









推荐系统中,常用的个性化推荐算法有下图这些分类。
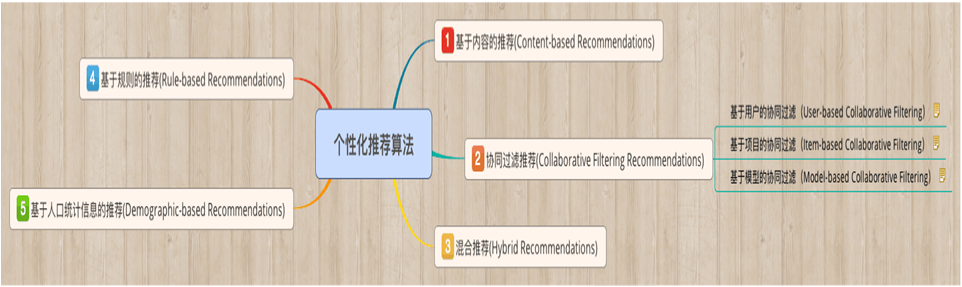
其中,基于内容的推荐和协同过滤的推荐是我们本次重点介绍的对象。
1.基于内容的推荐
首先,我们看看基于内容的推荐(Content-based Recommendation)。
基于内容的推荐一般是 根据用户的画像信息(例如年龄、性别、居住地等等)或者item的内容信息(具体来说,例如对于item是电影时,一般是可以基于电影的类型 喜剧
恐怖片、爱情片等等这些信息)。下面我举一个具体的例子。
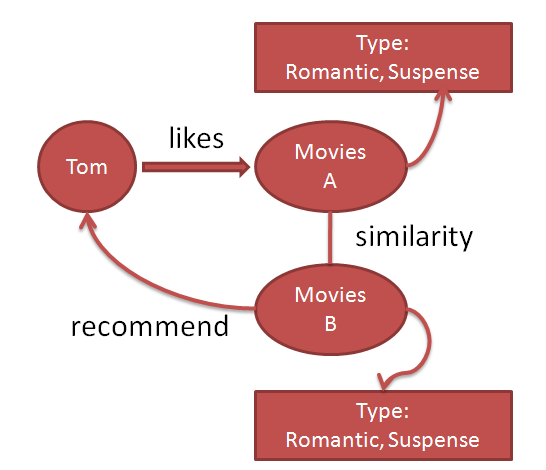
这幅图的意思是这样的,Tom喜欢电影A,电影A的类别是Romantic和Suspense(悬疑)的。同时我们知道电影B也是Romantic和Suspense的。这个时候。基于内容的推荐就会把电影B推荐给Tom。因为电影A和电影B具有相似性。
2.基于协同过滤的推荐
简单介绍了基于内容的推荐,下面就介绍一下基于协同过滤的推荐。在第一幅图中,我们可以看到基于协同过滤的推荐其实分为3种。
