









理论背景
DeepFM模型是2017年哈工大深圳与华为诺亚方舟联合实验室提出的,论文名称《DeepFM: A Factorization-Machine based Neural Network for CTR Prediction》,DFM模型是在W&D模型上的改进,W&D模型理论参照上一篇笔记,在W&D的基础上,将Wide部分替换为FM模型,不再需要人工特征工程,同时巧妙地在FM的二阶部分和神经网络的Embedding层共享权重,减少了大量参数,极大的提高了训练速度。
在CTR预估任务中,业界常用的方法有人工特征工程+逻辑回归、梯度增强决策树(GBDT)+逻辑回归,FM(Factorization Machine)和FFM(Field-aware Factorization Machine)模型,在这些模型中FM、FFM模型表现突出。
FM模型
在学习DFM之前,先简单的学习一下FM模型和FFM模型,FM模型是由Konstanz 大学 Steffen Rendle于2010年提出,旨在解决稀疏数据下的特征组合问题。下面我们用一个例子引入FM模型,假设我们要处理一个广告问题,根据用户和广告类型特征,预测用户是否点击了广告。
| Clicked? | Country | Day | Ad_type |
|---|---|---|---|
| 1 | USA | 26/11/15 | Movie |
| 0 | China | 1/7/14 | Game |
| 1 | China | 19/2/15 | Game |
其中**Clicked?**是标签label,Country、Day、Ad_type是特征。由于三种特征都是类别类型,我们需要通过One-Hot编码将他们转换成数值型特征。
| Clicked? | Country=USA | Country=China | Day=26/11/15 | Day=1/7/14 | Day=19/2/15 | Ad_type=Movie | Ad_type=Game |
|---|---|---|---|---|---|---|---|
| 1 | 1 | 0 | 1 | 0 | 0 | 1 | 0 |
| 0 | 0 | 1 | 0 | 1 | 0 | 0 | 1 |
| 1 | 0 | 1 | 0 | 0 | 1 | 0 | 1 |
