







简介
图是我们现实生活中连接关系的抽象,例如朋友圈、微博的关注关系。图中的很多问题都可以使用深度优先搜索或者广度优先搜索完成,但是不能滥用,因为这两种算法本质上还是暴力算法。我们都知道leetcode上关于图的题其实并不算多,但了解图的知识却非常重要。我曾经用过图数据库做开发,按图的思维去写代码真的很有趣,图可以说是最好玩的数据结构了,接下来就带大家了解一下图的数据结构。
理论基础
图是用来对对象之间的成对关系建模的数学结构,由 顶点(Vertex) 和连接这些顶点的 边(Edge) 组成。图的顶点集合不能为空,但边的集合可以为空。图又可以分为有向图与无向图,即是否区分边的方向。如下图所求:
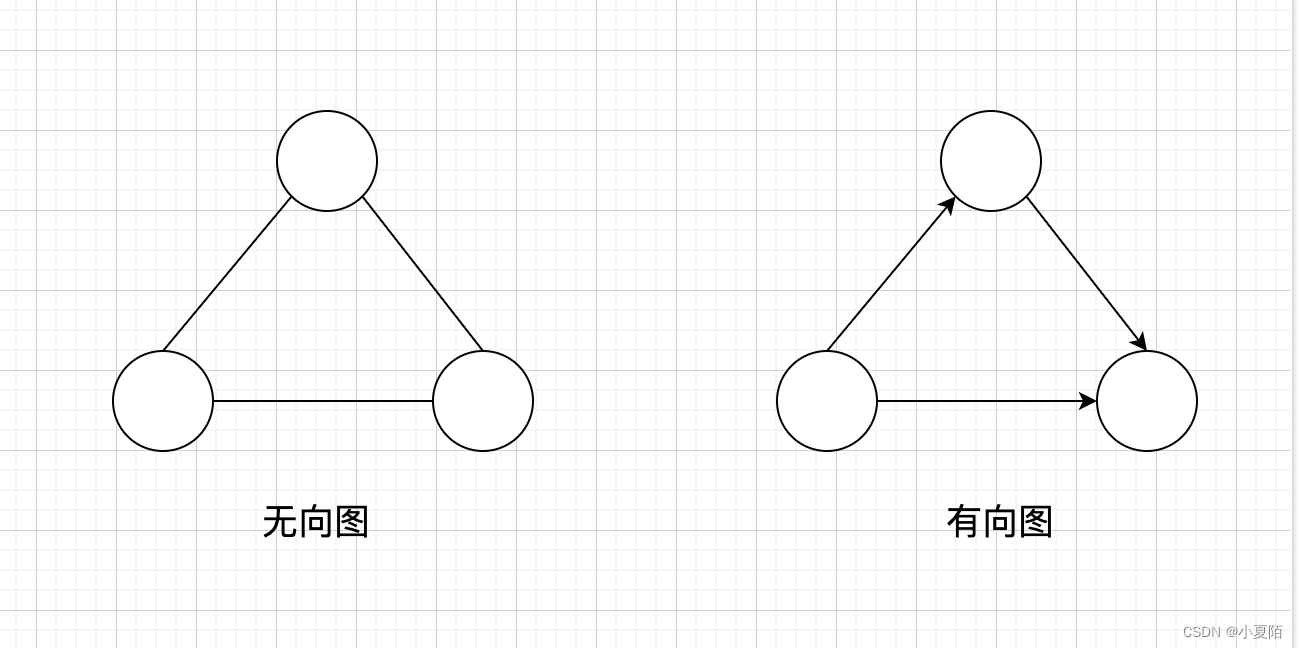
图的表达方式
图有两种:邻接表与邻接矩阵。
- 邻接表只表达和顶点相连接的顶点信息,适合表示稀疏图 (Sparse Graph)。
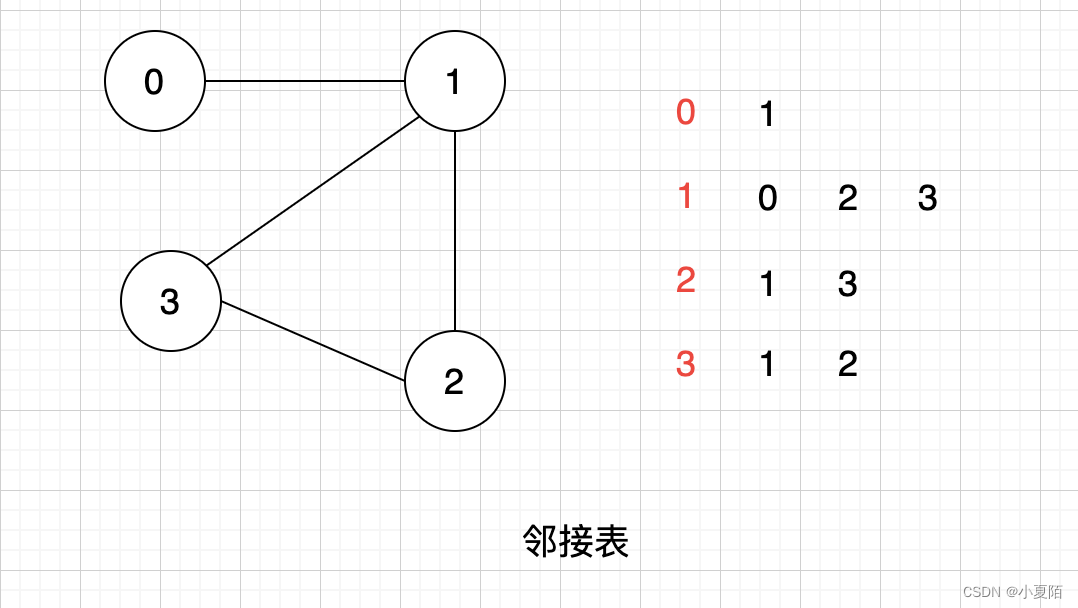
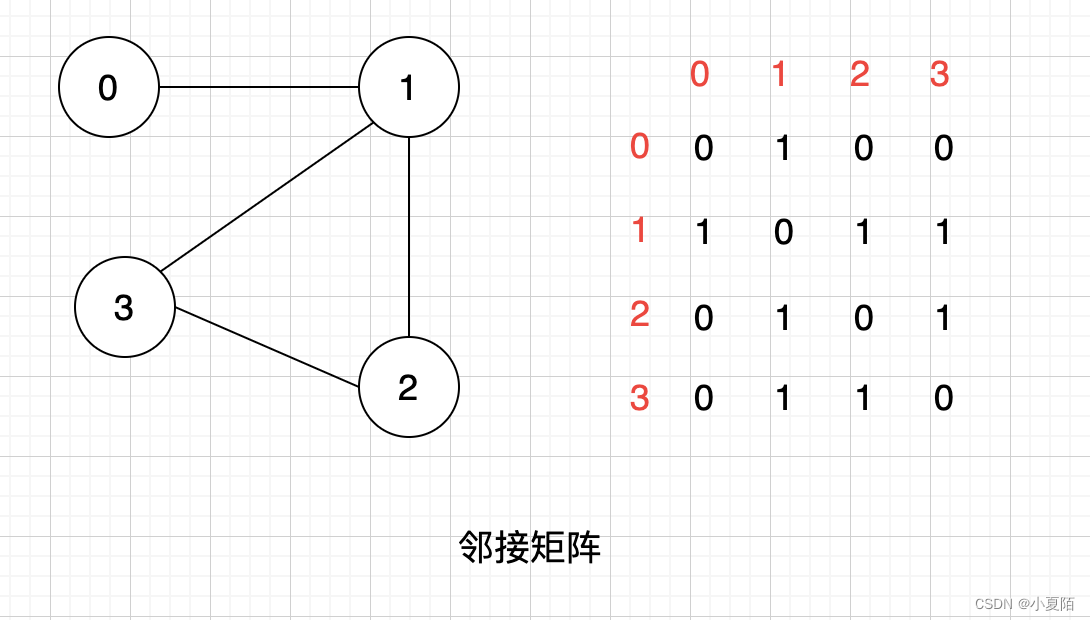
- 邻接矩阵中,用一个矩阵表示图的连接,1表示相连接,0表示不相连,适合表示稠密图 (Dense Graph)
代码实现
接下来用Java分别实现邻接表与邻接矩阵表示的图。
- 邻接表