前两种,大家可能都很熟悉。最后一种可以有点陌生。所以对于最后一种本文有着重介绍。
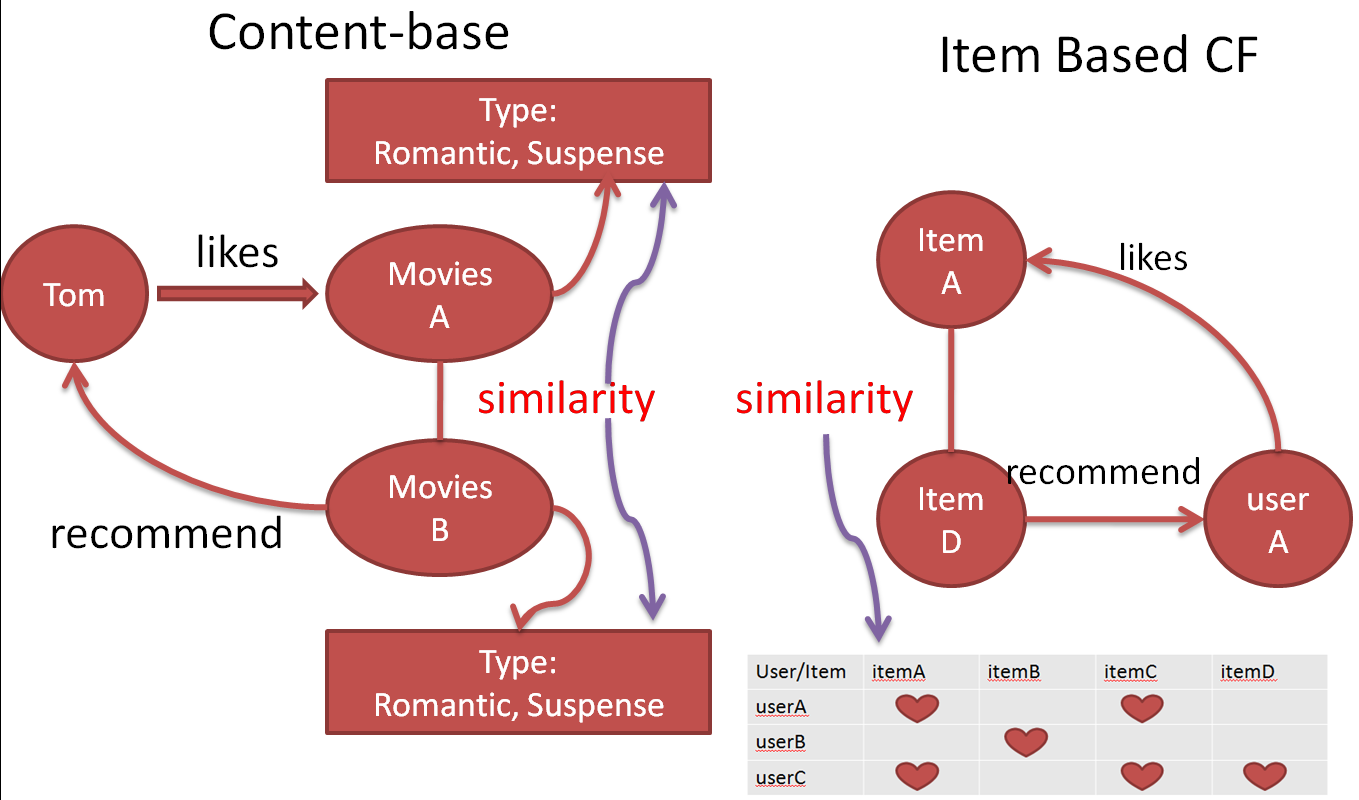
首先,要明确基于协同过滤的推荐都是根据一个叫做 user-item Matrix的矩阵来进行推荐的。这个user-item 矩阵就像下面这个样子:

大家可以看到,其实就是每个不同的user对每个不同的item一个“评价“(喜好的程度)。比如对于userA来说,userA喜欢itemA和itemC。但是,userA对于itemB和itemD上面缺少数据。这里也是一个基于协同过滤都必须考虑的问题,就是 user-item矩阵的稀疏性。
当然,细心的读者可以会发现,这些“评价”只有喜欢和不喜欢吗?。其实并不是这样的,这里只是为了展示一下什么叫做user-item矩阵。user对item的评价可以根据人为地划分许多种等级,我再具一个例子。
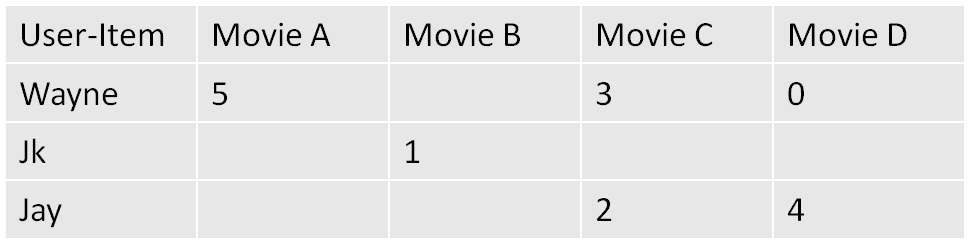
这里0,12,3,4,5其实就对应着不同的等级。
好了,介绍到这里读者心里应该有一个基本的概念,就是如果想基于协同过滤的方法来进行推荐的时候,必须要有user-item矩阵。