经过One-Hot编码之后,产生的样本数据大部分都是比较稀疏的,每个样本具有7维特征,但平均仅有3维特征具有非零值。在真实场景中,这样的情况也是普遍存在的,例如我们扩展上述数据的特征,加入用户的性别、职业、教育水平,商品品类等,经过One-Hot编码转换后都会导致样本数据的稀疏性。特别是商品品类这种类型的特征,如商品的品类约有550个,采用One-Hot编码生成550个数值特征,但是每个样本的550个特征中,有且仅有一个是有效的(非零)。由此可见,数据的稀疏性,在真实场景中是不可避免地挑战。
另外,我们也可以发现,经过One-Hot编码之后,特征空间陡然增大。例如,商品品类有550维特征,且是一个类别特征引起的。
通过观察大量样本数据可以发现,某些特征经过关联之后,与label之间的相关性就会提高,例如,“USA”与“Thanksgiving”、“China”与“Chinese New Year”这样的关联特征。对用户的点击行为有着正向的影响。同样,“化妆品”类商品与“女性”,“球类运动”类商品与“男”性,可见这种关联特征也是普遍存在的,因此进行特征的组合是非常有意义的。
在众多模型中,多项式模型是包含特征组合的最直观的模型。在多项式模型中,特征
x
i
x_i
xi和
x
j
x_j
xj的组合我们采用
x
i
x
j
x_ix_j
xixj表示,即
x
i
x_i
xi和
x
j
x_j
xj都非零时,组合特征
x
i
x
j
x_ix_j
xixj才有意义,在这里我们只讨论二阶多项式模型。表达式如下:
y
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
w
i
j
x
i
x
j
y(x)=w_0+\sum^{n}_{i=1}{w_ix_i}+\sum^{n}_{i=1}\sum^{n}_{j=i+1}{w_{ij}x_ix_j}
y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nwijxixj
其中,
n
n
n代表样本的特征数量,
x
i
x_i
xi是第
i
i
i个特征的值,
w
0
w_0
w0、
w
i
w_i
wi、
w
i
j
w_{ij}
wij是模型参数。
