







论文链接:https://arxiv.org/abs/1612.08242
作者:Joseph Redmon, Ali Farhadi
发布时间:2016年12月25日发布
前言
该文是YOLO系列第二篇,在模型结构上做的改变主要是添加了anchor boxes(就如同Faster RCNN中的anchor boxes一样,但选择方式不同,Faster RCNN是通过直接设定尺度及长宽比的形式,而YOLOv2通过k-means对边框进行聚类);以及考虑了Fine-Grained Features问题,添加了一个passthrough,将不同resolution的特征结合在了一起;剩下的篇幅讲的是训练技巧、细节,从而得到更高的mAP(这也是YOLO的问题所在,YOLO达到了实时的要求,但mAP和最先进的检测系统,如Faster RCNN/SSD,相差较大。)
该模型的输出的是一个tensor,为 S ∗ S ∗ B ∗ ( 5 + C ) \mathbb{S}*\mathbb{S}*\mathbb{B}*(5+\mathbb{C}) S∗S∗B∗(5+C),其中 S \mathbb{S} S为图片分为 S ∗ S \mathbb{S}*\mathbb{S} S∗S个格子,一个格子里有 B \mathbb{B} B个bounding-boxes,数据集有 C \mathbb{C} C个类。(这里和YOLO不同的是,YOLOv2是一个边框预测一次对象的类别;而YOLO是一个网格只对一个对象负责,所以只预测一类别,其输出大小是 5 ∗ B + C 5*\mathbb{B}+\mathbb{C} 5∗B+C)
YOLOv2和YOLO9000是两个不同的模型,一并提出,YOLOv2 + join training = YOLO9000。
置信度是 P r ( O b j e c t ) Pr(Object) Pr(Object),而分类概率的预测是 P r ( C l a s s ∣ O b j e c t ) Pr(Class|Object) Pr(Class∣Object).
YOLOv2去掉了全连接层,使用的是全卷积网络,所以应对不同的输入分辨率(对应输出不同大小)。
概要
YOLO9000的意思是该系统可以检测超过
9000
9000
9000个类别。
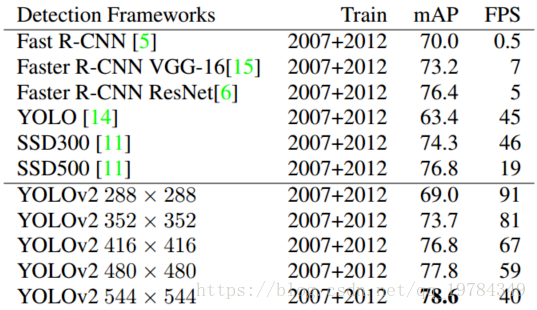
作者在YOLO基础上改进得到了YOLOv2。YOLOv2是通过多尺度训练方法(不同size的输入)得到的,其能简单地在速度和准度上形成折中(在VOC2007上,如果需要
67
67
67FPS,其能达到
76.8
76.8
76.8mAP;如果需要
40
40
40FPS,其能达到
78.6
78.6
78.6mAP。该模型的结果比目前最好的检测模型,Faster RCNN和SSD,精确度更高,检测速度更快)。
最后,作者提出了一个目标检测和目标分类的联合训练方法。通过该方法,YOLO9000可以同时在COCO检测数据集和ImageNet分类数据集上训练。联合训练使得YOLO9000可以检测没有检测数据标签的对象类的检测。(就是说该对象在检测数据集上是没有的,即训练时是没有边框标签的,但拥有其分类标签。其原因可能在于,该模型是对于位置训练检测bounding-boxes的,不像Faster RCNN对于objectes训练检测bounding-boxes。当然,对于没有检测标签的类,其检测结果可能不太完美。YOLO9000在ImageNet的检测数据上(200类中的44类在COCO数据集上有检测数据)的mAP为 19.7 19.7 19.7,在COCO数据集上没有检测数据的 156 156 156个类的mAP为 16.0 16.0 16.0。)
引言
目标检测的一般目标为:快速,精确,大范围识别目标。
现在目标检测的数据库相对于目标分类的数据库来说是相对较小的。所以作者提出了联合训练的方法,使用分类数据集来帮助训练检测模型。
改进
Better
YOLO相对于Fast RCNN之类的最先进的目标检测算法而言,其检测精度不足。与此同时,YOLO算法不是基于region proposal的,其对比基于区域候选的算法而言,Recall也相对较低。因此作者本文着重解决精度和召回率问题。
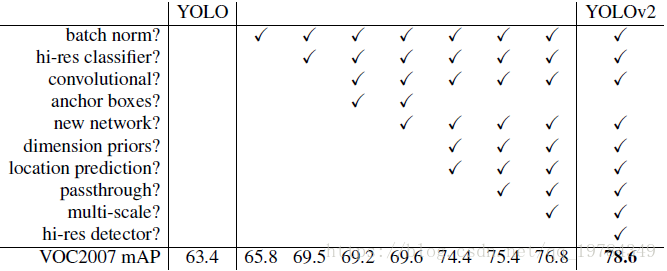
YOLOv2所做的尝试如上图所示,基本这些操作都大幅增加了算法的mAP,其中较为特殊的是anchor boxes和new network,前者在基本不改变mAP的同时增加了Recall,后者减少了
35
%
35\%
35%的计算(在
3
∗
3
3*3
3∗3的卷积核之间添加
1
∗
1
1*1
1∗1卷积核来降低特征维度)
