







❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦
🎙️ “智能家居集体「觉醒」!开源语音模型听懂你的川普怒吼,方言骂人都能温柔回应”
大家好,我是蚝油菜花。你是否经历过——
- 👉 用普通话叫智能音箱关灯,它反问“您是要开灯吗?”
- 👉 教长辈说标准指令,不如直接替他们按开关
- 👉 客服机器人永远用播音腔说“理解您的心情”…
今天介绍的 Step-Audio ,正在终结这些智障交互!这个由阶跃星辰开源的130B参数怪兽:
- ✅ 听得懂20+方言:四川话吐槽空调太热?马上调低3℃
- ✅ 情感即时映射:愤怒语气触发应急模式,悲伤时自动切换温柔声线
- ✅ 端到端实时交互:1秒内完成“听-想-说”全流程,延迟比眨眼还快
从智能家居到银发陪护,连方言短剧配音都在用它——你的设备准备好拥有「灵魂」了吗?
🚀 快速阅读
Step-Audio 是一款支持多语言、方言和情感表达的语音交互模型,能够实现高质量的语音识别、对话和合成。
- 核心功能:统一的语音理解与生成框架,支持多语言、方言和情感控制。
- 技术原理:基于 130B 参数的多模态大模型,结合双码本语音分词器和混合语音合成器,实现高效的语音处理和实时推理。
Step-Audio 是什么
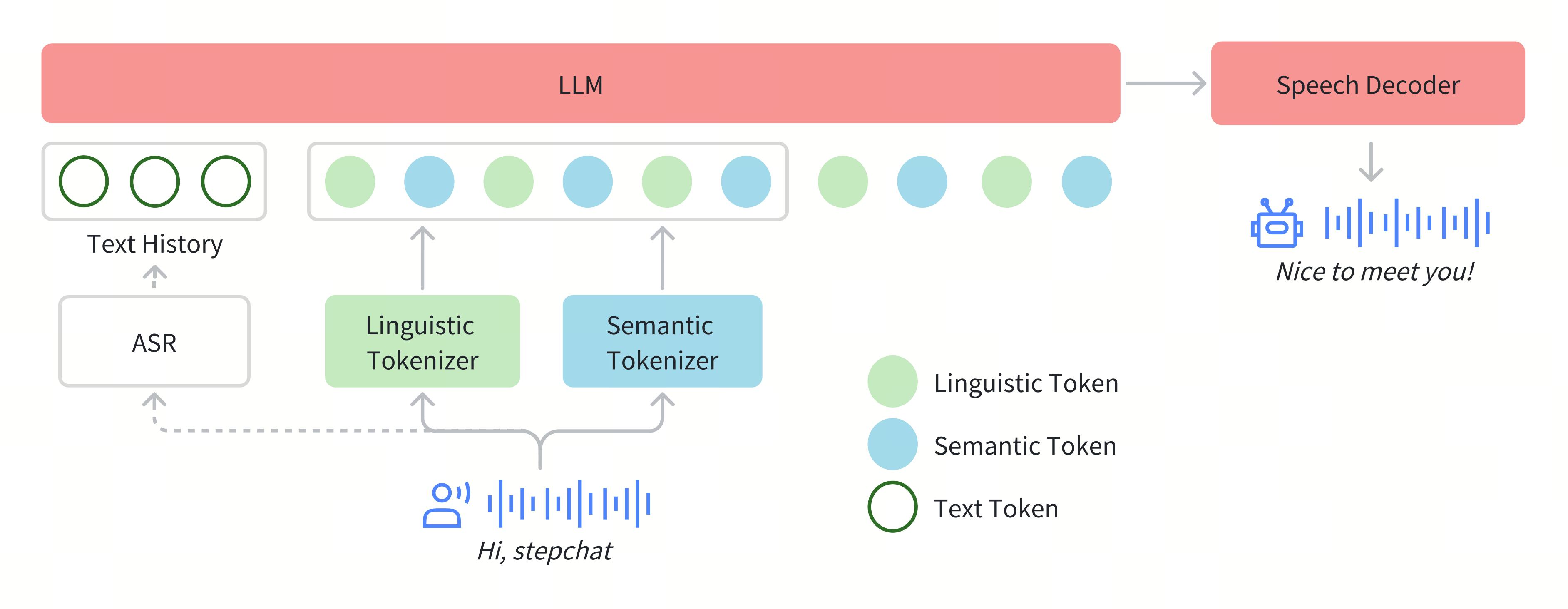
Step-Audio 是由阶跃星辰团队推出的首个产品级开源语音交互模型,旨在为用户提供高质量的语音交互体验。该模型基于 130B 参数的多模态大模型,能够根据不同的场景需求生成带有特定情感、方言、语种和个性化风格的语音表达。Step-Audio 不仅支持语音识别、对话生成,还具备强大的语音合成能力,能够在智能家居、智能客服、教育、娱乐等多个领域发挥作用。
Step-Audio 的核心优势在于其高效的数据生成引擎、精细的情感和方言控制能力,以及增强的工具调用和角色扮演功能。这些特性使得 Step-Audio 在复杂任务处理中表现出色,能够为用户提供更加自然、流畅的语音交互体验。
Step-Audio 的主要功能
- 语音理解与生成的统一:同时处理语音识别(ASR)、语义理解、对话生成和语音合成(TTS),实现端到端的语音交互。
- 多语言和方言支持:支持多种语言和方言(如粤语、四川话等),满足不同地区用户的需求。
- 情感和风格控制:支持生成带有特定情感(如愤怒、喜悦、悲伤)和风格(如说唱、演唱)的语音。
- 工具调用与角色扮演:支持实时工具调用(如查询天气、获取信息)和角色扮演,提升交互的灵活性和智能化水平。
- 高质量语音合成:基于开源的 Step-Audio-TTS-3B 模型,提供自然流畅的语音输出,支持音色克隆和个性化语音生成。
Step-Audio 的技术原理
- 双码本语音分词器:使用语言码本(16.7Hz,1024 码本)和语义码本(25Hz,4096 码本)对语音进行分词,基于 2:3 的时间交错方式整合语音特征,提升语音的语义和声学表示能力。
- 130B 参数的多模态大模型:基于 Step-1 预训练文本模型,通过音频上下文的持续预训练和后训练,增强模型对语音和文本的理解与生成能力,支持语音和文本的双向交互。
- 混合语音合成器:结合流匹配和神经声码器技术,优化实时波形生成,支持高质量的语音输出,同时保留语音的情感和风格特征。
- 实时推理与低延迟交互:采用推测性响应生成机制,用户暂停时提前生成可能的回复,减少交互延迟。基于语音活动检测(VAD)和流式音频分词器,实时处理输入语音,提升交互的流畅性。
- 强化学习与指令跟随:使用人类反馈的强化学习(RLHF)优化模型的对话能力,确保生成的语音更符合人类的指令和语义逻辑。基于指令标签和多轮对话训练,提升模型在复杂场景下的表现。
