










【2021知识蒸馏】Show, Attend and Distill:Knowledge Distillation via Attention-based Feature Matching
1.问题背景
知识蒸馏:从老师到学生的学习,一般人工选择老师和学生的中间特征。然而,手动选择经常构建无效的链接,限制了蒸馏的改进。已经有人试图解决这个问题,但在实际情况下确定有效的联系仍然具有挑战性。

本文:利用基于注意力的元网络学习特征之间的相对相似性,并应用识别的相似关系来控制所有可能的对的蒸馏强度。
2.模型
本文是基于attention-based feature distillation (AFD). 2015,2017

具体来说,AFD利用基于注意力的元网络来识别教师和学生之间的相似特征。识别出的相似度用于控制所有可能特征对的蒸馏强度。

老师特征:hT
学生特征:hS
每个特征都有各自的高H、宽W、通道维数d。
AFD的目的是确定所有可能的组合(S*T对)的相似点,并将教师候选特征的知识转移给具有确定的相似点的学生。
相似性是采用了一种关注机制的查询键概念,老师特征生成一个查询qt ,学生特征识别一个键ks 。

本文方法:对候选特征进行了全局平均池化和通道池化两个方向的比较。本文的关注机制的查询键数学表达:

计算损失函数中前面的系数用softmax:
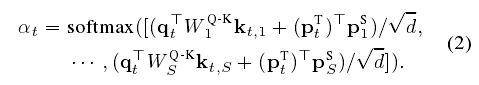
双线性W为了广义化2018
位置编码p为了不同实例来共享信息2017
α
\alpha
αt是第t个老师对整个学生

最终的损失:真实标签损失+知识蒸馏损失


上采样和下采样为了匹配特征图的大小。

学生网络和注意力网络可以同时训练。
3.实验结果


代码链接: 代码.















 1949
1949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









