







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦
🚀 快速阅读
- 功能强大:支持1080P无限长视频生成,具备复杂动作展现、物理规律还原等功能。
- 技术先进:基于VAE和DiT架构,增强时空上下文建模能力,支持高效编解码。
- 应用广泛:适用于影视制作、广告视频、教学辅助、文化创作等多个领域。
正文(附运行示例)
万相2.1 是什么
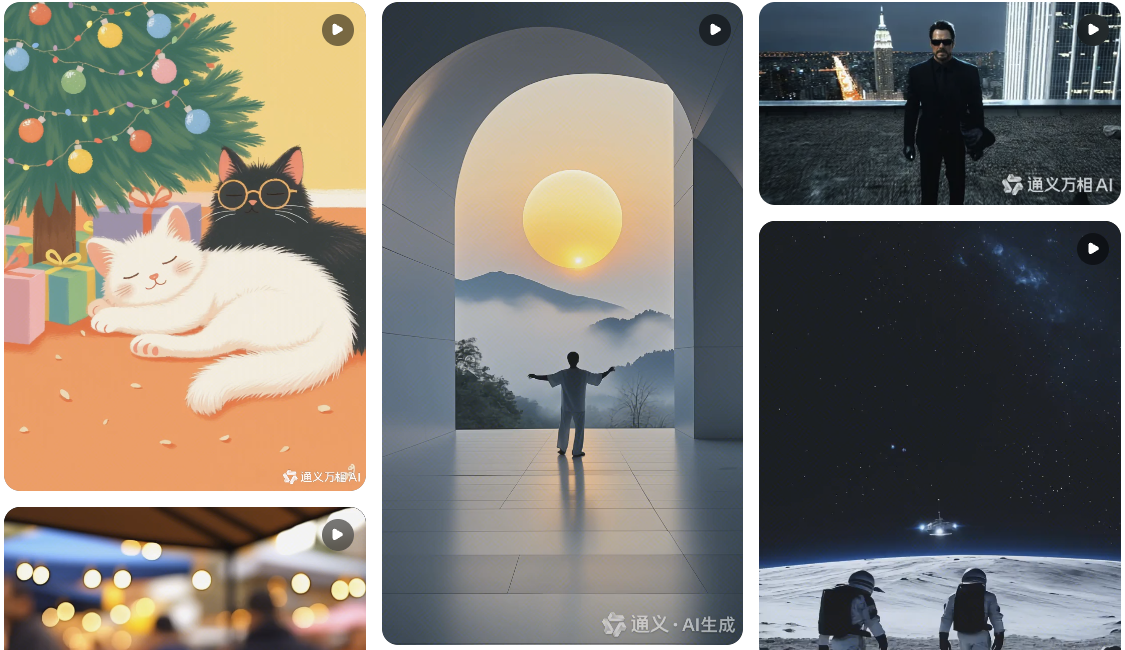
万相2.1是阿里推出的通义万相升级版本,基于自研的高效VAE和DiT架构,增强时空上下文建模能力,支持无限长1080P视频的高效编解码。首次实现中文文字视频生成功能,并在VBench榜单上荣登第一。
万相2.1能够稳定展现复杂人物运动,逼真还原现实物理规律,一键生成中英文视频特效,具备强大的影视质感与艺术风格转换能力。此外,它还支持文生组图,采用IC-LoRA图像生成训练方法,增强文本到图像的上下文能力,轻松实现关联图像间的组合生成。
万相2.1 的主要功能
- 复杂动作展现:稳定展现各种复杂的人物肢体运动,如旋转、跳跃、转身、翻滚等,及镜头的移动,让视频内容更加生动和真实。
- 物理规律还原:逼真还原真实世界的物理规律,如碰撞、反弹、切割、挤压等。比如生成雨滴落在伞上溅起水花的场景,让视频更具真实感。
- 中英文视频特效生成:提供多种视频特效选项,如过渡、粒子效果、模拟等,能一键生成中英文视频特效,增强视频的视觉表现力。
- 艺术风格转换:具备强大的艺术风格表现力,能一键转换视频的影视质感与艺术风格,如电影色调、印象笔触、抽象表现等,生成各种风格的视频。
- 图生成:支持分镜效果还原、四格漫画创作、创意头像定制等功能,满足用户的不同需求。
万相2.1 的技术原理
- VAE架构:变分自编码器(VAE)是生成模型,用编码器将输入数据映射到一个潜在空间,再用解码器将潜在空间的表示映射回数据空间,实现数据的生成和重建。
- DiT架构:DiT(Diffusion in Time)架构是基于扩散模型的生成模型,在时间维度上逐步引入噪声,逐步去除噪声生成数据。DiT能有效地捕捉视频的时空结构,支持高效编解码和生成高质量的视频。
- IC-LoRA:IC-LoRA是一种图像生成训练方法,基于结合图像内容和文本描述,增强文本到图像的上下文能力,让生成的图像更加符合用户的文本描述和期望。
- 上下文建模:基于增强时空上下文建模能力,更好地理解和生成具有连贯性和一致性的视频内容,让视频中的动作、场景和风格等元素更加自然和协调。
如何运行 万相2.1
1. 访问官网
首先,访问通义万相AI视频官网,开启视频创作。
2. 输入提示词
根据需求输入提示词,例如:
- 文字特效:以红色新年宣纸为背景,出现一滴水墨,晕染墨汁缓缓晕染开来。
- 运动:一辆汽车在被雪覆盖的公路上高速飞驰。
3. 生成视频
点击生成按钮,万相2.1将根据提示词生成相应的视频内容。
资源
- 项目官网:https://wanxiang.aliyun.com/
- arXiv 技术论文:https://arxiv.org/pdf/2410.06734
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发非常感兴趣,我会每日分享大模型与 AI 领域的最新开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术,欢迎关注我哦!
🥦 微信公众号|搜一搜:蚝油菜花 🥦

















 1038
1038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