在多项式模型中,组合特征的参数一共有 n ( n − 1 ) 2 {n(n-1)\over{2} } 2n(n−1)个,且任意两个参数都是独立的。但是因为每个参数 w i j w_{ij} wij的训练都需要大量的 x i x_i xi和 x j x_j xj都非零的样本,在数据稀疏性普遍存在的实际场景中,这样的训练是非常困难的,参数 w i j w_{ij} wij的不准确将严重影响模型的性能。
那么,我们如何解决二次项参数的训练问题呢?我们借助矩阵分解的思想,将所有二次项参数
w
i
j
w_{ij}
wij组成一个对称矩阵
W
W
W,这个矩阵可以分解为
W
=
V
T
V
W=V^TV
W=VTV,
V
V
V的第
j
j
j列便是第
j
j
j维特征的隐向量,即
w
i
j
=
⟨
v
i
,
v
j
⟩
w_{ij}=\langle{v_i,v_j}\rangle
wij=⟨vi,vj⟩,这就是FM模型的核心思想。因此二阶FM模型的方程可以表述为:
y
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
⟨
v
i
,
v
j
⟩
x
i
x
j
y(x)=w_0+\sum^{n}_{i=1}{w_ix_i}+\sum^{n}_{i=1}\sum^{n}_{j=i+1}{\langle{v_i,v_j}\rangle}{x_ix_j}
y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,vj⟩xixj
其中,
v
i
v_i
vi是第
i
i
i维特征的隐向量,
⟨
⋅
,
⋅
⟩
{\langle{\cdot,\cdot}\rangle}
⟨⋅,⋅⟩表示向量点积。
FFM模型
FFM模型(Field-aware Factorization Machine)来源于Yu-Chin Juan与其比赛队员,他们借鉴了Michael Jahrer的论文中的field概念,提出了FM的升级版模型。FFM把相同性质的特征归于同一个Field。以上面的广告点击案例为例,“Day=26/11/15”、“Day=1/7/14”、“Day=19/2/15” 这三个特征都是代表日期的,可以放到同一个 Field 中。同理,550个商品类别特征也可以放到一个Field中。即同一个类别特征经过One-Hot编码生成的数值特征都可以放到同一个Field中。在FFM中,每一维特征 x i x_i xi,针对其它特征的每一个Field记为 f j f_j fj,都会学习一个隐向量 v i , f j v_{i,f_j} vi,fj。因此,隐向量不仅与特征相关,也与Field相关。也就是说,“Day=26/11/15” 这个特征与 “Country” 特征和 “Ad_type” 特征进行关联的时候使用不同的隐向量,这与 “Country” 和 “Ad_type” 的内在差异相符,也是 FFM 中 “field-aware” 的由来。
