







引言
这片博文内容主要基于2015年Y Li的论文Video Description Generation Incorporating Spatio-Temporal Features and a Soft-Attention Mechanism,本文将soft-attention机制引入到视频描述中。
视频特征提取采用一个用动作识别视频集训练的3-D CNN网络,之后利用soft-attention机制来加权确定输入到RNN/LSTM的特征向量,之后Decoder得到视频描述。整个模型简单概括为下图
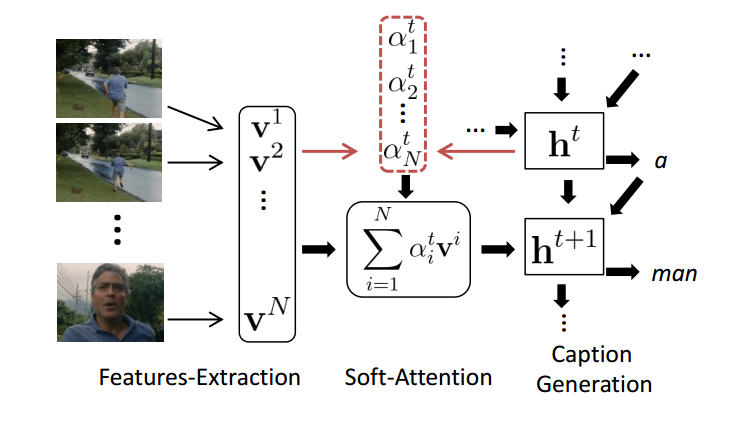
模型
视频描述可以看做对于视频 V 得到描述
p(c1,c2,...,cD|V)=p(c1
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 722
722











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