package runoob.graph; import java.util.List; /** * 邻接表 */ public class SparseGraph { // 节点数 private int n; // 边数 private int m; // 是否为有向图 private boolean directed; // 图的具体数据 private List<Integer>[] g; // 构造函数 public SparseGraph( int n , boolean directed ){ assert n >= 0; this.n = n; this.m = 0; this.directed = directed; // g初始化为n个空的list, 表示每一个g[i]都为空, 即没有任和边 g = (List<Integer>[])new List[n]; for(int i = 0 ; i < n ; i ++) g[i] = new List<Integer>(); } // 返回节点个数 public int V(){ return n;} // 返回边的个数 public int E(){ return m;} // 向图中添加一个边 public void addEdge( int v, int w ){ assert v >= 0 && v < n ; assert w >= 0 && w < n ; g[v].add(w); if( v != w && !directed ) g[w].add(v); m ++; } // 验证图中是否有从v到w的边 boolean hasEdge( int v , int w ){ assert v >= 0 && v < n ; assert w >= 0 && w < n ; for( int i = 0 ; i < g[v].size() ; i ++ ) if( g[v].elementAt(i) == w ) return true; return false; } } - 邻接矩阵
package runoob.graph; /** * 邻接矩阵 */ public class DenseGraph { // 节点数 private int n; // 边数 private int m; // 是否为有向图 private boolean directed; // 图的具体数据 private boolean[][] g; // 构造函数 public DenseGraph( int n , boolean directed ){ assert n >= 0; this.n = n; this.m = 0; this.directed = directed; // g初始化为n*n的布尔矩阵, 每一个g[i][j]均为false, 表示没有任和边 // false为boolean型变量的默认值 g = new boolean[n][n]; } // 返回节点个数 public int V(){ return n;} // 返回边的个数 public int E(){ return m;} // 向图中添加一个边 public void addEdge( int v , int w ){ assert v >= 0 && v < n ; assert w >= 0 && w < n ; if( hasEdge( v , w ) ) return; g[v][w] = true; if( !directed ) g[w][v] = true; m ++; } // 验证图中是否有从v到w的边 boolean hasEdge( int v , int w ){ assert v >= 0 && v < n ; assert w >= 0 && w < n ; return g[v][w]; } }
其它概念
图的分类:无权图和有权图,连接节点与节点的边是否有数值与之对应,有的话就是有权图,否则就是无权图。
图的连通性:在图论中,连通图基于连通的概念。在一个无向图 G 中,若从顶点 i 到顶点 j 有路径相连,则称 i 和 j 是连通的。如果 G 是有向图,那么连接i和j的路径中所有的边都必须同向。如果图中任意两点都是连通的,那么图被称作连通图。如果此图是有向图,则称为强连通图(注意:需要双向都有路径)。图的连通性是图的基本性质。
完全图: 完全图是一个简单的无向图,其中每对不同的顶点之间都恰连有一条边相连,即所有可能的边都存在。
自环边: 一条边的起点终点是同一个点。
平行边: 两个顶点之间存在多条边相连接。
解题心得
- 图类算法题,更多是考察我们特定场景下的抽象建模能力。
- 很多问题都可以使用深度优先搜索或者广度优先搜索完成,实现方式类似树的搜索。
- 如果只知道深搜与广搜解题法的话,要多思考该题是否还有别的解法,比如DP解法,因为本质这两种方式还是暴力解法,很容易超时。
- 有很多经典的图类算法我们可以去了解,如:Dijkstra算法、Bellman-Ford算法 、Floyd算法、Prim算法、Kruskal算法。
算法题目
133. 克隆图
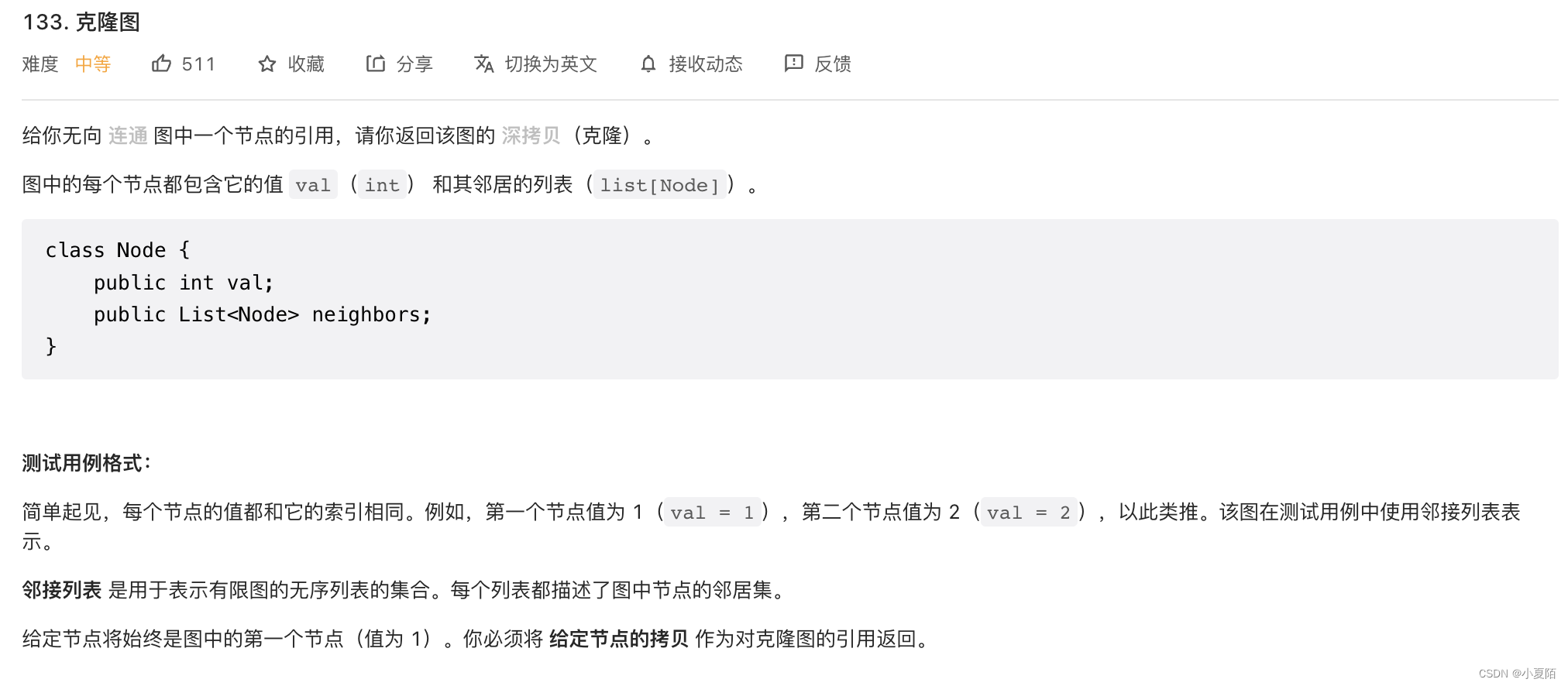
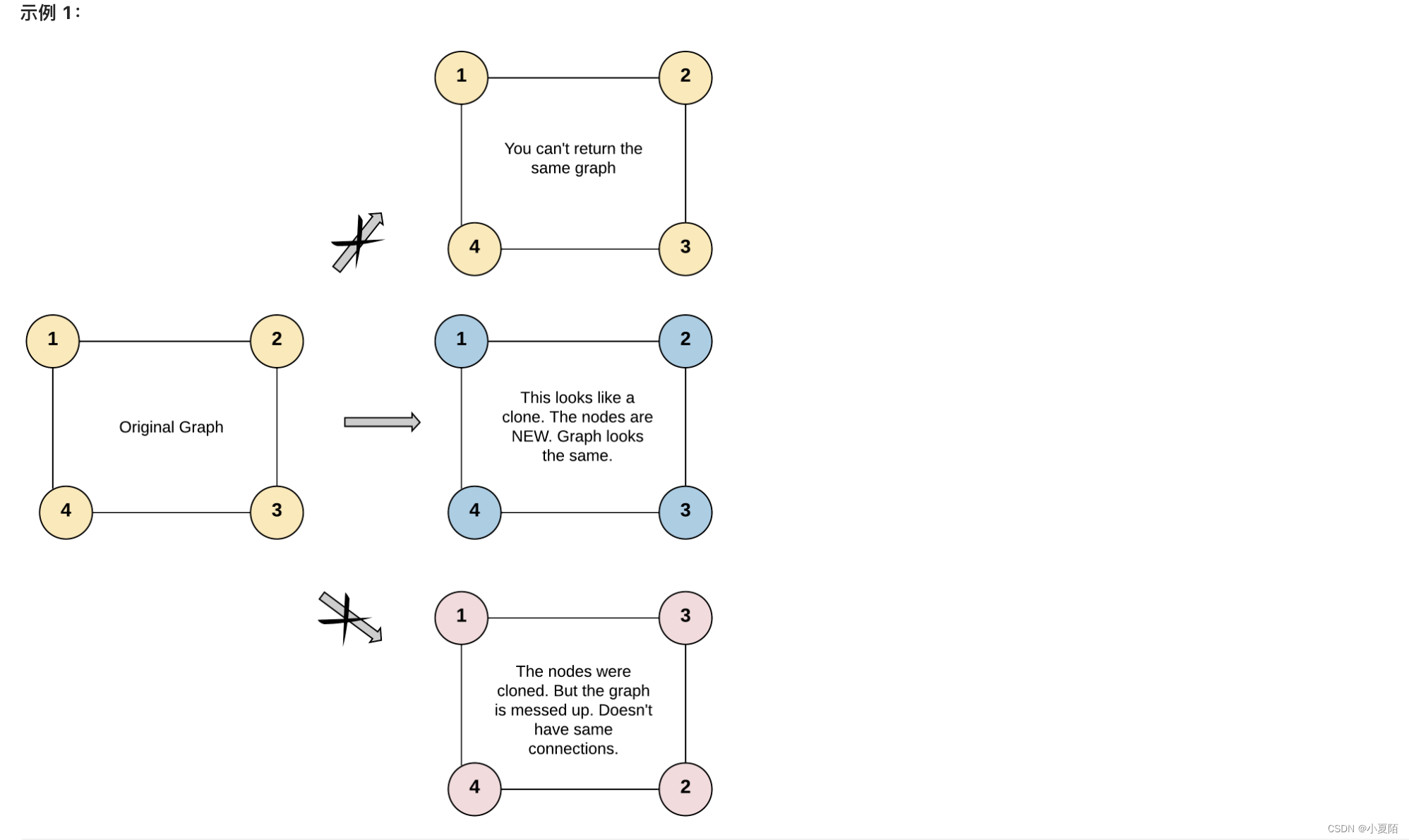

题目解析:直接深度优先递归搜索整张图,然后判断该节点是否拷贝过,最后将所有未拷贝节点拷贝即可。
代码如下:
/*
// Definition for a Node.