如何运行 Step-Audio
1. 环境准备
Step-Audio 需要在以下环境中运行:
| Model | Setting (sample frequency) | GPU Minimum Memory |
|---|---|---|
| Step-Audio-Tokenizer | 41.6Hz | 1.5GB |
| Step-Audio-Chat | 41.6Hz | 265GB |
| Step-Audio-TTS-3B | 41.6Hz | 8GB |
- 硬件要求:建议使用 NVIDIA GPU,并安装 CUDA 支持。推荐使用 4xA800/H800 GPU,每块 GPU 至少 80GB 内存。
- 操作系统:已测试的操作系统为 Linux。
2. 安装依赖
git clone https://github.com/stepfun-ai/Step-Audio.git
conda create -n stepaudio python=3.10
conda activate stepaudio
cd Step-Audio
pip install -r requirements.txt
git lfs install
git clone https://huggingface.co/stepfun-ai/Step-Audio-Tokenizer
git clone https://huggingface.co/stepfun-ai/Step-Audio-Chat
git clone https://huggingface.co/stepfun-ai/Step-Audio-TTS-3B
下载完成后,目录结构应如下所示:
where_you_download_dir
├── Step-Audio-Tokenizer
├── Step-Audio-Chat
├── Step-Audio-TTS-3B
3. 推理脚本
- 离线推理:使用
offline_inference.py进行端到端的音频或文本输入和输出推理。
python offline_inference.py --model-path where_you_download_dir
- TTS 推理:使用
tts_inference.py进行文本到语音的合成,支持默认发音人或克隆新的发音人。
python tts_inference.py --model-path where_you_download_dir --output-path where_you_save_audio_dir --synthesis-type use_tts_or_clone
对于克隆模式,需要提供一个发音人信息字典,格式如下:
{
"speaker": "speaker id",
"prompt_text": "content of prompt wav",
"wav_path": "prompt wav path"
}
- 启动 Web Demo:启动本地服务器进行在线推理。
python app.py --model-path where_you_download_dir
资源
- GitHub 仓库:https://github.com/stepfun-ai/Step-Audio
❤️ 如果你也关注 AI 的发展现状,且对 AI 应用开发感兴趣,我会每日分享大模型与 AI 领域的开源项目和应用,提供运行实例和实用教程,帮助你快速上手AI技术!
🥦 AI 在线答疑 -> 智能检索历史文章和开源项目 -> 尽在微信公众号 -> 搜一搜:蚝油菜花 🥦

















 1046
1046

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









