







引言
在深度学习领域中,我们经常处理的是独立同分布(i.i.d)的数据,比如图像分类、文本生成等任务,其中每个样本之间相互独立。然而,在现实生活中,许多数据具有时序结构,例如语言模型中的单词序列、股票价格随时间的变化、视频中的帧等。对于这类具有时序关系的数据,传统的深度学习模型可能无法很好地捕捉到其内在的 时间相关性 。为了解决这一问题,循环神经网络(Recurrent Neural Network, RNN)被广泛应用于处理时序数据。
为什么说反向传播算法不能处理时序数据呢?
在传统的反向传播算法中,处理静态数据时,网络的输出 y ^ \hat{y} y^ 通常只依赖于当前时刻的隐藏状态 h h h,其更新规则可以表示为:
h = W x + b h = Wx + b h=Wx+b
y ^ = V h + c \hat{y} = Vh + c y^=Vh+c
其中, h h h 是隐藏状态, x x x 是输入, W W W 和 V V V 是网络的参数, b b b 和 c c c 是偏置项。
与传统反向传播算法不同,BPTT(Back-Propagation Through Time)算法引入了时间维度,并考虑了序列数据中的时序关系。在 BPTT 中,隐藏状态 h t h_t ht 的更新规则包含了当前时刻的输入 X t X_t Xt 和上一个时刻的隐藏状态 h t − 1 h_{t-1} ht−1,从而能够更好地捕捉到序列数据中的时间相关性。
h t = f ( U X t + W h t − 1 ) h_t = f(UX_t + Wh_{t-1}) ht=f(UXt+Wht−1)
y t ^ = f ( V h t ) \hat{y_t} = f(Vh_t) yt^=f(Vht)
RNN 结构与BPTT
首先,让我们来了解一下常见的循环神经网络结构。在 RNN 中,隐藏状态会随着时间步的推移而更新,并在每个时间步生成一个输出。这种结构允许网络捕捉到序列数据中的时间相关性,使得其在时序任务中表现出色。
一个常见的RNN结构如下所示:
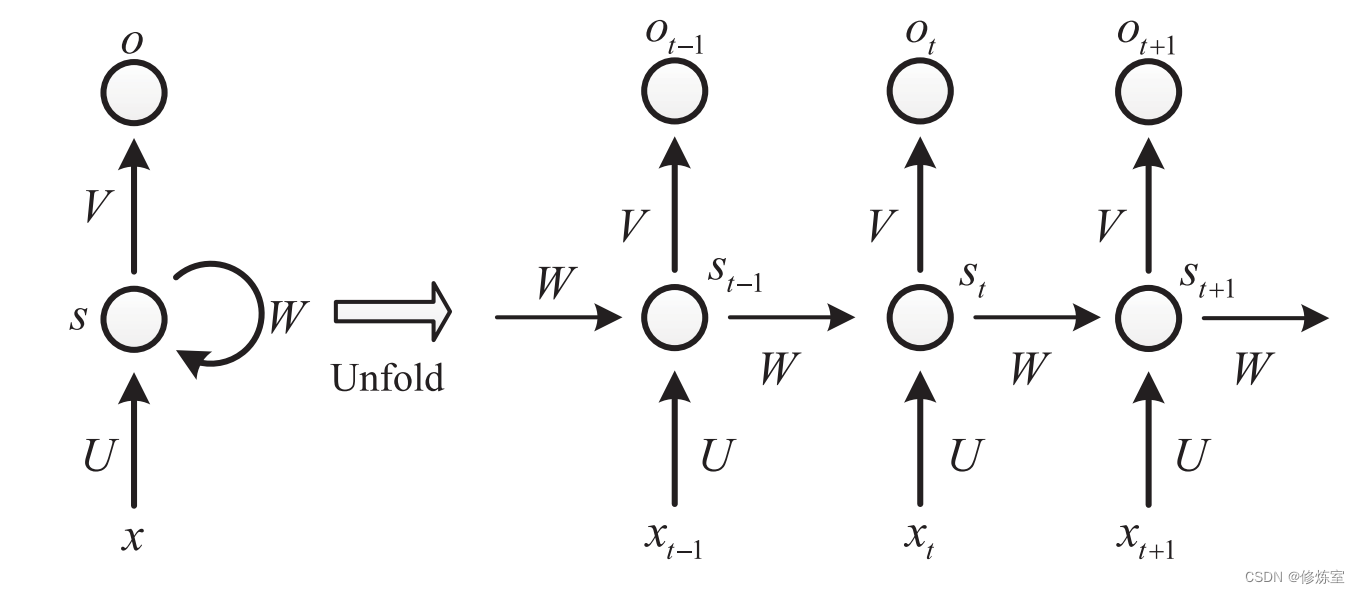
在RNN中,参数U、V和W是共享的,这意味着它们在每个时间步都保持不变。这意味着它们的值在整个模型运行过程中 始终保持一致 。
BPTT算法概述
前向传播
在 RNN 中,前向传播阶段通过计算隐藏状态和输出来生成预测结果。
h t = f ( U X t + W h t − 1 ) h_t = f(UX_t + Wh_{t-1}) ht=f(UXt+Wht−1)
y t ^ = f ( V h t ) \hat{y_t} = f(Vh_t) yt^=f(Vht)
损失函数
这些结果与真实标签之间的差异通过损失函数来衡量,我们的目标是最小化这个损失函数。整个网络的损失值 L L L是每个时刻损失值 L t L_t Lt的求和,其中 L t L_t Lt是关于预测值 y t ^ \hat{y_t} yt^的函数。
L t = f ( y t ^ ) L_t = f(\hat{y_t}) Lt=f(yt^)
L = ∑ i = 1 T L t L = \sum_{i=1}^{T} L_t L=i=1∑TLt
损失函数 L L L 可以表示为:
- 均方误差(MSE):
L = ∑ t = 1 T 1 2 ( y t − y ^ t ) 2 L = \sum_{t=1}^T \frac{1}{2} (y_t - \hat{y}_t)^2 L=t=1∑T21(yt−y^t)2