假设样本的
n
n
n个特征属于
f
f
f个 field,那么 FFM 的二次项有
n
f
nf
nf个隐向量。而在 FM 模型中,每一维特征的隐向量只有一个。FM 可以看作 FFM 的特例,是把所有特征都归属到一个 field 时的 FFM 模型。根据 FFM 的 field 敏感特性,可以导出其模型方程。如下:
y
(
x
)
=
w
0
+
∑
i
=
1
n
w
i
x
i
+
∑
i
=
1
n
∑
j
=
i
+
1
n
⟨
v
i
,
f
j
,
v
j
,
f
i
⟩
x
i
x
j
y(x)=w_0+\sum^{n}_{i=1}{w_ix_i}+\sum^{n}_{i=1}\sum^{n}_{j=i+1}{\langle{v_{i,f_j},v_{j,f_i}}\rangle}{x_ix_j}
y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑n⟨vi,fj,vj,fi⟩xixj
DFM模型
FM模型和FFM模型都在特征组合方面进行了探索,FM通过对每一维特征的隐变量内积来提取特征组合,虽然也能取得非常好的结果,但是由于计算复杂度的原因,往往只能局限在二阶特征组合进行建模。如果要使用FFM模型,所有的特征必须要转换成"field_id:feat_id:value"的格式,field_id表示特征所属field的编号,feat_id代表特征编号,value是特征的值。
对于高阶的特征组合来说,我们通常会想到通过DNN去解决,但是正如我们之前介绍的那样,对于类别型特征,我们使用One-Hot编码的方式处理,但是将One-Hot编码输入到DNN中,会使网络参数陡增。
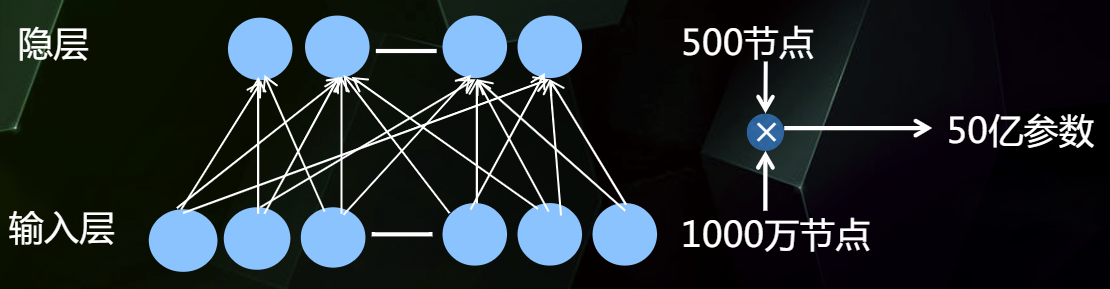
为了解决参数量过大的问题,我们可以借助FFM的思想,将特征分为不同的Field,避免全连接,分而治之。
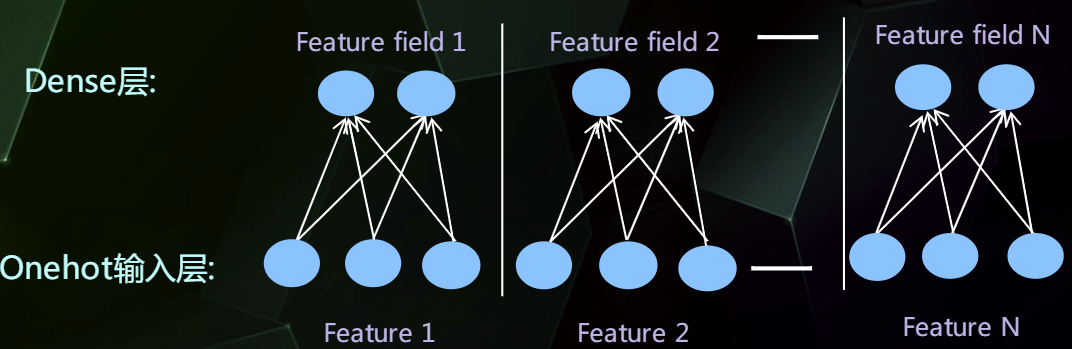
然后通过增加全连接层就可以实现高阶的特征组合,如下:
