







【论文阅读】VideoLSTM Convolves, Attends and Flows for Action Recognition
这篇文章的主要贡献是在 Attention LSTM的基础上引入了 conv-lstm。文章将这种 conv-lstm +attention的结构称为 VideoLSTM。文章中生成 attention map 的方法 与 ALSTM也不完全一样,博客中也会介绍一下。
前言
我们知道 conv-lstm 是在15年提出用于预测天气的[1],其结构如下图所示,conv-lstm将传统的lstm的隐藏单元替换为了feature map,并且将hidden到hidden的映射替换成卷积。我们知道传统的 fc-lstm网络中,输入到lstm的是具有抽象语义信息的全连接层特征,所以无论是输入到hidden的映射还是hidden到hidden的映射,都会忽略输入图像中的空间信息。而conv-lstm网络是将feature map 输入到lstm中,feature map 中保留着输入的空间结构信息,所以当前的输入会与历史信息中相同的空间区域进行作用,能够描述不同空间区域的局部变化。同时hidden-hidden的映射采用卷积的方式,在局部运动发生偏移的时候也可以检测到,小的卷积核可以检测到小的行为偏移,大的卷积核可以检测到大的行为偏移。
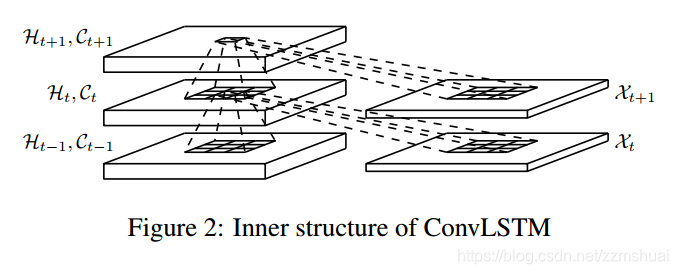
作者将conv-lstm迁移过来应用于人体行为识别,但是这远远不够,所以作者又借鉴了 Attention Lstm 引入了注意力机制,便得到了最终的VideoLSTM网络。
正文
VideoLSTM的网络结构
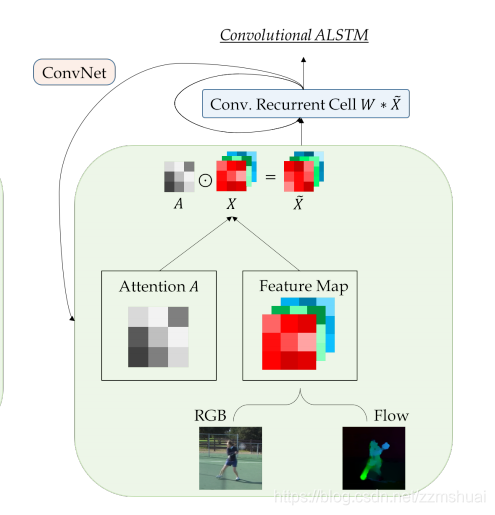
上图展示的是VideoLSTM的基本结构,我们将其拆分后分别来看。
conv-lstm的结构
先看conv-lstm的结构,其公式如下式所示,可以看到与传统的LSTM相比,权重的点积都变成了卷积的形式,其他的输入门、遗忘门等的计算形式并没有变。式(1)~式(4)中的
X
~
t
\tilde{X}_{t}
X~t表示当前输入的feature map 与 attention map 相结合后 输入到 conv-lstm的输入。
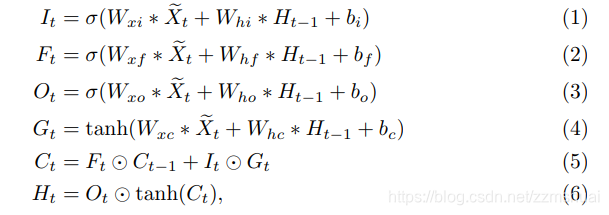
attention map的计算
文章提出了两种计算attention map的方法,一种方法基于RGB输入计算,另一种方法基于光流输入计算。我们分别进行介绍:
- 基于RGB输入的attention map 计算方法
