






赛题名称:用户新增预测挑战赛 赛题类型:数据挖掘、二分类 赛题链接👇: https://challenge.xfyun.cn/topic/info?type=subscriber-addition-prediction&ch=ymfk4uU
赛题背景
讯飞开放平台针对不同行业、不同场景提供相应的AI能力和解决方案,赋能开发者的产品和应用,帮助开发者通过AI解决相关实际问题,实现让产品能听会说、能看会认、能理解会思考。
用户新增预测是分析用户使用场景以及预测用户增长情况的关键步骤,有助于进行后续产品和应用的迭代升级。
赛事任务
本次大赛提供了讯飞开放平台海量的应用数据作为训练样本,参赛选手需要基于提供的样本构建模型,预测用户的新增情况。
赛题数据集
赛题数据由约62万条训练集、20万条测试集数据组成,共包含13个字段。
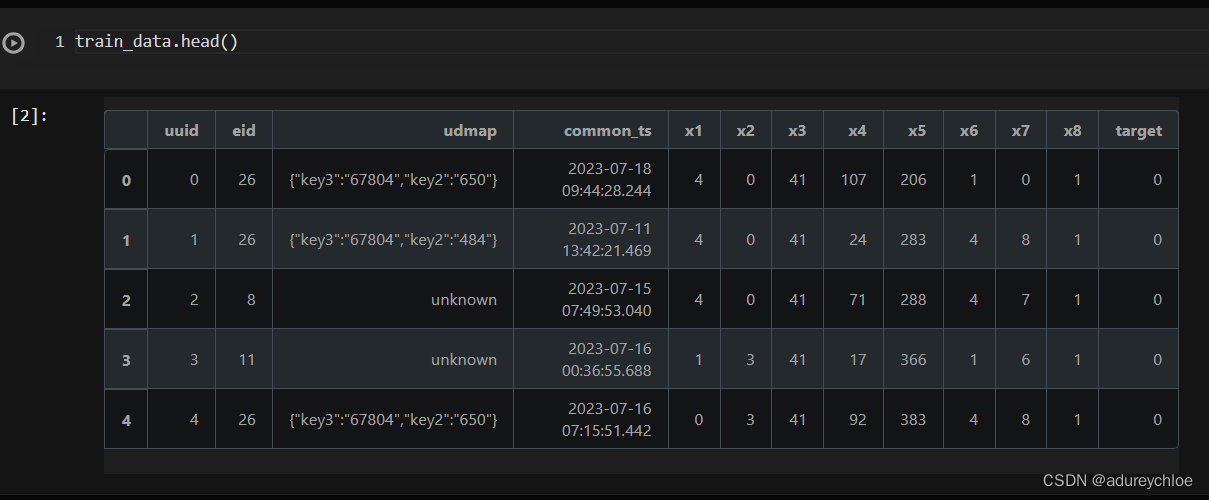
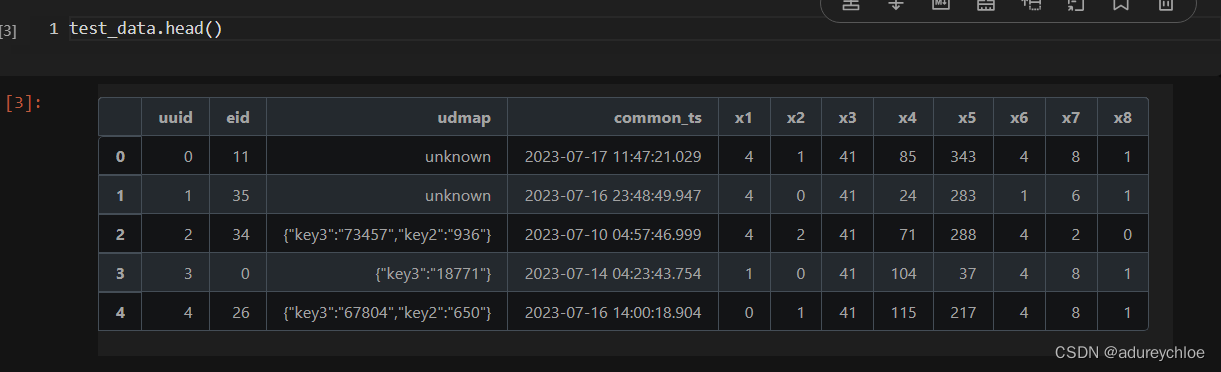
其中uuid为样本唯一标识,eid为访问行为ID,udmap为行为属性,其中的key1到key9表示不同的行为属性,如项目名、项目id等相关字段,common_ts为应用访问记录发生时间(毫秒时间戳),其余字段x1至x8为用户相关的属性,为匿名处理字段。target字段为预测目标,即是否为新增用户。
评价指标
本次竞赛的评价标准采用f1_score,分数越高,效果越好。
赛题思路
赛题是一个典型的数据挖掘的比赛,需要人工提取特征并构建模型,并且特征差异将会带来很大分数差异。
Baseline
导入包并读取数据
import pandas as pd
import numpy as np
train_data = pd.read_csv('用户新增预测挑战赛公开数据/train.csv')
test_data = pd.read_csv('用户新增预测挑战赛公开数据/test.csv')
train_data['common_ts'] = pd.to_datetime(train_data['common_ts'], unit='ms')
test_data['common_ts'] = pd.to_datetime(test_data['common_ts'], unit='ms')
train_data.head()
test_data.head()
特征工程
- udmap_onethot 函数将原始的 udmap 特征进行了预处理,将其转换为一个长度为9的向量,表示每个key是否存在。
def udmap_onethot(d):
v = np.zeros(9)
if d == 'unknown':
return v
d = eval(d)
for i in range(1, 10):
if 'key' + str(i) in d:
v[i-1] = d['key' + str(i)]
return v
train_udmap_df = pd.DataFrame(np.vstack(train_data['udmap'].apply(udmap_onethot)))
test_udmap_df = pd.DataFrame(np.vstack(test_data['udmap'].apply(udmap_onethot)))
train_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