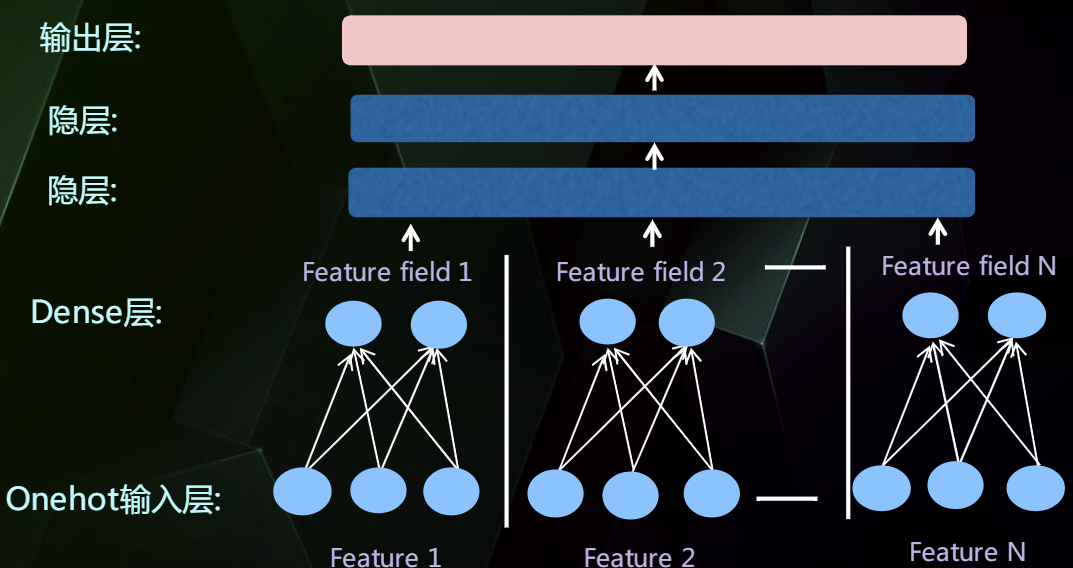
但是这里仍然缺少低阶的特征组合,我们使用FM把低阶特征组合单独建模。

然后把低阶特征组合模型插入到网络结构中
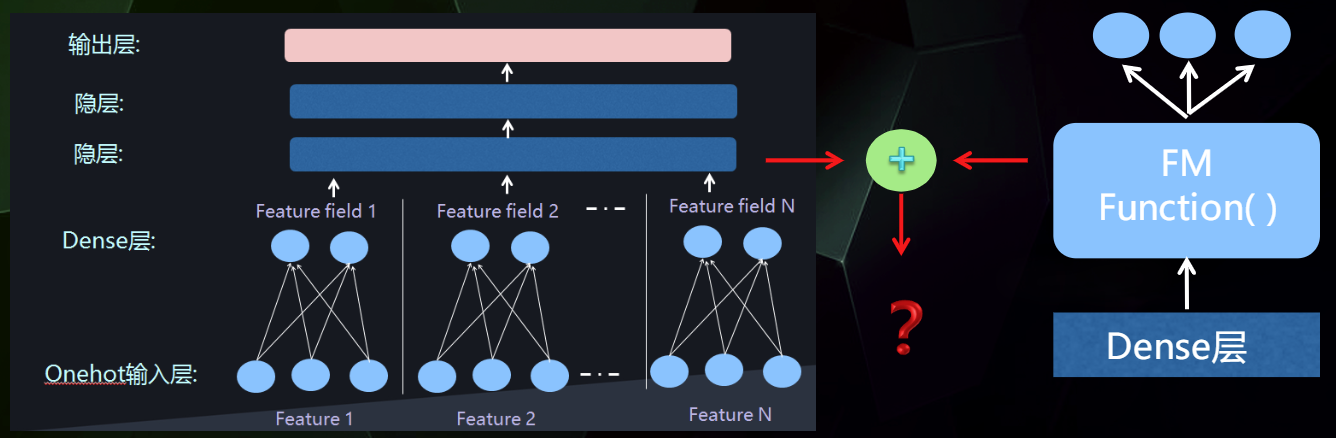
网络融合的结构
串行结构
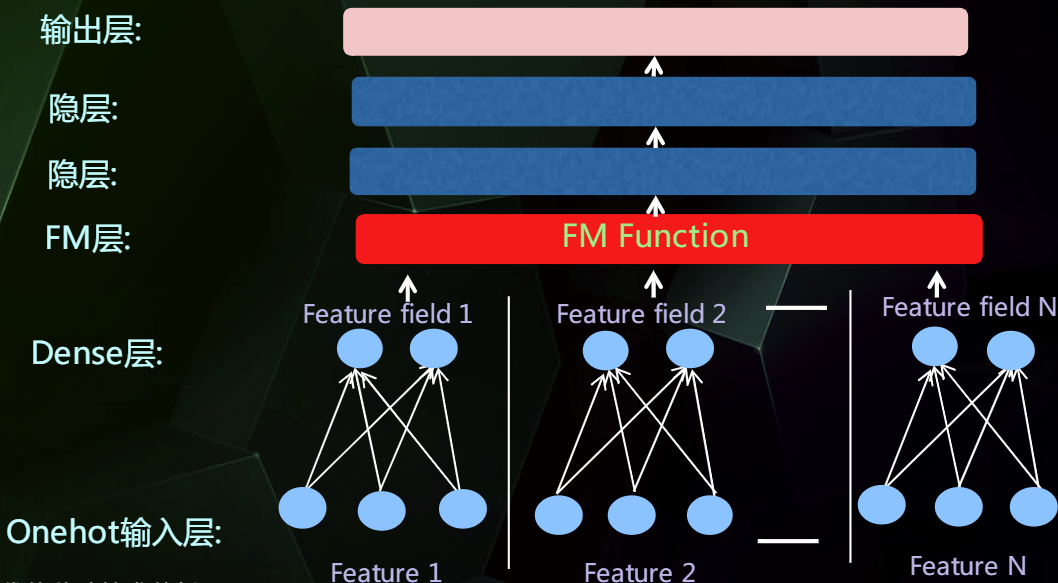
并行结构
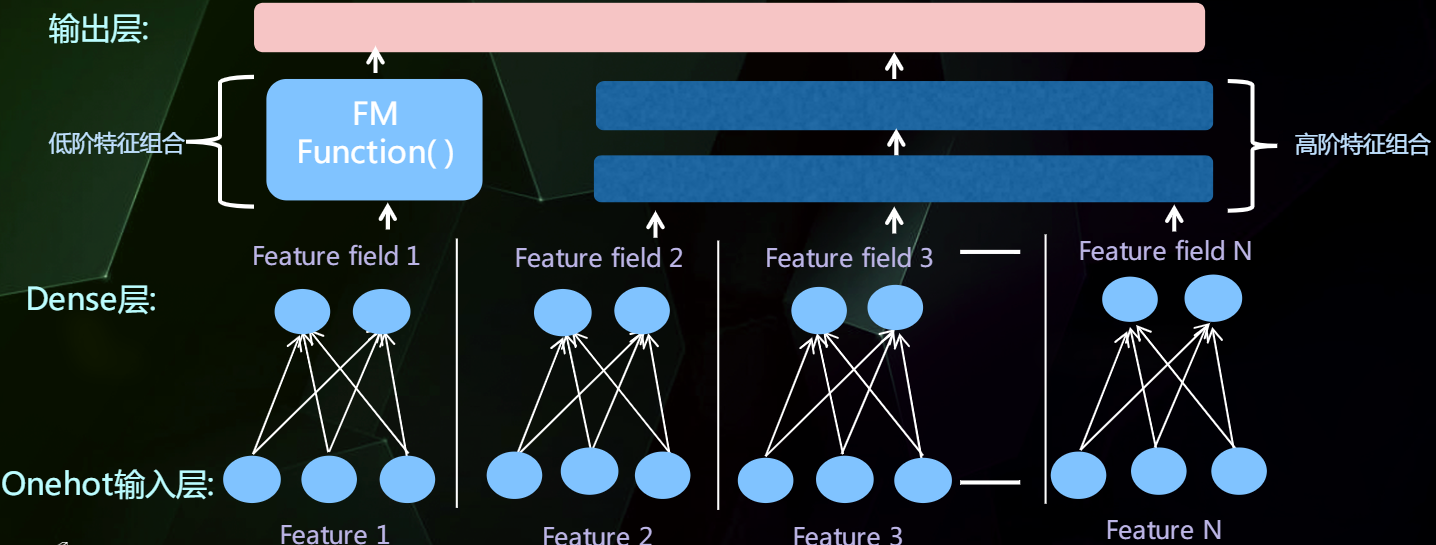
Wide&Deep模型就是典型的并行结构。
DeepFM模型结构和原理
我们先来看下DeepFM模型的结构:
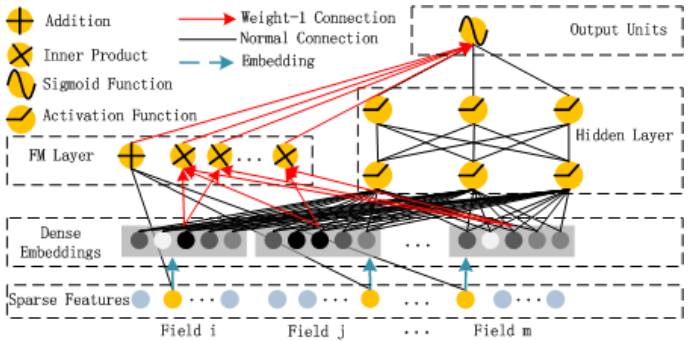
可以发现模型结构由FM与DNN两部分组成,FM负责低阶特征的组合提取,DNN负责高阶特征的组合提取,这两部分共享同一的输入,预测结果是对FM和DNN的结果一起做Embedding,可以如下表示:
y
^
=
s
i
g
m
o
i
d
(
y
F
M
+
y
D
N
N
)
\hat{y}=sigmoid(y_{FM}+y_{DNN})
y^=sigmoid(yFM+yDNN)
FM 部分
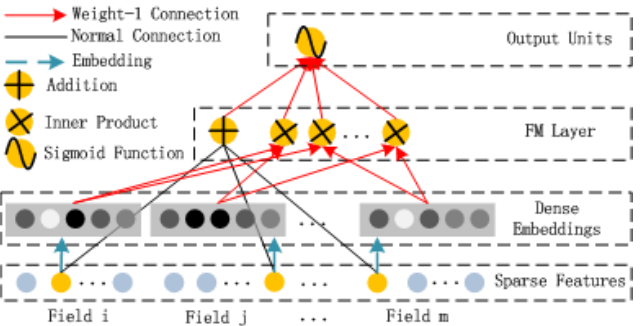 $$ \hat{y}_{FM}(x)=w_0+\sum^{N}_{i=1}{w_ix_i}+\sum^N_{i=1}\sum^N_{j=i+1}v^T_iv_jx_ix_j $$ 由上图和公式大致可以看出FM部分是由一阶特征和二阶特征Concatenate到一起再经过一个Sigmoid得到logits,所以在实现的时候要分别考虑线性相加部分和FM交叉特征部分。
$$ \hat{y}_{FM}(x)=w_0+\sum^{N}_{i=1}{w_ix_i}+\sum^N_{i=1}\sum^N_{j=i+1}v^T_iv_jx_ix_j $$ 由上图和公式大致可以看出FM部分是由一阶特征和二阶特征Concatenate到一起再经过一个Sigmoid得到logits,所以在实现的时候要分别考虑线性相加部分和FM交叉特征部分。
Deep部分
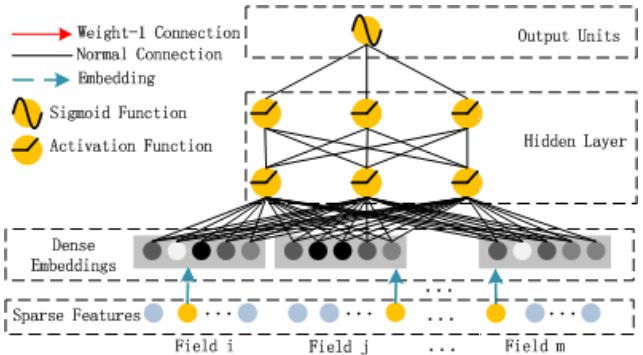
在第一层隐藏层之前,引入一个Embedding层将高维稀疏向量转为低维稠密向量,以解决参数爆炸问题。Embedding层的结构如下图所示:
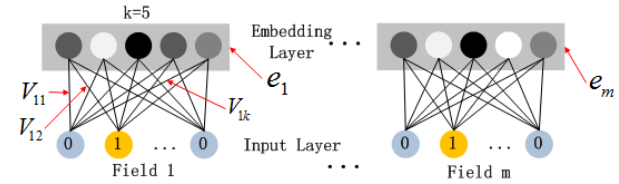
这里需要注意的是尽管Field的输入长度不同,但是Embedding之后向量的长度均为K。另外FM里面得到的隐变量$ V_{ik}
作为
E
m
b
e
d
d
i
n
g
层网络的权重。
E
m
b
e
d
d
i
n
g
层的输出是将所有
i
d
类特征对应
e
m
b
e
d
d
i
n
g
向量
c
o
n
c
a
t
到一起输入到
D
N
N
中。其中
作为Embedding层网络的权重。Embedding层的输出是将所有id类特征对应embedding向量concat到一起输入到DNN中。其中
作为Embedding层网络的权重。Embedding层的输出是将所有id类特征对应embedding向量concat到一起输入到DNN中。其中v_i
表示第
表示第
表示第i
个
f
i
e
l
d
的
e
m
b
e
d
d
i
n
g
,
个field的embedding,
个field的embedding,m$是field的数量。我们得到第一层的输入:
z
1
=
[
v
1
,
v
2
,
⋯
,
v
m
]
z_1=[v_1,v_2,\cdots,v_m]
z1=[v1,v2,⋯,vm]
把上一层的输出作为下一层的输入,得到:
z
L
=
σ
(
W
L
−
1
z
L
−
1
+
b
L
−
1
)
z_L=\sigma(W_{L-1}z_{L-1}+b_{L-1})
zL=σ(WL−1zL−1+bL−1)
其中
σ
\sigma
σ是激活函数,
z
z
z表示该层的输入,
W
W
W表示该层的权重,
b
b
b表示偏置。
DNN部分输出如下:
y
^
D
N
N
=
σ
(
W
L
α
L
+
b
L
)
\hat{y}_{DNN}=\sigma{(W^L\alpha^L+b^L)}
y^DNN=σ(WLαL+bL)
总结
DeepFM模型大致由两部分组成,分别为FM和DNN,而FM部分又由一阶特征部分和二阶特征交叉部分组成,所以模型大概可以拆成三部分,分别为FM一阶特征Linear部分,二阶特征交叉部分和DNN的高阶特征交叉部分。
两个思考题
-
如果对于FM采用随机梯度下降SGD训练模型参数,请写出模型各个参数的梯度和FM参数训练的复杂度
FM的模型方程为:
