







任务二:点云目标分割(3D object detection)
和二维图像目标检测一样,分为two-stage methods( 或者说Region Proposal-based Methods) 和 single-shot methods(直接回归目标框)。主要研究Two-stage methods, 包括四类:
- BEV-based methods
- Voxel based methods
- Segmentation-based methods
- Frustum-based methods

1. BEV-based methods
这种方法一般是在BEV(俯视图)中生成 3D Proposal , 然后投影到多个视图中,比如LiDAR前视图,RGB图中提取特征。然后将不同视角获得的区域特征进行组合,以预测定向的3D框。既然是多视角,所以必然存在投影问题和投影后的特征融合问题。
- 投影就是将不规则点云投影到规则的平面栅格图像中,或直接对其进行三维体素化再投影。
- 在前视图即相机视角,可以引入RGB图像提取丰富的纹理特征。
- 在俯视图中生成 3D Proposal 可以避免物体重叠,有利于目标的定位。
- 这类方法最关键的就是如何融合多视图特征,增强目标的特征表达。
典型的方法有:MV3D和AVOD
地址:https://blog.csdn.net/qq_24505417/article/details/108784909
2. Voxel based methods
将点云数据划分到有空间依赖关系的voxel,再使用3D卷积等方式来进行处理,最后通过RPN等方法生成高精度的建议框。这种方法的精度依赖于三维空间的分割细腻度,而且3D卷积的运算复杂度也较高。
典型的方法有:VoxelNet
地址:https://blog.csdn.net/qq_24505417/article/details/108800027
3. Segmentation-based methods
先对点云进行分割,利用现有的语义分割技术来去除大多数背景点,然后在前景点上生成大量高质量的建议框以节省计算量,用分割后的点云特征来回归3D box以及类别预测。类似Faster RCNN中用roi中所有像素的特征回归2D box,并分类。 三维中就是将二维栅格用点云代替,进行三维box回归和分类。
典型的方法:PointRCNN(港中文,纯粹使用点云数据完成三维目标检测任务)、PointPainting
地址:https://blog.csdn.net/qq_24505417/article/details/108784701
4. Frustum-based methods
先定位再分割再回归,与Segmentation-based methods方法顺序颠倒。并且将目标定位问题交给二维图像处理,然后收集视锥(相机中心向目标框四个点发出无限远的光线形成视锥)所包含的三维空间中的点云,对这部分点云进行前后景分割,得到单个目标的点云。3D box的生成与Segmentation-based methods一致,也是点云特征回归。
经典的方法是Frustum PointNet、Point-SENet。
这些方法可以有效地建议3D对象的可能位置,但分步流水操作使其性能受到2D图像检测器的限制。
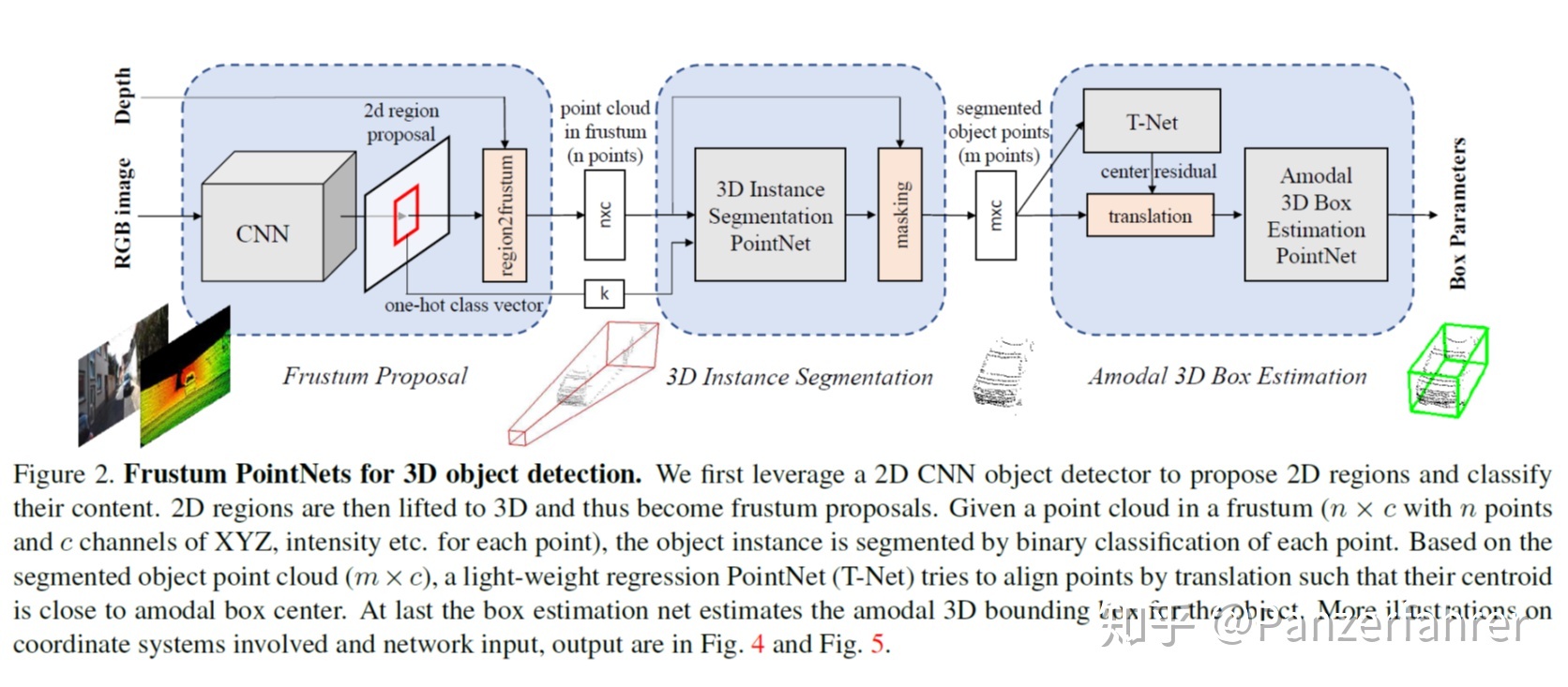
还有一些不错的方法,后面再看。
港中文&商汤科技发表的Part-A2 Net
地址:
海康威视的Voxel-FPN
地址:
PV-RCNN: Point-Voxel Feature Set Abstraction for 3D Object Detection
地址:
参考:https://blog.csdn.net/taifengzikai/article/details/104109562














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









