量不够,数据不够会造成过拟合。
阈值不一样,直观上就能看出这个数据集不是为了SVM分类选定的,那么为什么不直接使用softmax层?
刚开始只是使用了softmax层,但是
mAP
m
A
P
从
54.2%
54.2
%
下降到了
50.9%
50.9
%
。这性能的下降可能是由于一下几个因子的共同作用:⑴ 定义正负样本点的时候不强调精确定位;⑵ 训练softmax层的时候,不像训练SVM那般使用“硬负样本”,而是随机使用负样本。那么问题来了,为什么不直接固定前面的参数,训练最后一个softmax层?
作者推断可以通过调整使得不用在微调后多训练一个SVM分类器也可以达到一样的性能。如果是真的,那将加速R-CNN的训练时间而不损失检测质量。
Bounding-box 回归
使用 bounding−box b o u n d i n g − b o x 回归来改善回归表现。在对每个候选区域(region proposals)进行SVM分类评分之后,通过对每个类别单独进行 bounding−box b o u n d i n g − b o x 回归,来预测一个新的 bounding−box b o u n d i n g − b o x .
为什么要进行Bounding-box回归?
如下图所示,有些图像不需要完整的结构就能预测其类别,因此直接提取的
rigionproposals
r
i
g
i
o
n
p
r
o
p
o
s
a
l
s
可能不太完整。通过数据进行拟合,让
rigion proposals
r
i
g
i
o
n
p
r
o
p
o
s
a
l
s
提供的
bounding−box
b
o
u
n
d
i
n
g
−
b
o
x
变成较为符合
ground−truth
g
r
o
u
n
d
−
t
r
u
t
h
的
bounding−box
b
o
u
n
d
i
n
g
−
b
o
x
。当然,只有较为贴近
ground−truth
g
r
o
u
n
d
−
t
r
u
t
h
的区域才是较为有用的数据,与
ground−truth
g
r
o
u
n
d
−
t
r
u
t
h
的
IoU
I
o
U
较低的区域可能成为垃圾数据,本论文选择
IoU=0.6
I
o
U
=
0.6
作为筛选回归数据的过滤器。

回归算法的输入为
{(Pi,Gi)}i=1,...,N,及其经过CNN结构最后一池化层产生的 p5 特征向量 fi
{
(
P
i
,
G
i
)
}
i
=
1
,
.
.
.
,
N
,
及
其
经
过
C
N
N
结
构
最
后
一
池
化
层
产
生
的
p
5
特
征
向
量
f
i
,其中
Pi=(Pix,Piy,Piw,Pih)
P
i
=
(
P
x
i
,
P
y
i
,
P
w
i
,
P
h
i
)
表示第
i
i
个 的中心点
(x,y)
(
x
,
y
)
和长宽
(w,h)
(
w
,
h
)
;
Gi
G
i
同理。下面进行推导运算时,丢弃上标
i
i
,那么我们想要做的就是从的回归。则有以下公式:
平移:
经过试验鉴定,正则化尺度竟然高达 λ=1000 λ = 1000 在验证集上;在测试时,理论上变换后的边框区域再去分类的效果比较好,但试验表明并没有提升试验数据,所以在测试时只进行一次分类和边框尺度变换,而不迭代。
文中展示比较引起注意的一些检测结果






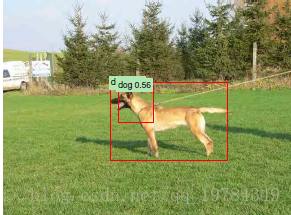

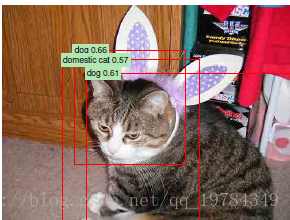

















 445
445

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