下面先讨论基于user的协同过滤。
2.1 基于user的协同过滤推荐
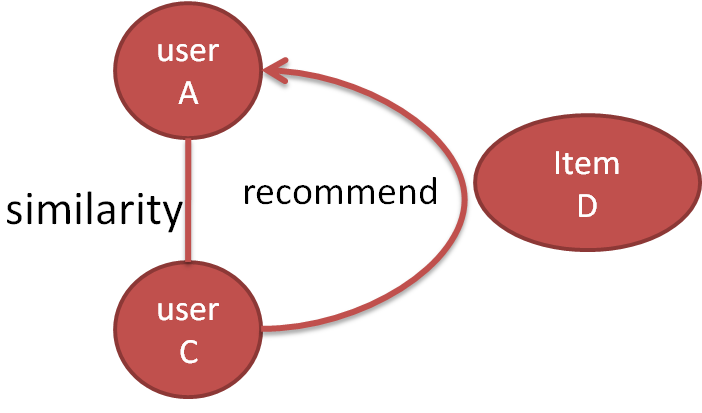
2.2 基于item的协同过滤推荐
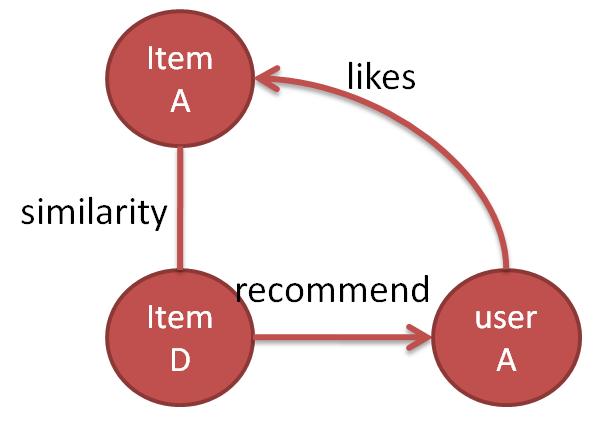
我们来看看下面这个图。
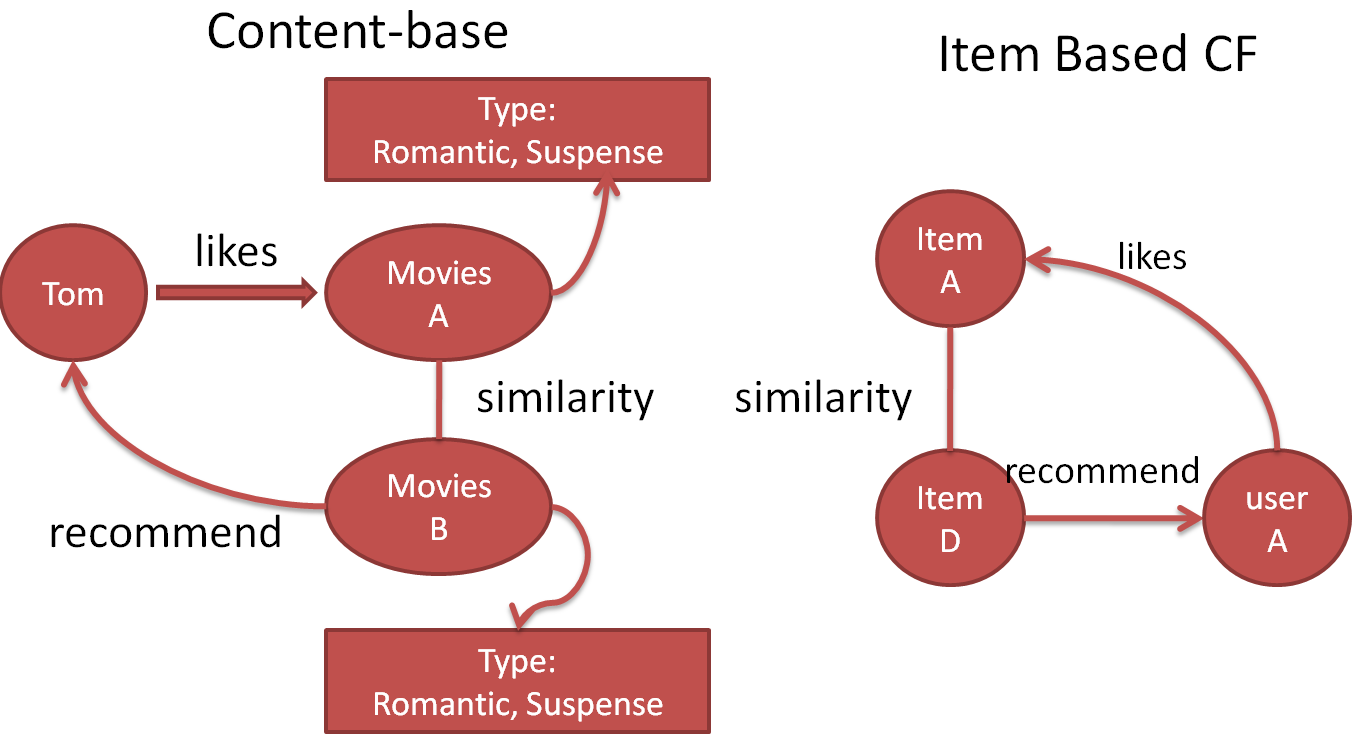
这里,两者的区别就在于 similarity也就是相似性的衡量上面。
在基于内容的推荐上,相似性是通过对item的一些标签。例如电影时什么类型的这些因素来进行推荐。(所以基于内容的推荐工作的重点就是在挖掘这些标签)
在基于item的协同过滤上,相似性是通过user-item矩阵获得的。这个时候,我们不需要提取一些具体的特征。我们只需要计算一下相似性,例如算一下两个向量的余弦值就可以得到两个item间的相似性。
2.3 基于model的协同过滤推荐
OK,到这里协同过滤的两种都介绍完毕了。下面就是另外一个 基于模型的协同过滤 (Model-Based CF)。
在介绍这个之前,我们先介绍一个概念, latent factor (潜在因子)