Batch Normalization
和我们所知的一样,使用了Batch Normalization,(可以)相当于使用了(
L
2
L_2
L2)正则化手段,同时可以丢弃YOLO训练时使用的dropout正则化手段(一般认为同时使用BN和dropout是冲突的,反而影响收敛效果)。作者在每个卷积层前都是用了BN,带来模型结果提升的mAP超过
2
%
2\%
2%。
High Resolution Classifier
YOLO算法的预训练输入的size是
224
∗
224
224*224
224∗224,然后在(分类到检测)微调时增长到
448
∗
448
448*448
448∗448,这意味着模型需要同时适应学习不同的目标(从分类到检测)和适应新的输入分辨率。(预训练大多是在ImageNet的分类模型上完成的,YOLO是在AlexNet的基础上完成的,AlexNet的输入size是
256
∗
256
256*256
256∗256,大多数基于AlexNet微调的分类器模型输入都是小于此的,所以作者在YOLO模型选择时使用输入为
224
∗
224
224*224
224∗224)
作者在模型预训练之后,将输入转为 448 ∗ 448 448*448 448∗448,在ImageNet上训练 10 10 10个周期,以期待网络模型能让它的卷积核更加适应新的输入分辨率。然后再微调网络用于检测。作者通过网络微调前训练 10 10 10个周期的新输入分辨率于ImageNet,带来的模型结果提升接近 4 % 4\% 4%。
Convolutional With anchor boxes
YOLO直接通过全连接层预测边框信息;而Faster RCNN通过手动设定bounding boxes,通过RPN的一个卷积层来预测anchor boxes的偏移和置信度;相对于直接预测边框坐标信息,预测偏移相对而言更简单些,也就是更容易让网络去学习。(因此YOLOv2采用了anchor boxes)
我们可以看到,YOLO的模型结构的输出最后如下第一个图,但其输出实际上是如下第二个图(是一个向量,每一个网格需要的信息在里面意义对应):
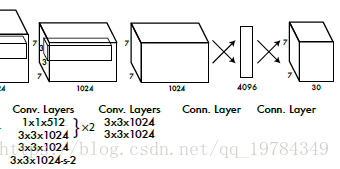

作者通过去除全连接层,使用卷积层来使得结果如上图1的模型输出展示结果一样(每个网格可以在最后的output上找到对应的信息)。由于我们需要一个唯一的“中点”来表示一个网格中心,所以作者将原输入的size从 448 448 448减小到了 416 416 416(因为YOLO的stride积为 32 32 32,每一个网格的大小是 ( W 32 , H 32 (\frac{W}{32},\frac{H}{32} (32W,32H),所以输入的size需要是 32 32 32的倍数。 416 ∗ 416 416*416 416∗416的输出是 13 ∗ 13 13*13 13∗13)【为什么需要用奇数网格来显示网络的“中心”?因为作者觉得,大的对象的中心较为倾向于在图片的中间,因此使用一个中心来表示对象比四个中心来表示对象要更好。实际上,这是作者的设定问题,作者的设定是一个对象只用一个网格来负责。但从后面的多尺度训练的Input_size和YOLOv3的结构来看,其实这也不是作者一直奉承进行的。】
使用了anchor boxes后,模型输出就是对每一个anchor boxes进行置信度预测(和ground truth的IoU)& 类别预测 & 回归预测。每个网格预测两个anchor boxes。(因为YOLO有强烈的空间限制,对于每一个网格,只预测一个类别,所以对重叠的对象群,比如一群鸟,预测不太好。这里作者改进为一个边框预测一个)
从结果展示来看,YOLOv2使用了anchor boxes之后,mAP从 69.5 69.5 69.5掉到了 69.2 69.2 69.2,但Recall从 81 % 81\% 81%涨到了 88 % 88\% 88%。【这个mAP的下降不是基于相同数量的bounding box的。因为这里比较时,不适用anchor boxes直接预测时,作者说其预测了超过 1000 1000 1000个边框,而不是YOLO论文中提到的98个。所以YOLOv2使用 98 98 98个anchor boxes比较的是 1000 1000 1000个不使用anchor boxes的直接边框预测。检测速度不知道比较如何,可能优化时先使用了预测1000个边框,也就是每个网格预测超过20个边框,后面再参考Faster RCNN使用anchor boxes】
Dimension Clusters