这里,我们计算每个时间步的输出 y t y_t yt 与真实输出 y ^ t \hat{y}_t y^t 之间的平方误差,并将所有时间步的误差求和。- 交叉熵损失:
L = − ∑ t = 1 T [ y ^ t log ( y t ) + ( 1 − y ^ t ) log ( 1 − y t ) ] L = -\sum_{t=1}^T [\hat{y}_t \log(y_t) + (1 - \hat{y}_t) \log(1 - y_t)] L=−t=1∑T[y^tlog(yt)+(1−y^t)log(1−yt)]
这里,我们计算每个时间步的输出 y t y_t yt 与真实输出 y ^ t \hat{y}_t y^t 之间的交叉熵损失,并将所有时间步的损失求和。
反向传播
接下来,我们使用BPTT算法(随时间反向传播,Back-Propagation Through Time,BPTT)进行反向传播。在这一步中,我们计算损失函数对参数U、V和W的偏导数,以便更新参数以最小化损失。
为什么要使用整个序列的损失函数L对参数U、V和W求导呢?
这是因为我们的目标是最小化整个序列的损失。在梯度下降算法中,梯度指向了损失函数增长最快的方向。因此,通过对整个序列的损失函数求导,我们可以找到在参数空间中使得损失函数逐步减小的方向,然后通过反向传播来更新参数。
由于RNN处理的是时序数据,因此需要基于时间进行反向传播,这也是BPTT名称的由来。尽管BPTT是在时序数据上进行反向传播,但本质上它仍然是反向传播算法,因此求解每个时间步的梯度是该算法的核心操作。
梯度计算
我们以一个长度为3的时间序列为例,展示对于参数U、V和W的偏导数的计算过程。
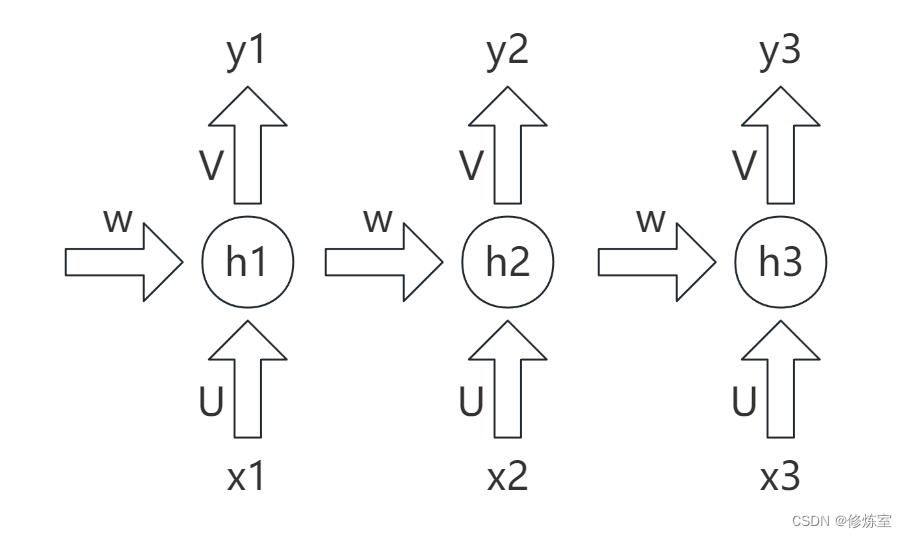
首先看看前向传播的计算
隐藏层输出:
h t = f ( U X t + W h t − 1 ) h_t = f(UX_t + Wh_{t-1}) ht=f(UXt+Wht−1)
为什么“RNN的隐藏状态更新规则是 h t = f ( U X t + W h t − 1 ) h_t = f(UX_t + Wh_{t-1}) ht=f(UXt+Wht−1)”?
从数学角度来看,这个更新规则是由RNN的结构决定的。在RNN中,隐藏状态
h t h_t ht 是
- 由当前时间步的输入 X t X_t Xt
- 前一个时间步的隐藏状态 h t − 1 h_{t-1} ht−1
组合而成的。通过线性变换 U X t + W h t − 1 UX_t + Wh_{t-1} UXt+Wht−1,加上激活函数 f f f 的作用,得到了新的隐藏状态 h t h_t ht。这个结构使得RNN能够记忆之前的信息并将其应用于当前的预测任务中。
输出层:
y t ^ = f ( V h t ) \hat{y_t} = f(Vh_t) yt^=f(Vht)
- h t h_t ht 是隐藏状态
- y t ^ \hat{y_t} yt^ 是输出值
- X t X_t X
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1189
1189

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