y ( x ) = w 0 + ∑ i = 1 n w i x i + ∑ i = 1 n ∑ j = i + 1 n w i j x i x j y(x)=w_0+\sum^{n}_{i=1}{w_ix_i}+\sum^{n}_{i=1}\sum^{n}_{j=i+1}{w_{ij}x_ix_j} y(x)=w0+i=1∑nwixi+i=1∑nj=i+1∑nwijxixj
如果直接计算,复杂度为 O ( n ˉ 2 ) O(\bar{n}^2) O(nˉ2),其中 ∑ i = 1 n ∑ j = i + 1 n w i j x i x j \sum^{n}_{i=1}\sum^{n}_{j=i+1}{w_{ij}x_ix_j} ∑i=1n∑j=i+1nwijxixj可化简为,复杂度为 O ( n ˉ ) O(\bar{n}) O(nˉ).
∑ i = 1 n ∑ j = i + 1 n w i j x i x j = ∑ i = 1 n ∑ j = i + 1 n ∑ k = 1 n v i k v j k x i x j = 1 2 ∑ k = 1 n ( ( ∑ i = 1 n v i k x i ) 2 − ∑ i = 1 n v i k x i 2 ) \begin{equation} \begin{aligned} \sum^{n}_{i=1}\sum^{n}_{j=i+1}{w_{ij}x_ix_j} &=\sum^{n}_{i=1}\sum^{n}_{j=i+1}\sum_{k=1}^{n}{v_{ik}v_{jk} }x_ix_j\\ &={1\over2}\sum_{k=1}^{n}((\sum_{i=1}^{n}v_{ik}x_i)^2-\sum_{i=1}^{n}{v_{ik}x_i^2}) \end{aligned} \end{equation} i=1∑nj=i+1∑nwijxixj=i=1∑nj=i+1∑nk=1∑nvikvjkxixj=21k=1∑n((i=1∑nvikxi)2−i=1∑nvikxi2)利用SGD(Stochastic Gradient Descent)训练模型,模型各个参数的梯度如下:
KaTeX parse error: Unknown column alignment: * at position 70: …{\begin{array}{*̲{20}{c} } {1,if… -
对于下图所示,根据你的理解Sparse Feature中的不同颜色节点分别表示什么意思?

