









目录标题
第一章:引言
在并发编程中,理解和掌握内存模型(Memory Model)是至关重要的。C++ 提供了一套复杂但强大的工具来处理多线程环境下的内存操作,其中最核心的就是 std::memory_order。本章将简要介绍内存模型的重要性以及 std::memory_order 的角色和意义。
1.1 内存模型的重要性
在并发编程中,多个线程可能会同时访问和修改同一块内存区域。如果没有适当的同步机制,这可能会导致数据竞争(Data Race)和其他并发问题。内存模型定义了如何在多线程环境下安全地访问和修改内存,它规定了线程之间的内存操作如何进行交互,以及它们的执行顺序。
1.2 std::memory_order 的角色和意义
std::memory_order 是一个枚举类型,它定义了几种不同的内存顺序,这些内存顺序可以用于指定 std::atomic 操作的内存语义。在 C++ 中,你可以使用 std::memory_order 参数来指定 std::atomic 操作的内存顺序。这些内存顺序提供了一种灵活的方式来平衡性能和正确性。
以下是 std::memory_order 的几个值:
- std::memory_order_relaxed(松散顺序):不对执行顺序做出任何保证。
- std::memory_order_consume(消费顺序):一个载入操作的后续操作(仅限于依赖于该载入操作的结果的操作)不能被重排到该载入操作之前。
- std::memory_order_acquire(获取顺序):一个载入操作的后续操作(包括对任何变量的读取和写入)不能被重排到该载入操作之前。
- std::memory_order_release(释放顺序):一个存储操作的前序操作(包括对任何变量的读取和写入)不能被重排到该存储操作之后。
- std::memory_order_acq_rel(获取释放顺序):同时包含 std::memory_order_acquire 和 std::memory_order_release 的语义。
- std::memory_order_seq_cst(顺序一致顺序):除了有 std::memory_order_acq_rel 的语义外,还保证了全局的顺序一致性。
为了帮助理解这些概念,下图展示了 C++ 内存模型的主要元素:

第二章:std::memory_order 的详细解析
在这一章节中,我们将详细解析 std::memory_order 的各个值,以及它们在多线程编程中的作用和影响。
2.1 std::memory_order_relaxed (松散顺序)
std::memory_order_relaxed 是最基本的内存顺序。在这种内存顺序下,编译器和处理器可以自由地对操作进行重排,只要保证每个独立的线程中的操作顺序不变即可。这种内存顺序提供了最少的同步,但也是最难正确使用的,因为它不提供跨线程的顺序保证。
std::atomic<int> x(0);
x.store(1, std::memory_order_relaxed); // 可以被重排
2.2 std::memory_order_consume (消费顺序)
std::memory_order_consume 保证了一个载入操作的后续操作(仅限于依赖于该载入操作的结果的操作)不能被重排到该载入操作之前。这种内存顺序主要用于保护数据依赖性,防止编译器和处理器的优化破坏了程序的正确性。
std::atomic<int*> ptr(nullptr);
int data;
ptr.store(&data, std::memory_order_release);
int* res = ptr.load(std::memory_order_consume);
if (res != nullptr) {
// 这里的操作不能被重排到 load 操作之前
do_something(*res);
}
2.3 std::memory_order_acquire (获取顺序)
std::memory_order_acquire 保证了一个载入操作的后续操作(包括对任何变量的读取和写入)不能被重排到该载入操作之前。这种内存顺序常用于实现锁和其他同步原语。
std::atomic<bool> flag(false);
// ...
if (flag.load(std::memory_order_acquire)) {
// 这里的操作不能被重排到 load 操作之前
do_something();
}
2.4 std::memory_order_release (释放顺序)
std::memory_order_release 保证了一个存储操作的前序操作(包括对任何变量的读取和写入)不能被重排到该存储操作之后。这种内存顺序常用于实现锁和其他同步原语。
std::atomic<bool> flag(false);
// ...
