









摘要:
本文主要是简单讲解一下语言模型N-Gram。网上已经有许多关于N-Gram模型讲解了,下面几个链接是我在阅读过程中认为比较好的文章。和大家分享一下。
1.N-Gram模型
什么是N-Gram模型?如果让你用一句话描述你会怎么描述?我个人比较认同下面这一种说法,这种说法可能不完全的正确,但是能让你第一时间明白这个模型的基本内容。
该模型基于这样一种假设,第n个词的出现只与前面n-1个词相关,而与其它任何词都不相关,整句的概率就是各个词出现的概率的乘积。这些概率可以通过直接从语料中统计n个词同时出现的次数得到。常用的是二元的Bi-Gram和三元的Tri-Gram。
ok,看完这句话可能有几个问题。
① 为什么模型要假设第n个词的出现只与前面n-1个词相关,而与其他任何词都不相关。
②Bigram,Trigram是什么东西?
③各个词出现的概率如何计算?
④N-Gram模型有何应用?
2.问题1&2
假设我们目前有一个句子T,句子T有许多个词组成,现在我来考虑一下这个句子出现的概率也就是:
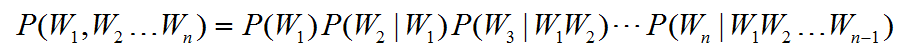
比方说,今天天气真好,这个句子出现的概率。就应该是:
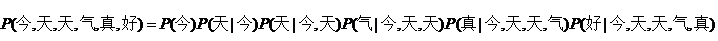
好的,现在问题转化为求后面的每一个条件概率。但其实你会发现,这些条件概率非常不好求。
但是这种方法存在两个致命的缺陷:一个缺陷是参数空间过大,不可能实用化;另外一个缺陷是数据稀疏严重。
那么,既然这个原始的式子不好求,那怎么办?一般情况下,我们可以 做点假设。没错,假设就是我们的问题一。其实这个假设是利用了 马儿科夫链的假设。
我们假设,第n个词出现的只与前n-1个词相关的话,我们的式子就可以得到极大的简化。
假设n取1,也就是每个词的出现是独立,那么此时为1-Gram模型,句子的概率为:
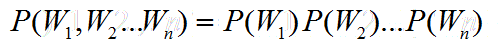
显然,这种假设太过于强,每个词出现不可能完全的独立。
假设n取2,也就是每个词的出现仅与前一个词出现有关,此时为2-Gram模型也就是Bi-Gram,句子的概率为:
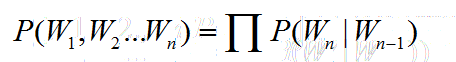
假设n取3,也就是每个词的出现仅与前两个词有关,此时为3-Gram模型,也就是Tr-Gram,句子的概率为:
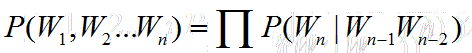
回到我们刚刚那句话,今天天气真好,如果采用2-Gram的模型我们有:
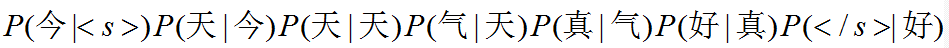
这里说明一下:采用N-Gram模型的时候,在句子开始与结束需要补充N-1个标识符。<s>表示开始 </s>表示结束
至此,N-Gram模型就已经基本介绍完毕了,下面以一个例子说明一下计算的过程。
在这里插一段题外话:其实,我们回忆朴素贝叶斯模型的推导思路时候,其实我们当时遇到的问题也是很类似的,因此后面我们做了一个很强的假设(每个特征之间相互独立),因此才得以求出当时需要的条件概率。具体看文章
朴素贝叶斯思想。
(在对比中学习往往效果是最佳的)
3.问题3
那么我们要如何进行计算呢?其实过程很简单,把握好一下公式:
对N-Gram模型。
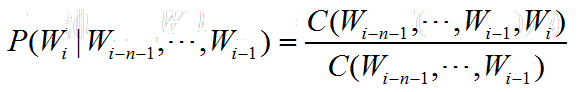
C代表的出现的次数。比方说,我们在一个语料库中已经统计好了下表。
第一行第二列代表,i出现在want前面的827次数。
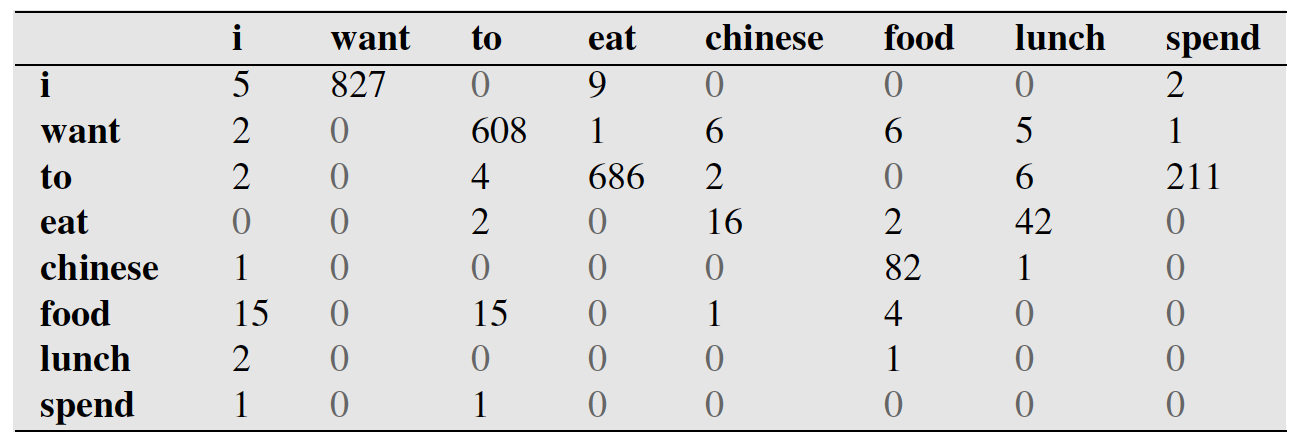
下表代表每个词出现的次数。比如i一共出现2533词。