test_udmap_df.columns = ['key' + str(i) for i in range(1, 10)]
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
- 将处理后的 udmap 特征与原始数据拼接起来,形成新的数据框。
train_data = pd.concat([train_data, train_udmap_df], axis=1)
test_data = pd.concat([test_data, test_udmap_df], axis=1)
- 提取 eid 特征的频次(出现次数)和均值,并添加为新的特征。
train_data['eid_freq'] = train_data['eid'].map(train_data['eid'].value_counts())
test_data['eid_freq'] = test_data['eid'].map(train_data['eid'].value_counts())
train_data['eid_mean'] = train_data['eid'].map(train_data.groupby('eid')['target'].mean())
test_data['eid_mean'] = test_data['eid'].map(train_data.groupby('eid')['target'].mean())
- 对 udmap 特征进行编码,生成 udmap_isunknown 特征,表示该特征是否为空。
train_data['udmap_isunknown'] = (train_data['udmap'] == 'unknown').astype(int)
test_data['udmap_isunknown'] = (test_data['udmap'] == 'unknown').astype(int)
- 使用时间戳 common_ts 提取小时部分,生成 common_ts_hour 特征。
train_data['common_ts_hour'] = train_data['common_ts'].dt.hour
test_data['common_ts_hour'] = test_data['common_ts'].dt.hour
决策树模型训练和预测
import lightgbm as lgb
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier()
clf.fit(
train_data.drop(['udmap', 'common_ts', 'uuid', 'target'], axis=1),
train_data['target']
target = clf.predict(test_data.drop(['udmap', 'common_ts', 'uuid'], axis=1)
)
保存预测文件
pd.DataFrame({
'uuid': test_data['uuid'],
'target': target
}).to_csv('submit.csv', index=None)














 121
121











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