do_something();
flag.store(true, std::memory_order_release);
2.5 std::memory_order_acq_rel (获取-释放顺序)
std::memory_order_acq_rel 同时包含了 std::memory_order_acquire 和 std::memory_order_release 的语义。这种内存顺序常用于同时需要获取和释放语义的操作,例如 std::atomic::exchange。
std::atomic<int> x(0);
int old = x.exchange(1, std::memory_order_acq_rel);
2.6 std::memory_order_seq_cst (顺序一致性)
std::memory_order_seq_cst 是最严格的内存顺序。它不仅包含了 std::memory_order_acq_rel 的语义,还保证了全局的顺序一致性。这是默认的内存顺序,也是最易于理解和使用的内存顺序。
std::atomic<int> x(0);
x.store(1); // 默认就是 std::memory_order_seq_cst
以下是一个简单的表格,总结了这些内存顺序的主要特性:
| 内存顺序 | 描述 |
|---|---|
| std::memory_order_relaxed | 不对执行顺序做出任何保证 |
| std::memory_order_consume | 一个载入操作的后续操作(仅限于依赖于该载入操作的结果的操作)不能被重排到该载入操作之前 |
| std::memory_order_acquire | 一个载入操作的后续操作(包括对任何变量的读取和写入)不能被重排到该载入操作之前 |
| std::memory_order_release | 一个存储操作的前序操作(包括对任何变量的读取和写入)不能被重排到该存储操作之后 |
| std::memory_order_acq_rel | 同时包含 std::memory_order_acquire 和 std::memory_order_release 的语义 |
| std::memory_order_seq_cst | 除了有 std::memory_order_acq_rel 的语义外,还保证了全局的顺序一致性 |
为了更好地理解这些内存顺序,我们可以参考以下的图示:

第三章:std::memory_order 在 std::atomic 操作中的应用
在本章中,我们将深入探讨 std::memory_order 在 std::atomic 操作中的应用。我们将通过一个综合的代码示例来展示如何在实际编程中使用 std::memory_order。
3.1 如何选择正确的 memory_order
选择正确的 memory_order(内存顺序)是至关重要的,因为它可以影响程序的性能和正确性。以下是一些关于如何选择 memory_order 的建议:
-
如果你不确定应该使用哪种
memory_order,那么你应该使用std::memory_order_seq_cst。这是默认的memory_order,它提供了最强的顺序保证。 -
