







朴素贝叶斯算法:
基本前提:
输入空间X,输出空间Y。
训练集T={(x,y)}中的样本由P(X,Y)独立同分布产生。
这里很多人在学概率论的时候可能不知道什么叫 独立同分布。
这里独立的意思是每次抽样互不影响。好比掷骰子,每次掷骰子互不影响。
同分布是指每次抽样的样本服从同一个概率分布。
朴素贝叶斯做出了一个比较强的假设,即公式:
特征向量X为N维时,
p(X=x|Y=y)=P(X(第一个位置)=x1|y)P(X(第二个位置)=x2|y)…
*P(X(第N个位置)=xn|y)
朴素贝叶斯算法的目的是分类,所以给定一个输入X,由贝叶斯公式计算其可能属于哪个类。
所以问题转化为将概率最大化:
P(Y=yk|X=input)=P(X=input|Y=yk)*P(yk)/Σ{K}P(X=input|Y=yk)P(Y=yk)。
对于Y的取值空间中的值,哪一个带入这个公式的概率最大,那么输入属于这个类的概率就最大。就判定为输入属于这个类。求解时,将上面的假设公式带入求解。
问题:为什么是这样求解?
该算法原理简单,直观理解也很容易,下面从公式方面推导。
在机器学习中,我们模型学习的目的往往是风险最小化。
首先对于期望E(g(x))=Σg(x)*p(g(x))
我们定义 损失函数L(y,f(x))=0 if X=input and y=f(x) ,else 1
则我们的目标是最小化损失函数L。
在机器学习中,这常常等价于求其期望的最小值,即minE(L)
而L是一个条件取值,所以
E(L(y,f(x)))=ΣL(y,f(x))*P(y=yk|X=input)
后面:
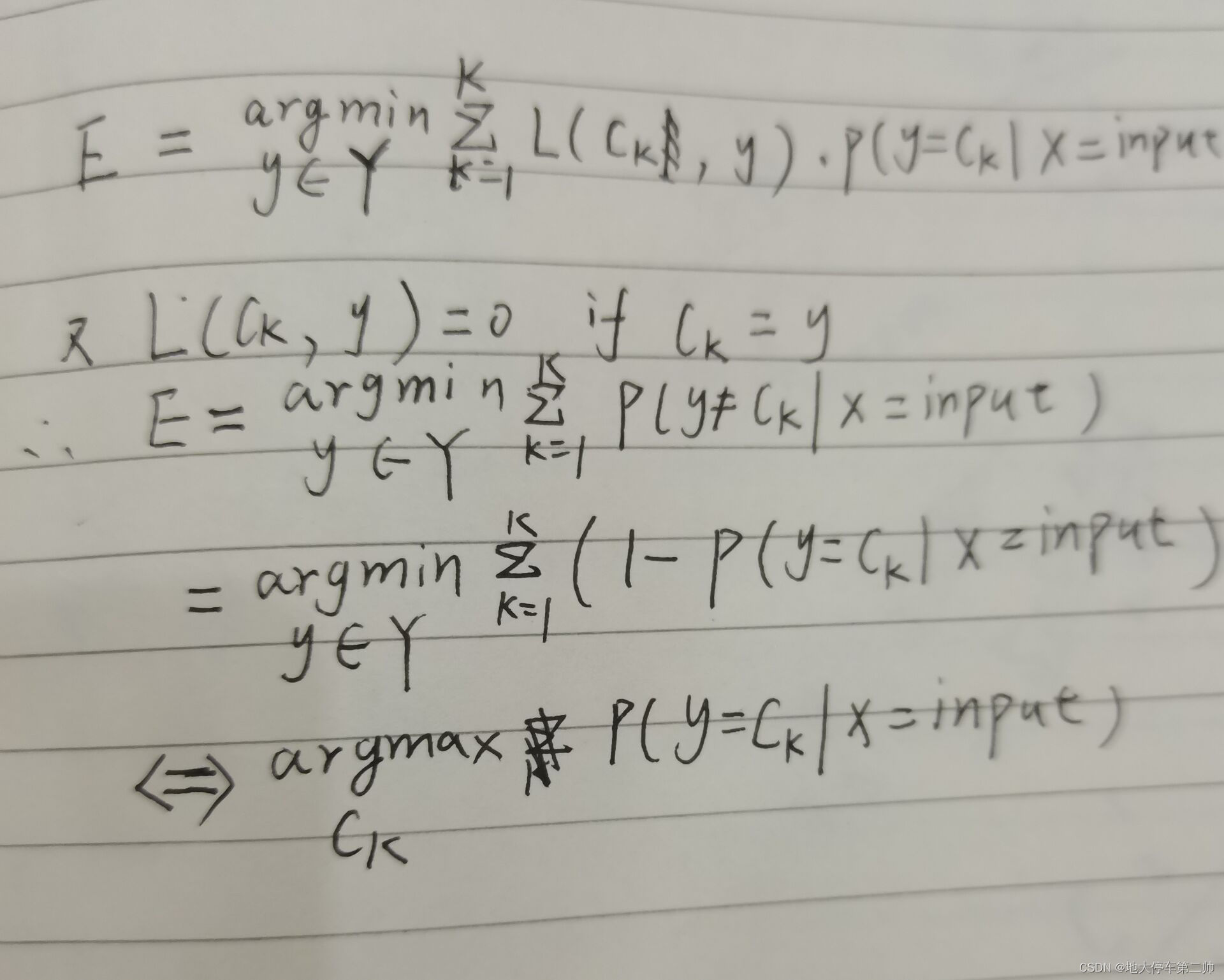
*
朴素贝叶斯的最大似然估计:
朴素贝叶斯算法中需要知道两个因素:
P(Y=ck),P(X(j)=x(j)|Y=ck)
朴素贝叶斯算法中采用最大似然估计。
在《统计自然语言处理》专栏第一章中知道,最大似然估计就是用频率近似概率。所以这两个参数都是从训练集中学习,利用训练集中各个变量取值的频率去计算。
贝叶斯估计
在利用频率近似概率时,难免会出现某一特征取值在训练集中恰好未出现的情况,这会使得其对应的条件概率为0,但这并不代表该情况在非训练集中不会出现,因此会引发结果偏差。为了解决这一问题,引入了贝叶斯估计。
即对于需要估计的两个参数,分子分别加一个参数λ,分母分别加参数K*λ和S(J)*λ
*















 407
407











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