class Node {
public int val;
public List<Node> neighbors;
public Node() {
val = 0;
neighbors = new ArrayList<Node>();
}
public Node(int _val) {
val = _val;
neighbors = new ArrayList<Node>();
}
public Node(int _val, ArrayList<Node> _neighbors) {
val = _val;
neighbors = _neighbors;
}
}
*/
/**
* 图
*/
class Solution {
private final Map<Integer, Node> map = new HashMap<>();
public Node cloneGraph(Node node) {
return node == null ? null : helper(node);
}
private Node helper(Node node) {
// 如hash表里有,直接获取,没有则新建
Node copy = map.getOrDefault(node.val, new Node());
if (copy.val == 0) {
copy.val = node.val;
map.put(copy.val, copy);
for (Node n : node.neighbors) {
// 深度递归搜索
copy.neighbors.add(helper(n));
}
}
return copy;
}
}
207. 课程表

题目解析:从入度为0的课程开始,其指向的所有课程入度减1,再找入度为0的重复,最后检查是否与课程数相等即可。
代码如下:
/**
* 拓朴排序
*/
class Solution {
public boolean canFinish(int n, int[][] prerequisites) {
int len = prerequisites.length;
if (len == 0) return true;
int[] pointer = new int[n];// 每个课程被指向的次数
for (int[] p : prerequisites) ++pointer[p[1]];
boolean[] removed = new boolean[len];// 标记prerequisites中的元素是否被移除
int remove = 0;// 移除的元素数量
while (remove < len) {
int currRemove = 0;// 本轮移除的元素数量
for (int i = 0; i < len; i++) {
if (removed[i]) continue;// 被移除的元素跳过
int[] p = prerequisites[i];
if (pointer[p[0]] == 0) {// 如果被安全课程指向
--pointer[p[1]];// 被指向次数减1
removed[i] = true;
++currRemove;
}
}
if (currRemove == 0) return false;// 如果一轮跑下来一个元素都没移除,则没必要进行下一轮
remove += currRemove;
}
return true;
}
}
210. 课程表 II

题目解析:如果该图为有向无环图,则会有拓扑排序。如果有节点是孤立,结果会出现多种(孤立点排前后都可),选择一种即可。
代码如下:
/**
* 图 拓扑排序
*/
class Solution {
// 存储有向图
List<List<Integer>> edges;
// 标记每个节点的状态:0=未搜索,1=搜索中,2=已完成
int[] visited;
// 用数组来模拟栈,下标 n-1 为栈底,0 为栈顶
int[] result;
// 判断有向图中是否有环
boolean valid = true;
// 栈下标
int index;
public int[] findOrder(int numCourses, int[][] prerequisites) {
edges = new ArrayList<List<Integer>>();
for (int i = 0; i < numCourses; ++i) {
edges.add(new ArrayList<Integer>());
}
visited = new int[numCourses];
result = new int[numCourses];
index = numCourses - 1;
for (int[] info : prerequisites) {
edges.get(info[1]).add(info[0]);
}
// 每次挑选一个「未搜索」的节点,开始进行深度优先搜索
for (int i = 0; i < numCourses && valid; ++i) {
if (visited[i] == 0) {
dfs(i);
}
}
if (!valid) {
return new int[0];
}
// 如果没有环,那么就有拓扑排序
return result;
}
public void dfs(int u) {
// 将节点标记为「搜索中」
visited[u] = 1;
// 搜索其相邻节点
// 只要发现有环,立刻停止搜索
for (int v: edges.get(u)) {
// 如果「未搜索」那么搜索相邻节点
if (visited[v] == 0) {
dfs(v);
if (!valid) {
return;
}
}
// 如果「搜索中」说明找到了环
else if (visited[v] == 1) {
valid = false;
return;
}
}
// 将节点标记为「已完成」
visited[u] = 2;
// 将节点入栈
result[index--] = u;
}
}
















 3234
3234











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