ok,那么概率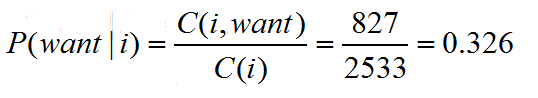
注意的是,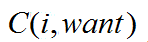 这里是有顺序要求的,并不是i,want同时出现的次数,而是i出现在want前面的次数。
这里是有顺序要求的,并不是i,want同时出现的次数,而是i出现在want前面的次数。
这里是有顺序要求的,并不是i,want同时出现的次数,而是i出现在want前面的次数。
更加详细的计算可以参考本文开头给出参考文章。
3.问题4
至于N-Gram其实有许多的应用,说其中一个,
在搜索的时候,我们输入一个字,后面会自动联想其他的字。其实这个也用到N-Gram的技术。
具体在开头参考文章最后一的部分有给出。大家可以参考一下。
总结
这篇文章其实没说什么,只是简单的给大家理了一下思路,更加深入的学习需要大家在网上寻找更多资源来进行学习。
N-Gram中一个很重要的问题,平滑的问题其实我们没有提到,这里简单提一下,我们看到上面的表
发现有很多的0,这样,我们在算概率时,概率就为0,只要有这种词组合出现的情况下就会导致整个句子的概率为0,显然这不符合事实。
另外,我们可以联想朴素贝叶斯里头,我们也碰到过这个问题。我们当时解决的方法就是利用平滑。
最简单的平滑我们改造上面的概率公式:
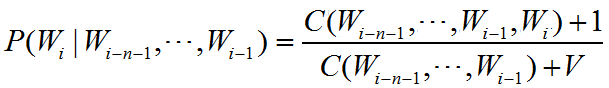
其中V是所有上面内所有次次数之和。















 9150
9150

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









