









2023.11.6 update:https://zhuanlan.zhihu.com/p/664868076 对ResNet代码进行了精读。
解决这篇blog之前留下的问题。
前言
参加了华为一个小比赛第四届MindCon-爱(AI)美食–10类常见美食图片分类,本来想实践机器学习课程的知识,后来发现图像分类任务基本都是用神经网络做,之前在兴趣课上学过一点神经网络但不多,通过这样一个完整的项目也算入门了。
代码仓库:https://github.com/fgmn/ResNet
任务

ResNet
这里主要结合官方pytorch代码和B站视频6.2 使用pytorch搭建ResNet并基于迁移学习训练进行理解。
模型
层数不同的网络许多子结构是相似的,因此对子结构的定义会有一些参数定义。
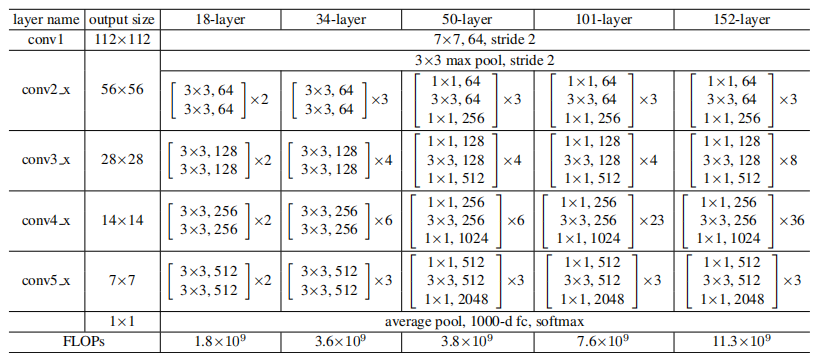
论文提到两种残差结构,从上面表格可以看到,左侧building block用于18,34层网络,右侧bottleneck用于50,101,152层网络。
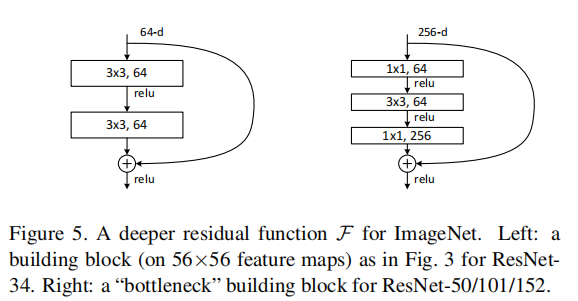
左侧残差结构的实现如下,首先定义残差结构所使用的一系列层结构,stride=1时输入输出矩阵大小相同,stride=2时输出长宽均为输入的
1
2
\frac{1}{2}
21,channel是通道数,和卷积核个数对应,如
3
×
3
,
64
3\times3,64
3×3,64代表使用64个大小为
3
×
3
3\times3
3×3的卷积核对输入的64个通道进行卷积运算。之后定义正向传播过程,实际定义了网络结构,bn层定义在卷积层和激活函数之间。同理,定义右侧残差结构,之后定义ResNet网络。
训练
指定训练设备cuda或者cpu,定义数据的transform,进行随机裁剪,随机翻转,标准化处理等等操作,加载训练集以及验证集,施加transform,定义batch_size=16,定义全连接层,交叉熵损失函数,以及Adam优化器,训练并验证,保存效果最好的网络。
问题
其实,我并没有很好理解整个网络框架,甚至一些基本cnn网络的知识都没有搞清楚,pytorch框架将很多细节隐藏起来了,这里留下一下我的问题和想法:
- 网络的参数在哪,如何影响网络运行?卷积核应该是有参数的,bn层也有。最后参数量,FLOPs如何确定?
- 数据如何流动,或者直接说是如何计算的?层与层之间是全连接的关系,也就是说一个神经元的输入来自上一层所有神经元的输出?神经元和卷积核的关系?
- 数据transform的作用机理,或者更广泛地发问,标准化的数据为什么可以提升模型效果?之前在逻辑斯蒂回归中也是标准化数据后正确率大大提升。
- batch的作用,为什么数据以batch为单位?是不是在SGD算法中以一个batch为单位做梯度下降?
update answer:
- conv层以及dense层都有参数,卷积核可以理解为参数的载体,纠正bn层无。至于参数量计算方式,用一个前面的例子,“用64个大小为 3 × 3 3\times3 3×3的卷积核对输入的64个通道进行卷积”,这层的参数数量为: 3 × 3 × 64 × 64 3\times3\times64\times64 3×3×64×64,每个卷积核的大小为 长 × 宽 × 输入通道数 长\times宽\times输入通道数 长×宽×输入通道数,这对应着卷积核的工作方式,在所有输入通道上提取特征最后再sigma到一起。然后这些实现都封装在Pytorch内。
- forward定义了数据传播方式。神经元感觉是对数据在层与层之间的抽象?和卷积核没有关系。然后全连接(fully-connected)就是层,还有卷积层,池化层,BN层,每一层都有各自的计算,层就是计算method的载体。
- 调整输入的概率分布,避免overfit。
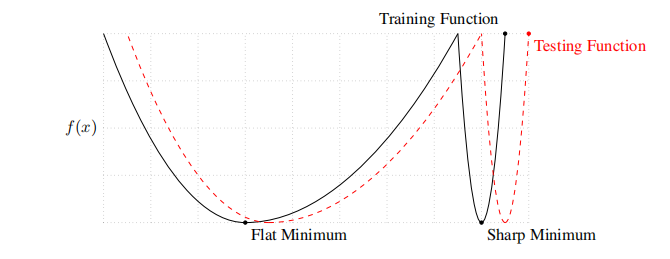
- 好问题。相比于每次梯度下降用整个dataset,batch肯定更快。而且使用mini-batch的模型更优。refere ON LARGE-BATCH TRAINING FOR DEEP LEARNING: GENERALIZATION GAP AND SHARP MINIMA (ICLR 2017)
large-batch methods tend to converge to sharp minimizers of the training and testing functions—and as is well known, sharp minima lead to poorer generalization. In contrast, small-batch methods consistently converge to flat minimizers
ModelArts
虽然没有彻底理解网络机理,但这并不影响我们将它应用到任务上。华为云的ModelArts是面向开发者的一站式开发平台(官方),提供开发环境,不需要在服务器上再配置训练环境,而在本地我们需要conda install,pip install一堆软件包,而且还会遇到这些包可能有版本依赖,版本更新,有时候作者的导出环境可能有许多其他不相关的包等等问题。我用的是它提供的notebook,将代码和数据上传至云上,就可以直接进行开发、训练了。也可以远程创建训练作业,将数据集放在OBS服务的桶中,用SDK提交训练任务进行训练。平台还有部署上线,自动学习等服务,自动学习就是用它提供模型,无代码地进行图像分类,目标检测等任务。
最后的结果,在500张图片的测试集上有98%的正确率。



















 1568
1568

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