不同的颜色对应的是稀疏特征向量中不同维度不同的值。浅蓝色表示对应的类别特征的onehot向量,黄色的点表示有效值(1),浅蓝色的点表示无效值(0)。
代码实现
我们还是按照代码的执行顺序来学习DeepFM的实现逻辑,使用的数据集还是criteo。首先是main函数:
if __name__ == "__main__":
# 读取数据
data = pd.read_csv('./data/criteo_sample.txt')
# 划分dense和sparse特征
columns = data.columns.values
dense_features = [feat for feat in columns if 'I' in feat]
sparse_features = [feat for feat in columns if 'C' in feat]
# 简单的数据预处理
train_data = data_process(data, dense_features, sparse_features)
train_data['label'] = data['label']
# 将特征分组,分成linear部分和dnn部分(根据实际场景进行选择),并将分组之后的特征做标记(使用DenseFeat, SparseFeat)
linear_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
dnn_feature_columns = [SparseFeat(feat, vocabulary_size=data[feat].nunique(),embedding_dim=4)
for i,feat in enumerate(sparse_features)] + [DenseFeat(feat, 1,)
for feat in dense_features]
# 构建DeepFM模型
history = DeepFM(linear_feature_columns, dnn_feature_columns)
history.summary()
history.compile(optimizer="adam",
loss="binary_crossentropy",
metrics=["binary_crossentropy", tf.keras.metrics.AUC(name='auc')])
# 将输入数据转化成字典的形式输入
train_model_input = {name: data[name] for name in dense_features + sparse_features}
# 模型训练
history.fit(train_model_input, train_data['label'].values,
batch_size=64, epochs=5, validation_split=0.2, )
数据预处理部分和特征分组部分在前两部分有所解释,这里不再赘述。FM部分实现如下:
def DeepFM(linear_feature_columns, dnn_feature_columns):
# 构建输入层,即所有特征对应的Input()层,这里使用字典的形式返回,方便后续构建模型
dense_input_dict, sparse_input_dict = build_input_layers(linear_feature_columns + dnn_feature_columns)
# 将linear部分的特征中sparse特征筛选出来,后面用来做1维的embedding
linear_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), linear_feature_columns))
# 构建模型的输入层,模型的输入层不能是字典的形式,应该将字典的形式转换成列表的形式
# 注意:这里实际的输入与Input()层的对应,是通过模型输入时候的字典数据的key与对应name的Input层
input_layers = list(dense_input_dict.values()) + list(sparse_input_dict.values())
# linear_logits由两部分组成,分别是dense特征的logits和sparse特征的logits
linear_logits = get_linear_logits(dense_input_dict, sparse_input_dict, linear_sparse_feature_columns)
# 构建维度为k的embedding层,这里使用字典的形式返回,方便后面搭建模型
# embedding层用户构建FM交叉部分和DNN的输入部分
embedding_layers = build_embedding_layers(dnn_feature_columns, sparse_input_dict, is_linear=False)
# 将输入到dnn中的所有sparse特征筛选出来
dnn_sparse_feature_columns = list(filter(lambda x: isinstance(x, SparseFeat), dnn_feature_columns))
fm_logits = get_fm_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers) # 只考虑二阶项
# 将所有的Embedding都拼起来,一起输入到dnn中
dnn_logits = get_dnn_logits(sparse_input_dict, dnn_sparse_feature_columns, embedding_layers)
# 将linear,FM,dnn的logits相加作为最终的logits
output_logits = Add()([linear_logits, fm_logits, dnn_logits])
# 这里的激活函数使用sigmoid
output_layers = Activation("sigmoid")(output_logits)
model = Model(input_layers, output_layers)
return model
















 3213
3213

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