基于RGB输入的attention map的 计算公式如下式(7),(8)所示,我们可以看到(7)中根据输入的feature map 和 前一时刻的hidden计算出当前时刻的权重矩阵,然后对权重矩阵作softmax,如式(8)所示,得到最终的attention map: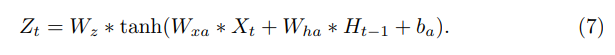
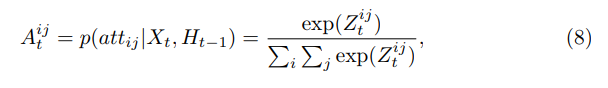
- 基于光流输入的attention map 计算方法
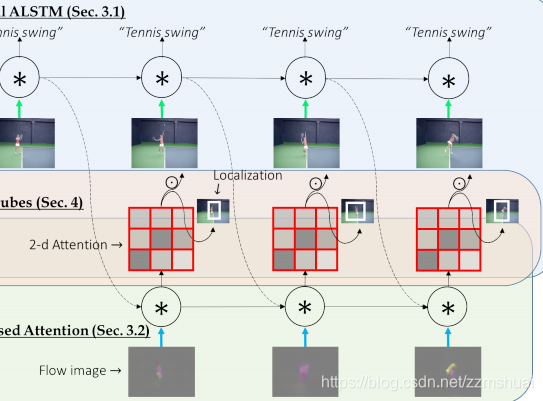
上图中展示了基于光流的attention map 的计算方法,我们知道光流分布在相邻两帧的运动差异的区域,可以认为光流主要分布在当前帧的salient 区域,所以可以使用光流来帮助计算attention map,文章使用一个新的conv-lstm来生成attention map(上图中的绿色区域),这个conv-lstm可以被称为low-conv-lstm,它的当前时刻的hidden用来生成当前时刻的attention map,并且low-conv-lstm只是用来生成attention map。rgb输入的conv-lstm称为top-conv-lstm,可以参与计算最终的输出结果。low-conv-lstm的公式如下式所示,(10)~(13)中可以看到low-conv-lstm的输入为当前帧的光流的feature map,前一帧top-conv-lstm的hidden和前一帧top-conv-lstm的hidden。low-conv-lstm当前时刻的hidden经过一个softmax(如式8)得到当前时刻的attention map。
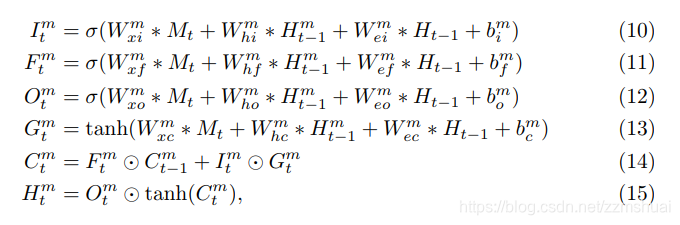
attention map 和 feature map的结合
attention map 和 feature map的结合方式就是如下式所示,简单的 element-wise product,不作过多的解释。

实验细节
文章使用预训练的VGG-16来提取RGB输入和光流输入的feature map,其中光流为x和y的分量的两通道图片,被线性归一化到[0,255]。conv-LSTM中的卷积核尺寸为3x3。所有的隐藏层卷积核的个数为512个。lstm的输出连接一个1024单元的全连接层,全连接层后连接dropout,数值设为为0.7。
在训练的时候,batch size为128, 输入为30帧,学习率为0.001,weight decay 为0.9。
实验结果
在UCF101和hmdb51的实验结果
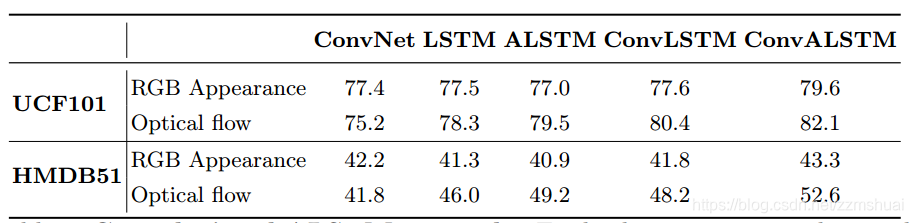
