






梳理vllm过程中的个人思路(流水账)
一、page attention
● 序列(sequence):输入加输出为一个完整的序列
● 请求(request):指用户的请求,生命周期为系统接收到并完成处理,请求包括输入(prompt)、超参(例如 top-k)以及输出(output)
page attention的精髓在于处理碎片化内存,在vllm优化前的kvcache处理方式是非常碎片化的,每一次我们输入prompt时,llm都会预先分配output+prompt的连续空间,如下图是现有推理系统分配kvcache方式

例如我们第一次输入的prompt为黄色的Four score and seven years ago out,output内容为father brought…系统为这次输入+输出(称之为一次请求A)预先分配2048个slot(每个 slot 用于存放 1 个 token 的 KV 值),输入prompt占用7个slot,输出output占用若干slot。但大概率最终生成的output不会占用完生成的slot,例如上图中有2038个slot未被利用,所以这些未知就被碎片化浪费掉了,这2038个slot称之为内部碎片。当我们进行一次请求B的时候,系统再次为请求B分配空间(图中绿色的部分),可以看到请求A和请求B之间有2个slot,这两个灰色的slot时外部碎片,因为过于小所以基本上不会被分配给其他request导致浪费。
除了碎片化外还有重要的一点:无法利用共享空间
有些解码算法会为一个请求生成多个输出,例如 parallel sampling 和 beam search,而现有推理系统无法利用这个特点将同一 prompt 存储在同一块空间。下图是parallel sampling 的示意图。

究其原因,KV cache 利用率低下是现有推理系统需将 KV cache 存储在连续的内存空间导致的,而内存空间的连续性正是深度学习框架处理张量所必须的。它的做法是预先分配一大块显存,并将大块显存划分成较小的块(block),每块可以存放固定数量 token 的 key 和 value 值,为请求的 KV cache 分配空间时按需分配,且无需存储在连续的内存空间。