









ICCV 2015
project page http://www.cs.cmu.edu/~xiaolonw/unsupervise.html
code https://github.com/xiaolonw/caffe-video_triplet
这篇文章最大的亮点是 CNN 的 Unsupervised Learning。以前的CNN网络参数学习需要海量标定的数据,例如 ImageNet,本文提出使用没有标定的视频来学习 CNN网络。
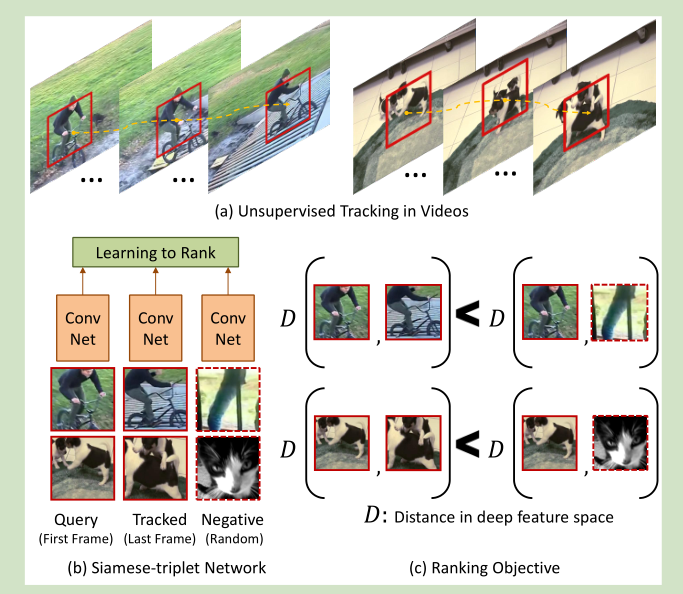

我们利用视频跟踪技术提取视频中对应的图像块,对应的图像块一般属于同一个物体,它们之间的相似性比较大,尤其是与随机对应的图像相比较而言。
所以我们的CNN网络为三元结构,两个相关样本和一个负样本。三个样本用于学习相似性。
4 Patch Mining in Videos
给定一个视频,我们希望运动的图像块,然后跟踪这些图像块,从而得到训练样本,这里我们通过两个步骤来实现:1)SURF提取特征点,然后使用 IDT【50】来过滤特征点。2)我们用一个固定尺寸的框,通过移动框,选择包含最多特征点的位置的框。将该图像块作为运动图像块。使用KCFtracker【19】进行跟踪,30帧后的图像块作为对应的图像块。

5 Learning Via Videos
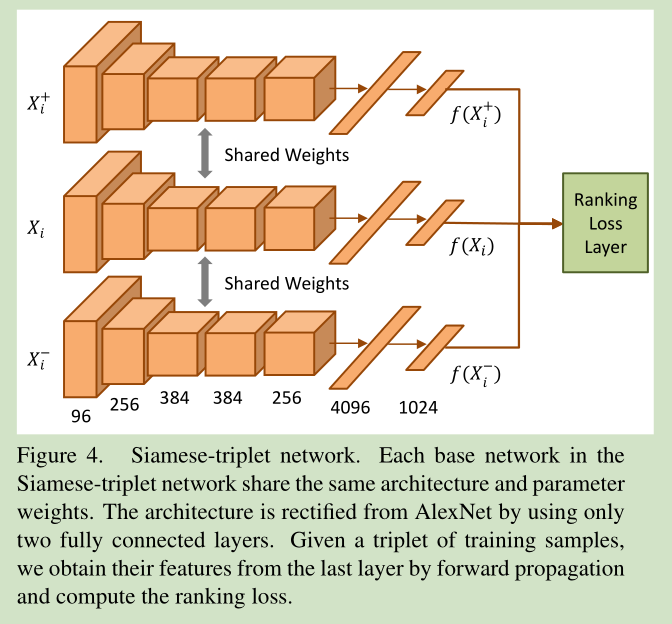
网络结构如下:
5.2. Ranking Loss Function
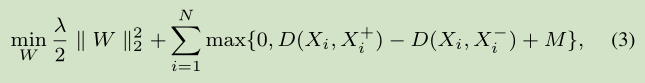
5.3. Hard Negative Mining for Triplet Sampling
Random Selection
HardNegativeMining
5.4. Adapting for Supervised Tasks
fine-tune
















 9536
9536

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