在Faster RCNN中,anchor boxes是手动设计的。手动设计是设计者拥有前验知识判断的,所以作者想到使用**k-means**聚类算法来初始化anchor boxes(一般认为,如果训练得当的话,一个好的初始化能更快得收敛,得到更好的结果,也就是更易于学习)。
决定使用k-means后,使用怎样的距离判断就成为该聚类算法的关键。和传统基于欧式距离判断的距离不同,在目标检测中边框的“贴近”程度是依据IoU判断的,所以作者设计了一种使用于目标检测的距离函数: d ( b o x , c e n t r o i d ) = 1 − I o U ( b o x , c e n t r o i d ) d(box,centroid)=1-IoU(box,centroid) d(box,centroid)=1−IoU(box,centroid) 最后基于计算复杂度和准确度的考虑,选择 k = 5 k=5 k=5。(适用平均IoU来评估聚类结果的好坏)
Direct location prediction
从anchor boxes到最后的bounding boxes,其边框预测的方式和Faster RCNN差不多,只是将最后中心点
(
x
,
y
)
(x,y)
(x,y)偏移的幅度限制了,避免出现一个边框范围的偏移(其实如果出现这么大的偏移,那么为该对象负责的格子一般也就是另一个,也就是说这个范围的偏移其实是不必要的“振荡”。因此,这个限制,作者认为是让模型从“不稳定”到稳定了)。对于每一个bounding boxes,模型预测
5
5
5个值
(
t
x
,
t
y
,
t
w
,
t
h
,
t
o
)
(t_x,t_y,t_w,t_h,t_o)
(tx,ty,tw,th,to),其中
t
o
t_o
to是置信度。作者通过k-means聚类边框,和直接预测bounding boxes中心位置,带来的模型结果提升接近
5
%
5\%
5%。
其中,(tx, ty, tw, th)都不是直接预测值,其作用表现为: b x = σ ( t x ) + c x b_x=\sigma(t_x)+c_x bx=σ(tx)+cx b y = σ ( t y ) + c y b_y=\sigma(t_y)+c_y by=σ(ty)+cy b w = p w e t w bw=p_we^{t_w} bw=pwetw b h = p h e t h b_h=p_he^{t_h} bh=pheth 其中,(cx, cy)为预测cell的左上角坐标,(pw, ph)是先验框的长宽;
迭代收敛时,用相对坐标: b x = σ ( t x ) + c x W b_x=\frac{\sigma(t_x)+c_x}{W} bx=Wσ(tx)+cx b y = σ ( t y ) + c y H b_y=\frac{\sigma(t_y)+c_y}{H} by=Hσ(ty)+cy b w = p w e t w W b_w=\frac{p_we^{t_w}}{W} bw=Wpwetw b h = p h e t h H b_h=\frac{p_he^{t_h}}{H} bh=Hpheth 其中,(W, H)是整张图片的宽长
Fine-Grained Features
作者想着,Faster RCNN和SSD都通过不同size的输入来得到不同精度的feature mAPs,而YOLO是采用resize处理不同输入,从而大对象和小对象都对应同一个精度,没得到区别对待。所以,作者想到了添加一个passthrough layer(就像ResNet一样,但区别在于YOLO是将
26
∗
26
∗
512
26*26*512
26∗26∗512添加到
13
∗
13
∗
2048
13*13*2048
13∗13∗2048上,而ResNet是处理相同size的连接),使得feature mAPs同时拥有不同精度的特征,其目的是为了更好地检测小目标。
至于如何具体实现passthrough layer,作者是通过将
26
∗
26
∗
512
26*26*512
26∗26∗512隔行隔列采样,得到4个新的feature mAPs
13
∗
13
∗
512
13*13*512
13∗13∗512,再concat起来,得到
13
∗
13
∗
2048
13*13*2048
13∗13∗2048的feature mAPs,再与后面的层加起来,相当于作特征融合。细粒度特征融合,带来的模型结果提升接近
5
%
5\%
5%。
Multi-Scale Training
由于YOLOv2的模型没有全连接层,所以其可以采用任意size的输入(相应得到不同的输出,但卷积核用的是相同的)。
作者在训练时,想通过该特点来使得网络能处理不同分辨率的输入图片,所以作者在训练时每隔
10
10
10个epochs,就随机选取一个resize的输入:
32
的倍数:
{
320
,
352
,
.