它将大块显存划分成小块并按需分配的做法有效解决了内部碎片和外部碎片,因为每块只存放固定数量(block size,这个值默认是16)的 token,对于每个 request,最多只会浪费 block size-1 个 token 所需的空间。另外,由于它以块的方式存储 KV cache,因此它天然能够以块的粒度实现显存的共享。
page attention原理
初始化阶段,预先分配一大块现存并划分成块,预先分配的空间称之为physical kvcache block,也就是真正存储的空间。每个块称为 Physical block,可以存储 block_size 个 token 所需的 KV cache,并创建块表(Block table)用于将 Logical KV cache blocks(每个块称为 Logical block,用于存储 token 值) 映射到 Physical KV cache blocks。
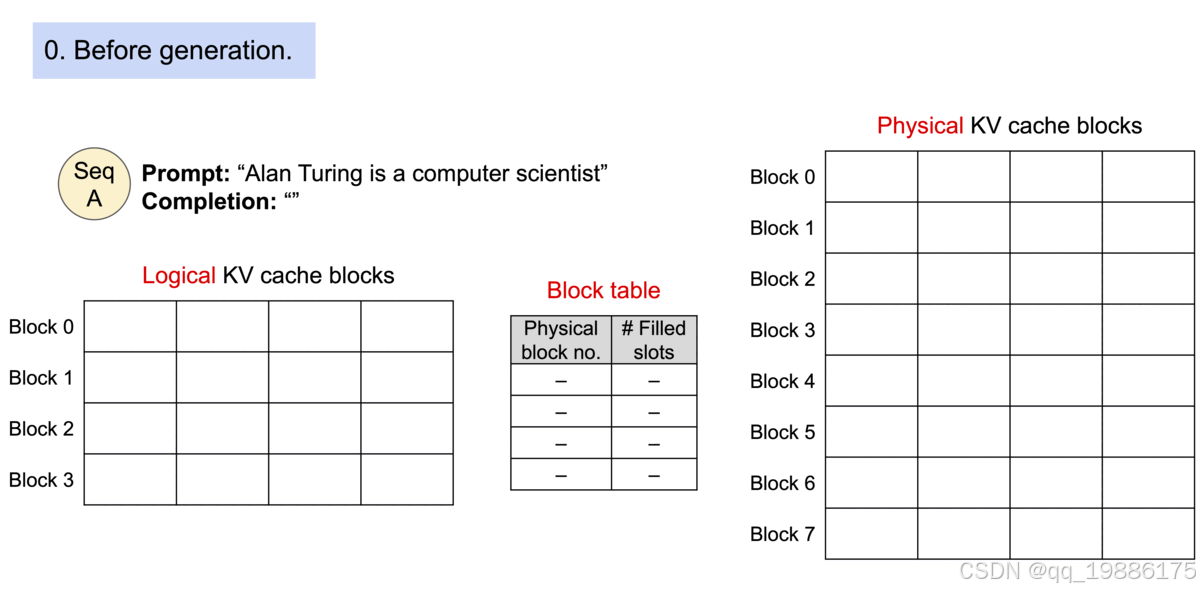
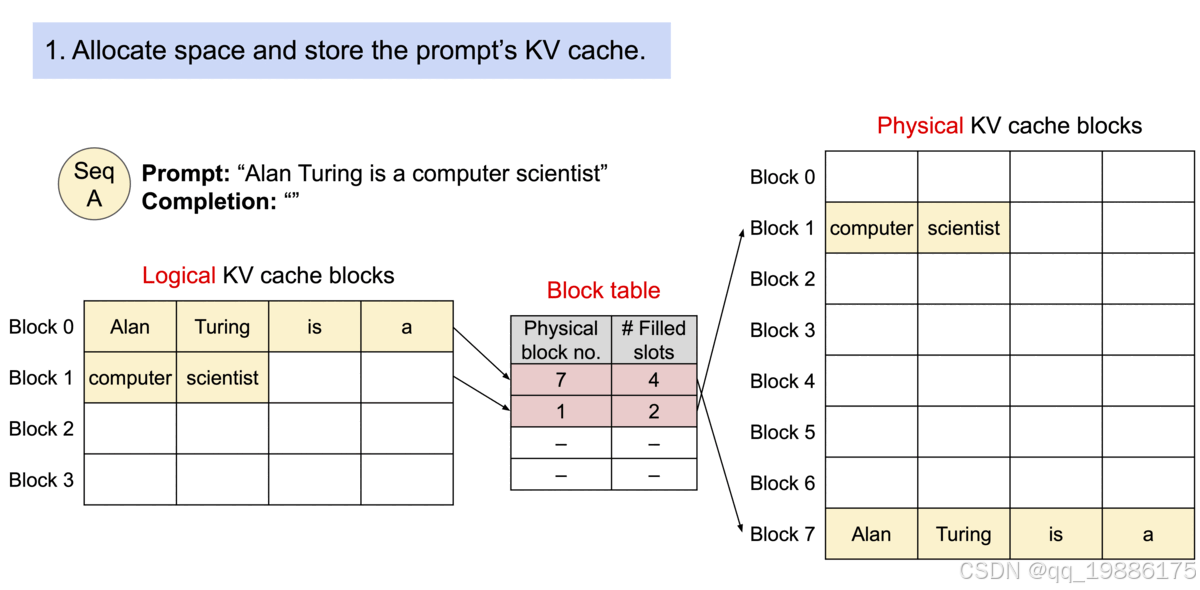
假设收到的prompt是"Alan Turing is a computer scientist",它为该请求分配 Logical KV block 以及 Physical KV cache block,并通过块表将两者关联在一起。“Alan Turing is a” 逻辑上存储在 Logical KV cache blocks 中的 Block 0,实际上是被存储在 Physical KV cache block 的 Block 7,两者通过块表关联在一起,其中 Filled slots 表示该 块已存储的 token 数。
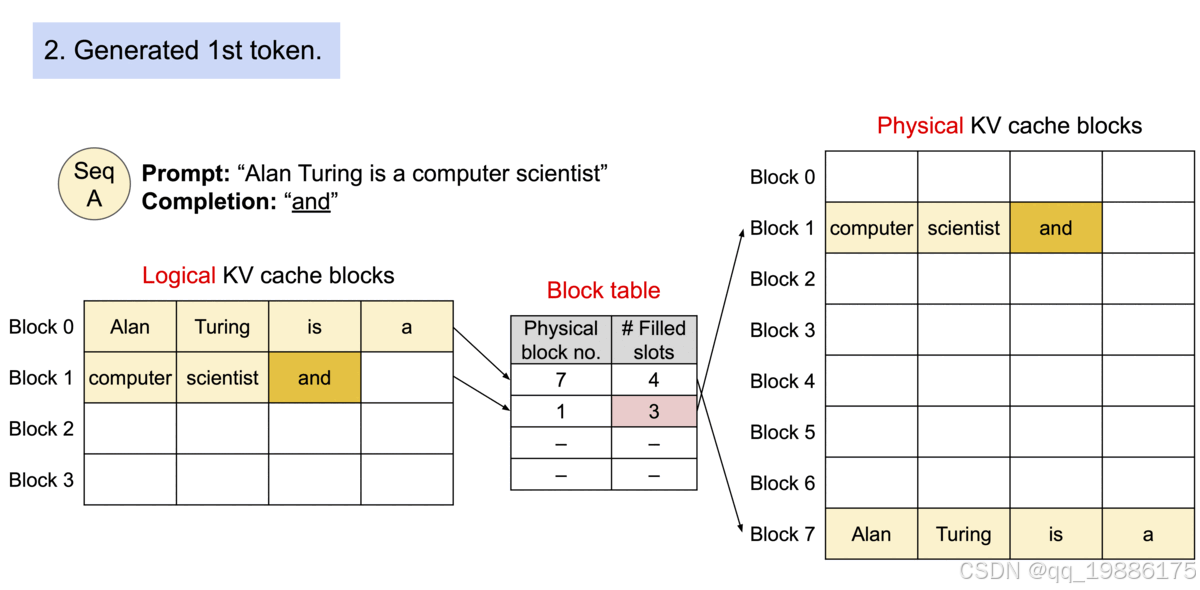
接下来,开始生成第一个 token “and”,它存储在 Logical KV cache blocks 的 Block 1,实际存储在 Physical KV cache block 的 Block 1,同时更新 Filled slots 为 3,如下图