如果你需要更高的性能,并且你能确保你的代码在更宽松的
memory_order下仍然正确,那么你可以考虑使用std::memory_order_relaxed、std::memory_order_consume、std::memory_order_acquire或std::memory_order_release。 -
如果你的代码涉及到多个
std::atomic变量,并且这些变量之间存在依赖关系,那么你可能需要使用std::memory_order_acq_rel。
3.2 std::atomic 操作的内存语义
std::atomic 提供了一种方式来执行原子操作,这些操作在多线程环境中是安全的。std::atomic 操作的内存语义可以通过 memory_order 参数来指定。
以下是一个使用 std::atomic 和 std::memory_order 的代码示例:
#include <atomic>
#include <thread>
std::atomic<int> counter(0);
void increment() {
counter.fetch_add(1, std::memory_order_release);
}
void print() {
int expected = 1;
while (!counter.compare_exchange_strong(expected, 0, std::memory_order_acquire)) {
expected = 1;
}
std::cout << "Counter: " << counter << std::endl;
}
int main() {
std::thread t1(increment);
std::thread t2(print);
t1.join();
t2.join();
return 0;
}
在这个示例中,我们有两个线程:一个线程增加计数器的值,另一个线程打印计数器的值。我们使用 std::memory_order_release 来确保增加计数器的操作在打印操作之前完成,使用 std::memory_order_acquire 来确保打印操作在增加计数器的操作之后开始。
以下是一个对应的内存顺序的示意图:
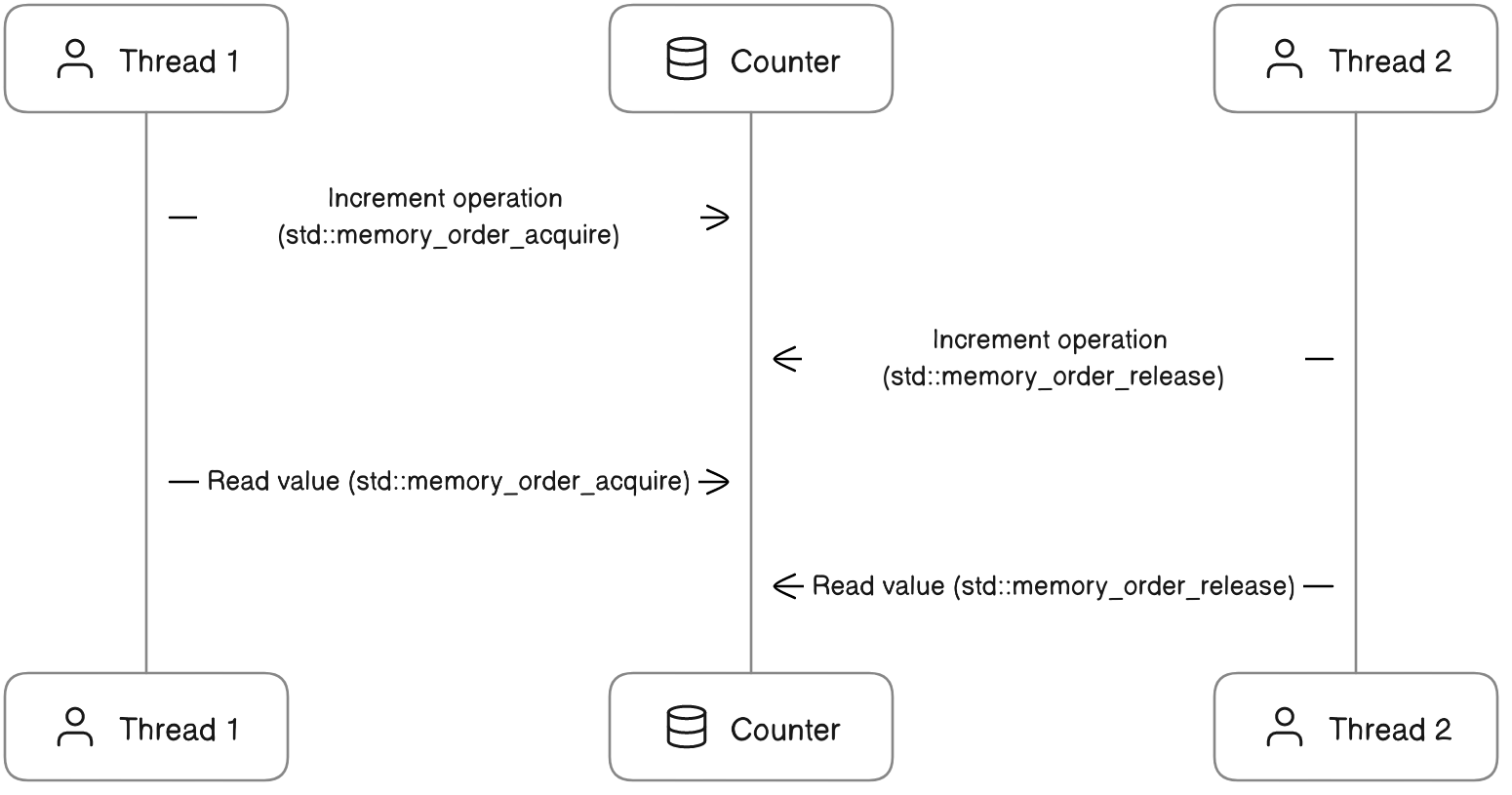
在这个图中,我们可以看到两个线程如何通过 std::memory_order_acquire 和 std::memory_order_release 来协调它们的操作顺序。
第四章:std::memory_order 的实际应用案例
在这一章节中,我们将深入探讨 std::memory_order 在实际应用中的使用。我们将通过一个具体的并发数据结构的实现来展示如何使用 std::memory_order,并解释其背后的原理。
4.1 使用 std::memory_order 实现高效的并发数据结构
假设我们正在实现一个并发队列,其中包含两个主要操作:入队(enqueue)和出队(dequeue)。为了保证这两个操作的线程安全性,我们需要使用 std::atomic 和 std::memory_order。
