







这篇文章是深度学习应用在视频分析领域的经典文章,也是Encoder-Decoder模型的经典文章,作者是多伦多大学深度学习开山鼻祖Hinton教授的徒子徒孙们,引用量非常高,是视频分析领域的必读文章。
摘要翻译
我们使用长短时记忆(Long Short Term Memory, LSTM)网络来学习视频序列的表征。我们的模型使用LSTM编码器将输入序列映射到一个固定长度的表征向量。之后我们用一个或多个LSTM解码器解码这个表征向量来实现不同的任务,比如重建输入序列、预测未来序列。我们对两种输入序列——原始的图像小块和预训练卷积网络提取的高层表征向量——都做了实验。我们探索不同的设计选择,例如解码器的LSTM是否应该取决于生产的输出。我们定量地分析模型的输出来探讨学习模型对过去和未来视频序列的表征能力。我们通过监督学习任务——UCF101和HMDB-51数据集动作识别——微调学习的表征向量来进一步评估表征能力。我们发现这些表征提高了分类准确度,尤其是当只有少量训练样本的情况下。即使模型通过不相关的数据集(300 hours of YouTube videos)预训练,也能够提高动作识别的性能。
模型描述
LSTM Autoencoder Model
模型中有两个递归神经网络,编码器LSTM和解码器LSTM,如下图。模型的输入是向量序列(图像小块或者特征向量)。当最后一个输入被读入之后,编码器的内部状态和输出状态将会被直接给入decoder。Decoder输入目标序列或者预测序列,目标序列是和输入序列一样的,只不过在顺序上是反向,把顺序反向可以使得优化更简单因为LSTM的输出就是反过来的嘛。解码器decoder既可以是有条件约束的也可以是无条件约束的。有条件约束的decoder就是decoder接受生成的最后一帧作为输入,即下图中的虚线框。无条件约束的decoder就不接受这个输入。
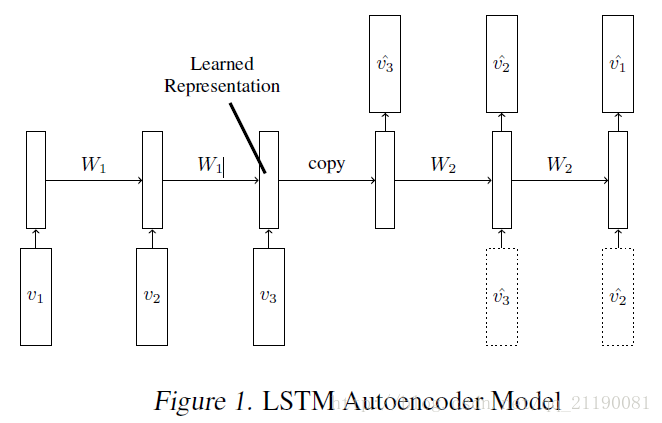
在encoder读入最后视频最后一帧之后LSTM的状态就是输入视频的表征。因为decoder就是需要用到这个表征向量来重建序列,所以这个表征向量需要包含目标、背景以及运动等信息。但是所有自编码器结构的模型都面临着一个问题,就是直接把输入和输出进行对比来实
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1622
1622











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