.
.
,
608
}
32的倍数:\{320,352,...,608\}
32的倍数:{320,352,...,608}(模型的下采样参数为32)。通过该方法,模型处理不同size的输入可以得到不同FPS的结果与其对应的分辨率。(让小图片可以训练的更快,也不用失真的放大太多,从而影响检测结果)
Faster
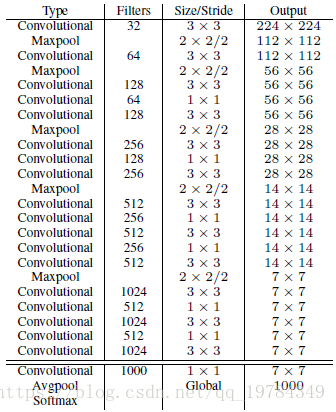
Darknet-19
YOLOv2的网络和YOLO差不多(因为YOLO网络的Top-5分类准确率比VGG要稍微低一点,而VGG是当时大多数目标检测所用的网络),都在
3
∗
3
3*3
3∗3卷积核的中间穿插使用
1
∗
1
1*1
1∗1卷积核,从而大量减少计算量。YOLOv2网络模型的名字叫做Darknet-19,其拥有
19
19
19个卷积层和
5
5
5个最大池化层。
Training for classification
和YOLO一样,在标准的1000分类的ImageNet数据集上训练
160
160
160个周期,其使用的工具为:
l
r
=
0.1
lr=0.1
lr=0.1,多项式衰减(
p
o
w
=
4
pow=4
pow=4)(学习衰减率的一种方式,有指数衰减,步长衰减,多项式衰减等),
0.9
0.9
0.9的动量,权重衰减率为
0.0005
0.0005
0.0005。在训练的同时使用数据增强手段,包括random crops,rotations,hue,saturation,exposure shifts。
前面说了,这个论文提出,模型不应该微调的时候同时适应新的分辨率和新的目标任务(分类和检测),所以在原预训练之后,会增加10个周期的新输入分辨率。其训练使用的工具有:
l
r
=
0.001
lr=0.001
lr=0.001。
Training for detection
YOLOv2检测模型就不是Darknet-19(最后一层是
(
1
∗
1
,
o
u
t
p
u
t
_
c
h
a
n
n
e
l
=
1000
(1*1,output\_channel=1000
(1∗1,output_channel=1000)卷积核的池化层,此时输出为
7
∗
7
∗
1000
7*7*1000
7∗7∗1000;后面再接一个平均池化层,此时输出为
1
∗
1
∗
1000
1*1*1000
1∗1∗1000)了,训练检测时,将最后一个卷积层用三个
(
3
∗
3
,
o
u
t
p
u
t
_
c
h
a
n
n
e
l
=
1024
)
(3*3,output\_channel=1024)
(3∗3,output_channel=1024)的卷积核替代,每个
3
∗
3
3*3
3∗3的卷积层中穿插着一个
1
∗
1
1*1
1∗1,输出通道为检测目标通道(在VOC数据集中,每个格子预测5个bounding boxes,那么其输出channel为
5
∗
5
+
5
∗
20
=
125
5*5+5*20=125
5∗5+5∗20=125)。
训练工具:一共训练 160 160 160个周期,模型初始学习率为 0.001 0.001 0.001,学习率在第 60 60 60和 90 90 90个周期都除以了 10 10 10。
作者在训练检测时,也使用了passthrough layers。但是这里没理解怎么弄的,所以po出原文,等领悟了再看看吧。。。。We also add a passthrough layer from the final 3 ∗ 3 ∗ 512 3*3*512 3∗3∗512 layer to the second to last convolutional layer so that our model can use fine grain features.(吴恩达老师的网络课程《deeplearning.ai》中的目标检测模型讲的就是YOLO,依据其中运用了anchor boxes来看,老师是看了YOLO9000这论文的。但老师说他和他研究这方向的朋友也没完全看懂。。。所以这里就放着吧)
Stronger
识别的mAP其实不是很高,
19.7
%
和
16.0
%
19.7\%和16.0\%
19.7%和16.0%,所以就展示不弄了。

















 1420
1420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