首先,我们定义队列的节点结构:
struct Node {
std::atomic<Node*> next;
int value;
};
在这个结构中,next 是一个指向下一个节点的 std::atomic 指针。我们使用 std::atomic 是因为在多线程环境中,next 指针可能会被多个线程同时访问和修改。
接下来,我们看一下入队操作的实现:
void enqueue(int value) {
Node* newNode = new Node{nullptr, value};
Node* oldTail = tail.load(std::memory_order_relaxed);
oldTail->next.store(newNode, std::memory_order_release);
tail.store(newNode, std::memory_order_relaxed);
}
在这个函数中,我们首先创建一个新的节点,并将其 next 指针设置为 nullptr。然后,我们使用 std::memory_order_relaxed 语义来载入 tail 指针的值,然后使用 std::memory_order_release 语义来存储新节点的地址到 oldTail->next。最后,我们更新 tail 指针。
这里,我们使用 std::memory_order_release 语义来确保在更新 next 指针之前,新节点的初始化操作(即 new Node{nullptr, value})不会被重排。这是因为 std::memory_order_release 语义保证了一个存储操作的前序操作(包括对任何变量的读取和写入)不能被重排到该存储操作之后。
接下来,我们看一下出队操作的实现:
int dequeue() {
Node* oldHead = head.load(std::memory_order_relaxed);
Node* nextNode = oldHead->next.load(std::memory_order_acquire);
if (nextNode != nullptr) {
head.store(nextNode, std::memory_order_relaxed);
return oldHead->value;
} else {
throw std::runtime_error("Queue is empty");
}
}
在这个函数中,我们首先使用 std::memory_order_relaxed 语义来载入 head 指针的值,然后使用 std::memory_order_acquire 语义来载入 oldHead->next 的值。如果 nextNode 不为 nullptr,我们就更新 head 指针,并返回 oldHead->value。否则,我们抛出一个异常表示队列为空。
这里,我们使用 std::memory_order_acquire 语义来确保在读取 oldHead->value 之前,oldHead->next 的载入操作不会被重排。这是因为 std::memory_order_acquire 语义保证了一个载入操作的后续操作(包括对任何变量的读取和写入)不能被重排到该载入操作之前。