什么叫潜在因子?看看下面这两个矩阵。
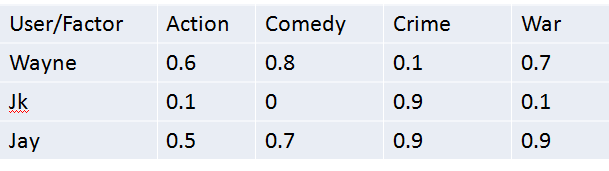
这个矩阵是user latent factor matrix。这里很清晰可以看到每个用户对不同类别的评分。例如Wayne对Action(动作片)的喜爱程度(0.6)大于对犯罪片(0.1)的程度。
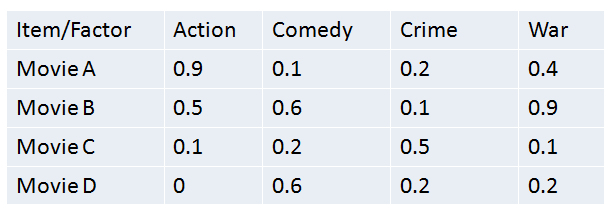
这个矩阵是item latent factor matrix。同样,我们可以清晰的看到,Movie A和Action相关的程度为0.9,和crime的相关程度为0.1。
可以看到,这两个矩阵非常的直观。一般我们把user latent factor matrix记为矩阵U,把item latent factor matrix记为矩阵V。进行矩阵的乘法
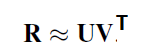
那么,我们就可以得到user-item rating matrix (评分矩阵),一般记做矩阵R。
现实中,我们并没有latent factor matrix,我们只有user-item matrix 。它长这个样子,之前说过

