









前言
在上篇博客中,我完成了这么一个功能,输入一个单词的混序,然后从数据字典中查找该单词。于是我当时想到一个问题:
我输入的混序词应该是要和被查找的单词是等长的,如果不等长,那么怎么查询?这就是我这篇博客的由来.
举个例子:
查找apple,在上篇我需要输入a p p l e五个字符的混序输入,
在这篇文章实现的算法中,我只需要实现输入 a p p 即可,这样它的匹配率会达到0.6,如果没有其他的字典高于这个匹配率,这样就能查找出apple这个单词
思路
参照我上篇博客,只不过多了一个识别率的算法而已,还是参考归并排序写的,很简单。
上篇博客地址
很多的解释都在代码里面了,各位看看就明白了
代码
// author:seen
// time:2015-09-20
#include <iostream>
#include <string>
#include <fstream>
using namespace std;
struct Photograph{ //s保存原来的单词,res保存排序之后的单个单词,value记录匹配率
string s,res;
float value;
}P[100];
string s1,s2,res1,res2;
float find(string s1,string s2){ //返回两个字符串的模式匹配率
int i=0,j=0,count=0;
while(i<s1.length() && j<s2.length()){ //用到了类似于归并排序的算法
if(s1[i]==s2[j]) { count++;i++;j++;}
if(s1[i]<s2[j]) { i++;continue;}
if(s1[i]>s2[j]) {j++;continue;}
}
return (float)count/s1.length();
}
string SelectS(string s){ //给单个单词进行内部单个字符的排序操作
string s_temp = s;
for(int i=0;i<s_temp.length();i++){
for(int j=i+1;j<s_temp.length();j++){
if(s_temp[j]<s_temp[i]){
char temp = s_temp[i];
s_temp[i] = s_temp[j];
s_temp[j] = temp;
}
}
}
return s_temp;
}
int main()
{
//这段代码是录入字典的过程
fstream f("d:\\数据.txt",ios::in);
if(!f) cout<<"mistake";
int count=0;
while(!f.eof()){
f>>P[count].s;
P[count].res = SelectS(P[count].s); //用同个结构体里面的res字符串来接受内部排序的单词
count++;
}
f.close();
string temp;
cin>>temp;
for(int i=0;i<count;i++){
P[i].value = find(P[i].res,SelectS(temp)); //获的每个字符串的模式匹配率,这里居然还出了问题=_=
cout<<P[i].value<<endl;
}
//查找最大值及输出该字符串的过程
float max = P[0].value;
int pos=0;
for(i=1;i<count;i++){
if(P[i].value>max){
max = P[i].value;
pos = i;
}
}
cout<<"匹配的字符串最可能为"<<P[pos].s<<endl;
}运行截图
数据字典内容:

程序运行内容:
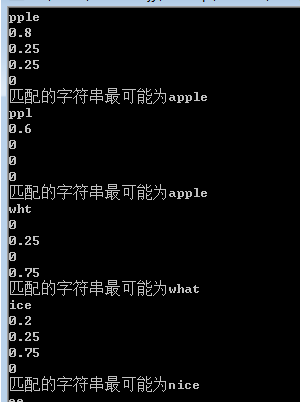
字符串下面的那些小数是指的各个数据的匹配率~















 848
848

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