然后以此类推…每次都会更新block table、logical kvcache blocks 和physical kvcache blocks
等到这个block1存储满了后我们在给这个分配block2,block3
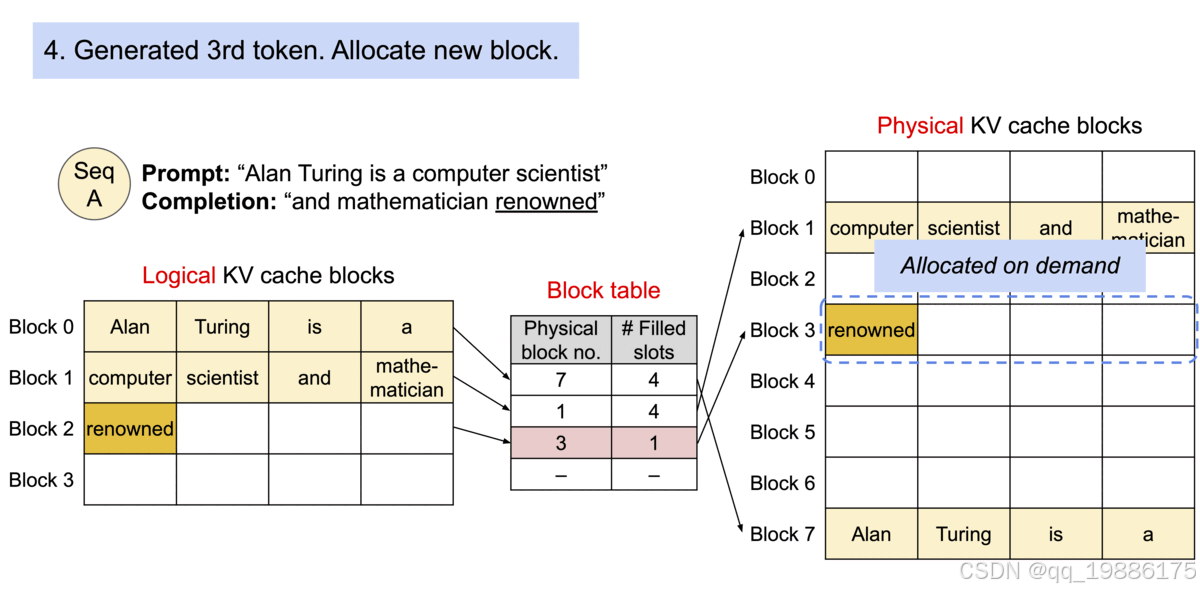
那么接下来我们看看如何解决parallel sampling、beam search 以及 shared prompt 涉及的共享问题。
parallel sampling 为一个 prompt 提供多个输出,便于用户选择其中一个。
其实我们在gpt4o中经常会出现输入一个prompt然后得到2个output,然后让我们选择prefer like 的情况,这就是parallel sampling。其内部细节如下:
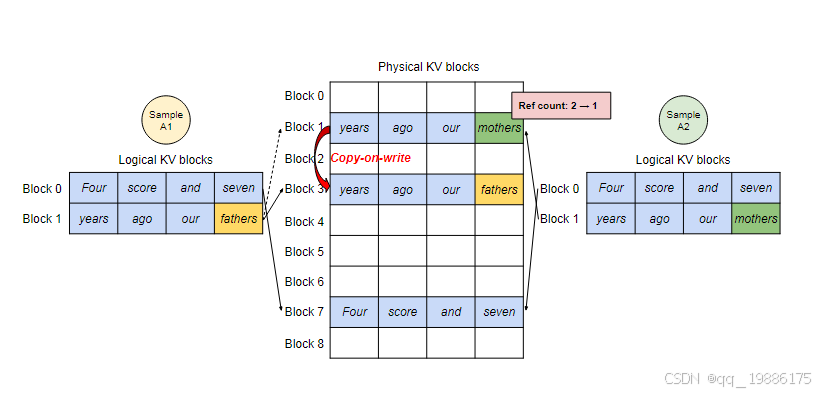
假设样本 A1 和样本 A2 来自于同一个 promot 的不同输出,其 prompt 为 “Four score and seven years ago our”,它们的 Logical KV blocks 分别为各自的 Block 0 和 Block1,paged attention 只会为他们存储一份共享的physcial kv blocks,由于一个physical block 可能会对应多个logical block,所以需要为每个physical block 引入reference count来记录该block 对应的logical block数量。PagedAttention 采用写入时复制(copy-on-write)机制来处理共享问题,即只有发生写入操作时才产生拷贝操作。