通过这个并发队列的实现,我们可以看到 std::memory_order 在实际应用中的重要性。正确的使用 std::memory_order 可以帮助我们实现高效且线程安全的并发数据结构。
下图展示了在两个线程中进行入队和出队操作的顺序关系:
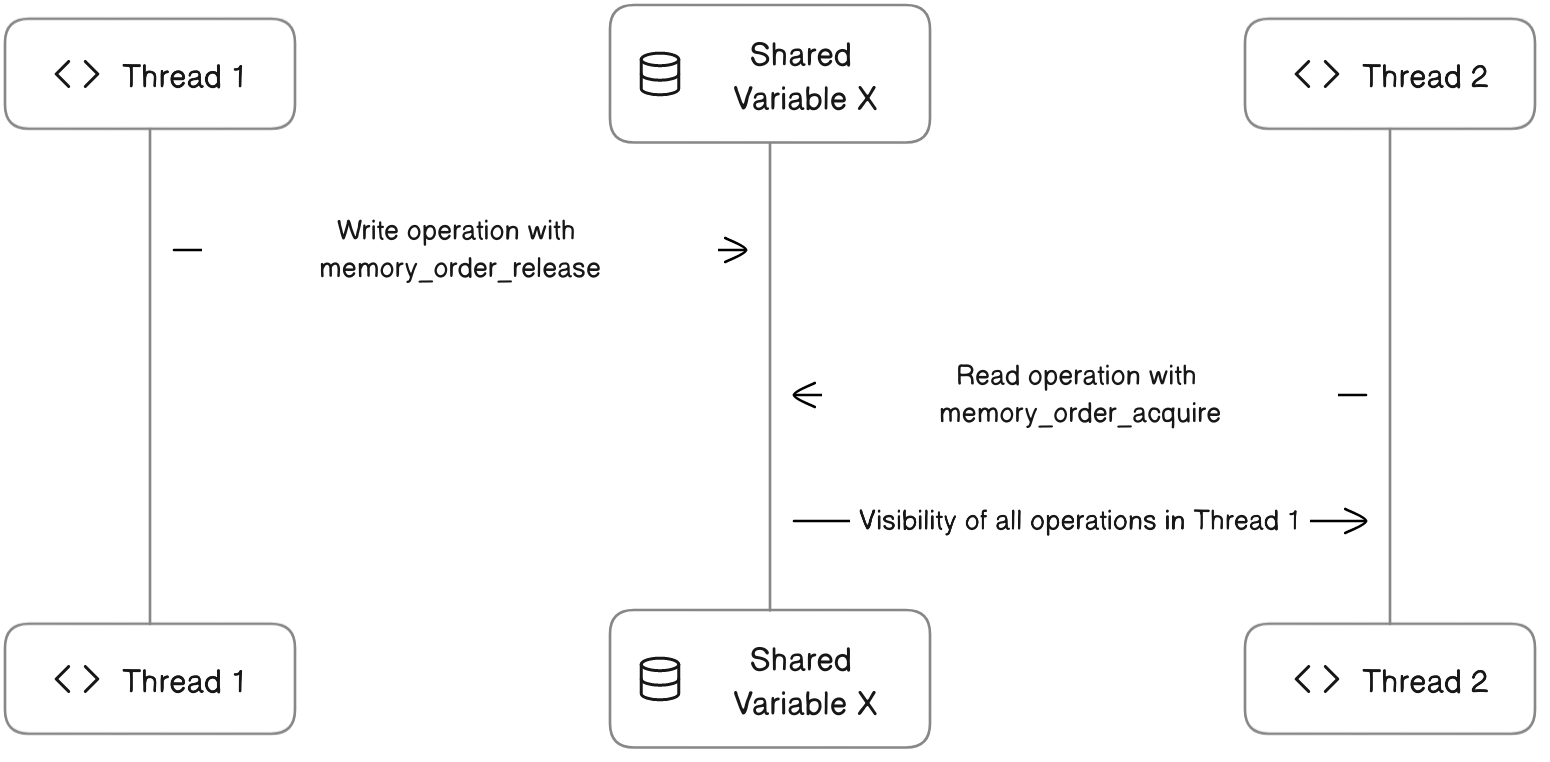
在这个图中,线程1执行了一个对共享变量X的写操作,使用了 memory_order_release,线程2对同一个共享变量X执行了读操作,使用了 memory_order_acquire。箭头表示的是“发生在之前”的关系,这确保了在线程1中在X的写操作之前的所有操作(读/写),在线程2读取X之后都是可见的。
4.2 std::memory_order 在性能优化中的应用
在多线程编程中,正确地使用 std::memory_order 不仅可以帮助我们实现线程安全的代码,还可以在某些情况下提高代码的性能。
例如,当我们在多个线程之间共享一个数据结构,并且这个数据结构的更新操作比读取操作更频繁时,我们可以使用 std::memory_order_acquire 和 std::memory_order_release 来减少不必要的内存屏障,从而提高代码的性能。
在这种情况下,我们可以将数据结构的更新操作定义为 std::memory_order_release,并将读取操作定义为 std::memory_order_acquire。这样,只有在实际需要同步的时候,才会插入内存屏障,从而减少了不必要的性能开销。
这是一个使用 std::memory_order 进行性能优化的例子,实际上,std::memory_order 的应用远不止这些。在实际的编程中,我们需要根据具体的需求和场景,灵活地使用 std::memory_order,以实现高效且线程安全的代码。
第五章:std::memory_order 的注意事项
在使用 std::memory_order 时,我们需要注意一些关键的事项,以避免常见的内存顺序错误。这些错误可能会导致程序的行为变得不可预测,甚至可能导致程序崩溃。在这一章节中,我们将通过一些具体的代码示例来展示如何正确地使用 std::memory_order。
5.1 避免常见的内存顺序错误
5.1.1 错误的 memory_order 使用方式
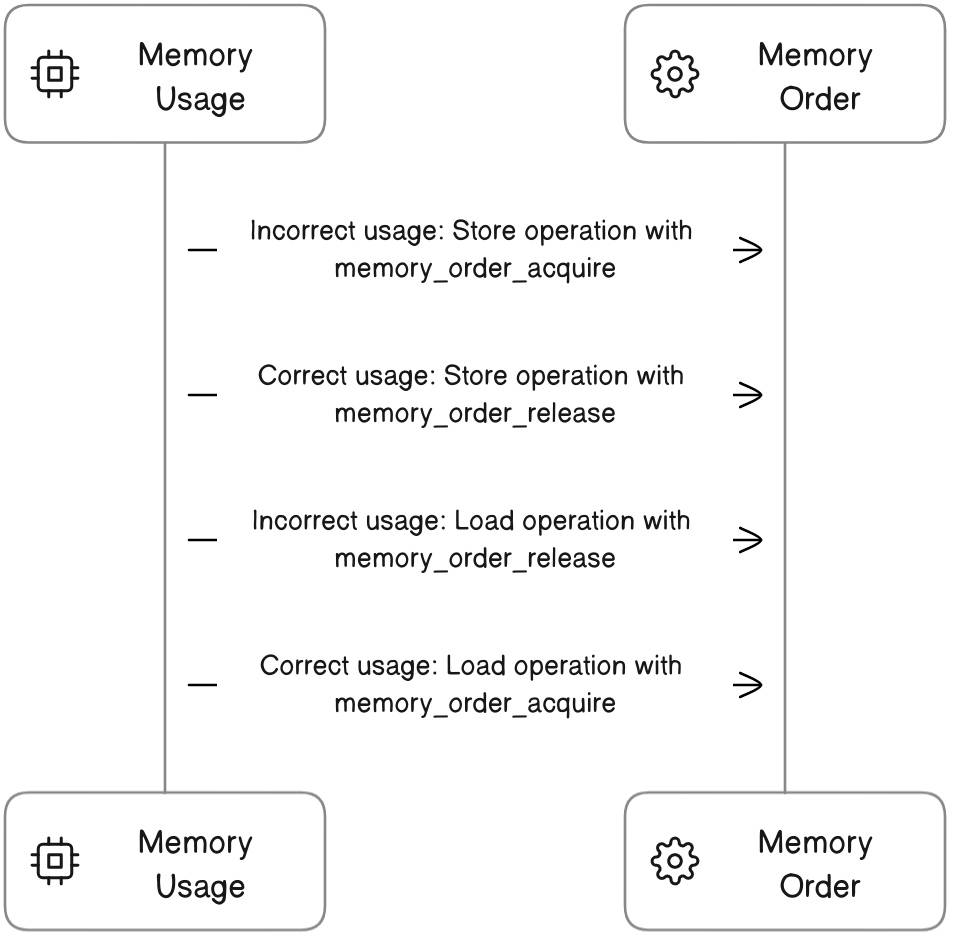
在使用 std::memory_order 时,我们需要确保我们的操作符合 memory_order 的语义。例如,我们不能在存储操作中使用 std::memory_order_acquire,也不能在载入操作中使用 std::memory_order_release。下面是一个错误的使用示例:
std::atomic<int> x(0);
// 错误的使用方式:在存储操作中使用 std::memory_order_acquire
x.store(1, std::memory_order_acquire);
5.1.2 正确的 memory_order 使用方式