上面是各种网络结构在两个公共数据集上的结果,先分析appearance流,可以看到对于appearance流来说,使用一个简单的卷积网络就可以有效地提取空间信息了,加入了lstm结构以后甚至会对识别效果产生不好的影响。但是在卷积网络的基础上加入attention就不一样,结果就明显地变高了,如果作者的数据是真实的,那么可以明显地看到,对于appearance流来说,conv+attention是非常重要的。
再分析motion流,一般来说,对于ConvNet,光流的输入要比RGB的输入效果要好的,但是这里恰恰相反了,不知为何。不过从表中的数据分析,lstm更适合光流输入,文章认为这是因为光流中不会包含复杂的背景,所以lstm更能关注行为动态变化。而且attention和conv都会对识别结果有所提高。
RGB attention和 光流 attention的对比
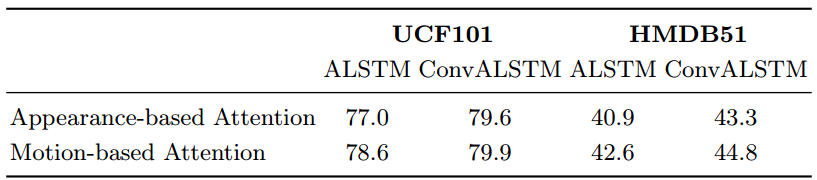
文章之后又比较了ALSTM和ConvALSTM在基于RGB的attention和基于光流的attention的对比实验,纵向对比可以看到,无论是ALSTM还是ConvALSTM,基于光流的attention的效果是高于基于RGB的attention的效果的。横向对比比较可以看到,将lstm替换成convlstm会有利于attention的定位。
与其他lstm模型实验的对比
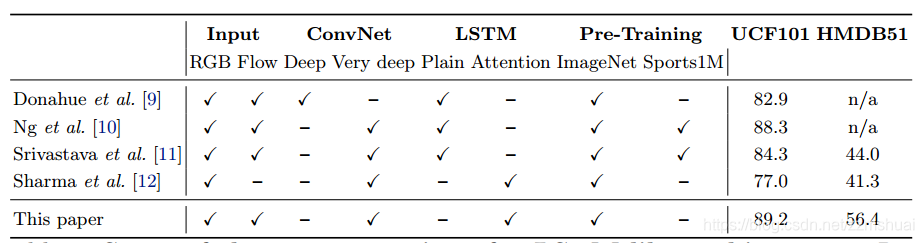
上图是与其他lstm模型实验结果的对比,可以看到本文几乎集齐了之前lstm模型的所有特点,所以也取得了最高的准确率,可以说是站在巨人的肩膀上吧。
与手工特征相融合的实验
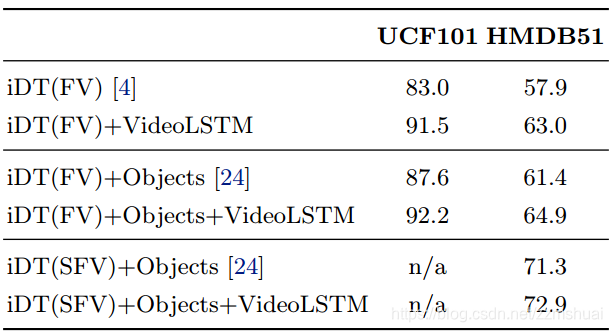
上图是VideoLSTM与传统的手工特征的方法相融合的实验,从实验的结果可以看出,手工特征和VideoLSTM是高度互补的,融合之后的结果提升非常地大,那么LSTM提取的特征和手工idt特征各自有什么特点,为什么会互补呢? 我感觉如果完全摸清了idt特征的特点,并将其融合到端到端的lstm模型中,会使基于lstm的方法有一个质的飞跃
[1] Xingjian, S. H. I., et al. “Convolutional LSTM network: A machine learning approach for precipitation nowcasting.” Advances in neural information processing systems. 2015.














 581
581











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