我们要想得到latent factor matrix,我们可以通过矩阵分解(不是唯一的方法)的方法来进行。
进行矩阵分解的时候其实原理很简单。对下面目标进行优化:
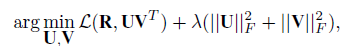
最后,简单说一下model-based CF其实有两个必须要解决的问题。
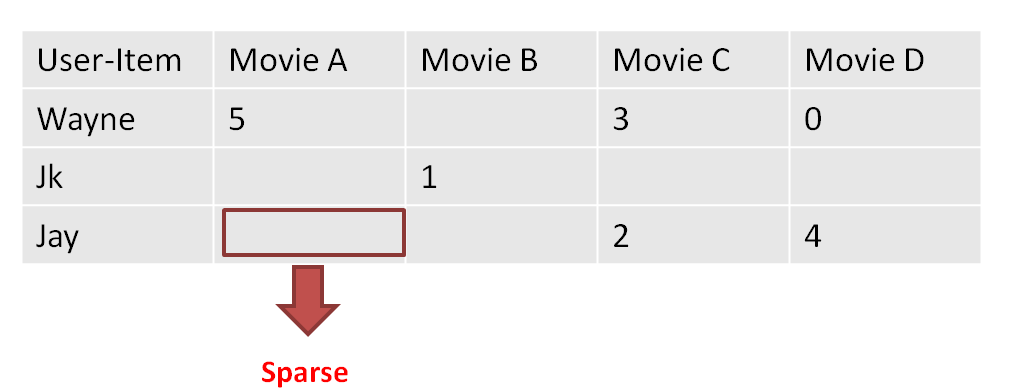
上面的矩阵中,有很多空的地方,其实这就是数据缺失,专业点上叫稀疏性。
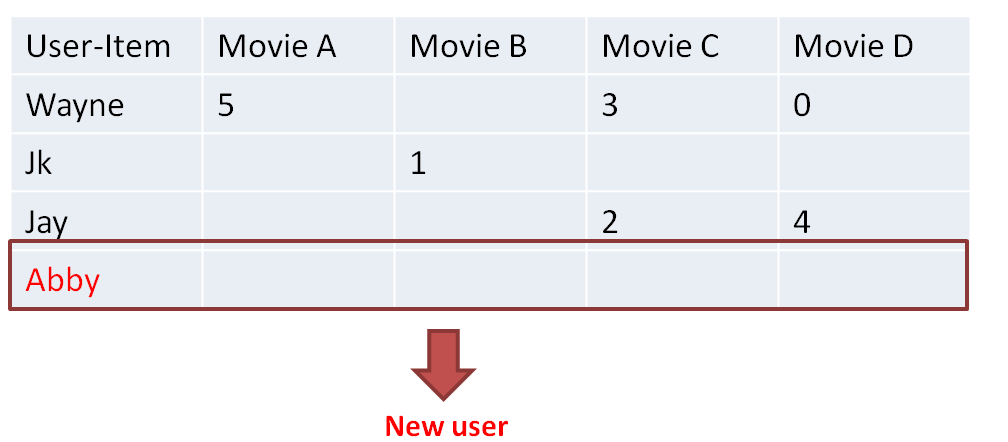
另外一个问题就是,假如出现了新用户Abby,我们没有关于他对任何Movie的评分,这个时候就属于 cold-start(冷启动)问题。
因此协同过滤的方法主要缺点就在于这两点上。有许多论文都在解决这两个问题,例如引入side information(辅助信息)。















 740
740

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