相反,我们应该在存储操作中使用 std::memory_order_release,在载入操作中使用 std::memory_order_acquire。以下是一个正确的使用示例:
std::atomic<int> x(0);
// 正确的使用方式:在存储操作中使用 std::memory_order_release
x.store(1, std::memory_order_release);
以下是一个用于理解这个概念的图表:
5.2 如何正确地使用 std::memory_order
在使用 std::memory_order 时,我们需要考虑以下几个关键因素:
-
操作类型:我们需要根据我们的操作是载入操作还是存储操作来选择正确的 memory_order。如上面的示例所示,我们应该在存储操作中使用
std::memory_order_release,在载入操作中使用std::memory_order_acquire。 -
数据依赖:我们需要考虑我们的操作是否有数据依赖。如果有数据依赖,我们可能需要使用
std::memory_order_consume。但是,由于编译器的优化,std::memory_order_consume在实践中往往不会带来预期的效果,因此通常建议使用std::memory_order_acquire。 -
全局顺序一致性:如果我们需要保证全局的顺序一致性,我们应该使用
std::memory_order_seq_cst。但是,这通常会带来一定的性能开销,因此我们应该在确实需要时才使用它。
在实践中,我们通常会使用 std::memory_order_relaxed、std::memory_order_acquire 和 std::memory_order_release,并在需要时使用 std::memory_order_acq_rel 和 std::memory_order_seq_cst。
在下一章节中,我们将通过一些具体的代码示例来展示如何在实际应用中使用 std::memory_order。
结语
在我们的编程学习之旅中,理解是我们迈向更高层次的重要一步。然而,掌握新技能、新理念,始终需要时间和坚持。从心理学的角度看,学习往往伴随着不断的试错和调整,这就像是我们的大脑在逐渐优化其解决问题的“算法”。
这就是为什么当我们遇到错误,我们应该将其视为学习和进步的机会,而不仅仅是困扰。通过理解和解决这些问题,我们不仅可以修复当前的代码,更可以提升我们的编程能力,防止在未来的项目中犯相同的错误。
我鼓励大家积极参与进来,不断提升自己的编程技术。无论你是初学者还是有经验的开发者,我希望我的博客能对你的学习之路有所帮助。如果你觉得这篇文章有用,不妨点击收藏,或者留下你的评论分享你的见解和经验,也欢迎你对我博客的内容提出建议和问题。每一次的点赞、评论、分享和关注都是对我的最大支持,也是对我持续分享和创作的动力。
阅读我的CSDN主页,解锁更多精彩内容:泡沫的CSDN主页




















 1129
1129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