当 parallel sampling 开始生成下一个 token 时,假设下一个 token 分别为 “fathers” 和 “mothers”,样本 A1 将 “fathers” 写入到最后一个 Logical block 1 后,正打算将 “fathers” 对应的 KV cache 写入到 Physical block 1 时,PagedAttention 意识到 Physical block 1 的 reference count 为 2,因此它需先将 Physical Block 1 的内容拷贝到新的 Block 3 并将 Block 1 的 reference count 减 1,再将 “fathers” 对应的 KV cache 写入到 Physical block 3 。
beam search
beam search是对贪心策略的一个改进,就是微放宽一些考察的范围。在每一个时间步,不再只保留当前分数最高的1个输出,而是保留num_beams个。当num_beams=1时集束搜索就退化成了贪心搜索。
下图是一个实际的例子,每个时间步有ABCDE共5种可能的输出,即,图中的num_beams=2,也就是说每个时间步都会保留到当前步为止条件概率最优的2个序列。
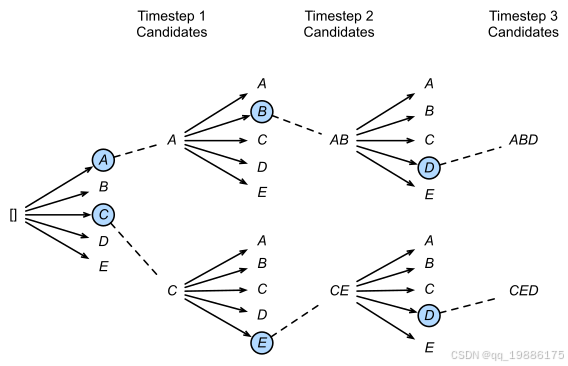
在第一个时间步,A和C是最优的两个,因此得到了两个结果[A],[C],其他三个就被抛弃了;
第二步会基于这两个结果继续进行生成,在A这个分支可以得到5个候选人,[AA],[AB],[AC],[AD],[AE],C也同理得到5个,此时会对这10个进行统一排名,再保留最优的两个,即图中的[AB]和[CE];
第三步同理,也会从新的10个候选人里再保留最好的两个,最后得到了[ABD],[CED]两个结果。
可以发现,beam search在每一步需要考察的候选人数量是贪心搜索的num_beams倍,因此是一种牺牲时间换性能的方法。
参考:
https://zhuanlan.zhihu.com/p/680153425
https://zhuanlan.zhihu.com/p/681716326

















 472
472

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









