







Brief
以lidar数据为深度学习网络输入的3D目前检测自18年CVPR的voxelnet和F-pointnet发表以来,分别衍生了voxel-based的方法和point-based的方法。
基于voxel的方法的发展,但是当时voxel-based的voxelnet由于3D CNN的使用导致很大的显存占用,18年sensors的ECOND引入了稀疏卷积使得内存占用大大减少,同时该文引入了一个从标注集合sample的数据增广方案,次年的CVPR19的pointpillars则是直接将voxel改进为pillar直接跳过了3D卷积这一步骤,后续的19年ICCV则是将基于voxel的方法的参数优化(由于稀疏卷积的引入,使得更小的voxel可以被使用)以及改进为两阶段的方法fast pointrcnn,其中STD是直接将体素划分改为了球体划分(具有更好的方向性)。同样的19年的NIPS的文章有开始考虑从整个场景中粗略的先注意到大致的object,再对该场景进行划分。该类的方法的核心思想就是把点云的无序性通过体素划分使其规整,但是不可避免的会有信息丢失。
基于Point的方法比较难以解决的是场景点云的无序性问题,19年的CVPR的Point RCNN是一篇完全基于点做的3D目标检测方法,但是该方法采用的anchor设置是对每一个场景点都会认为是,会造成很大的冗余,后续再次基础上延展性不是很大。
当然19年还有很多好的工作,比如CVPRW19中有文章采用RNN+attention的方式将大场景的点云裁缝后再送入RNN结构中,还有一些从小处入手的工作,将二维目标检测的IOU Loss引入到三维点云结构中;由于稀疏卷积的引入,将子流型卷积和3D稀疏卷积结构融合设计的3D backbone等等;为了提升效率,将voxel和point方式结合的方法等等
总结来说,19年前面在开展onestage的基础架构,后面则是着重优化的two-stage的方法;CVPR2020的一些工作,更加具有创新性和朴实性;目前霸榜的PVRCNN采用将voxel和point结构结合的方法,采用少的信息丢失,可变感受野的point-based方法和快速规整的voxel-based的方法结合,同时两阶段的方法也使得才结构的精度更高;part^2net 则是通过稀疏卷积和子流型卷积设计出了一个U结构,通过分割优化检测效果,此外,更具有创新性的point-GNN则是将在点云语义分割发展一年的GNN结构引入到3D场景的目标检测上来,但是该方法的时间效率不容乐观,这也是GNN的通病;此外,anchor-free的方法也出现了,obj-as-hotspots这篇文章则是摒弃了前人都采用的object级别的anchor设置,而是根据原始点云到fea map的映射关系得到设置hotspot。可以说也是百花齐放了,此外,更多的数据集Nuscence和A*3D的出现使得更多的研究在新的数据集上。
本文带来的是一个对3D点云目标检测的数据增广的量化研究。
Abstruct
- 该文的主要内容是在pointpillars的基础上做的,主要内容是对比了各种的数据增广操作,包括了local和global的数据增广。
- global数据增广则是对全场景的数据增广,local的数据增广是对单个属于某个物体的数据增广。
- 以开源的工作
I. INTRODUCTION
- 自动驾驶的溯源
- contribution
(1)an in-depth study of augmentation methods for LiDAR based 3D Object Detection
(2)show some nonintuitive results
II. RELATED WORK
也就是voxel-based、point-based、point_and_voxel methods
III. METHOD
global augmentations
Global Translation
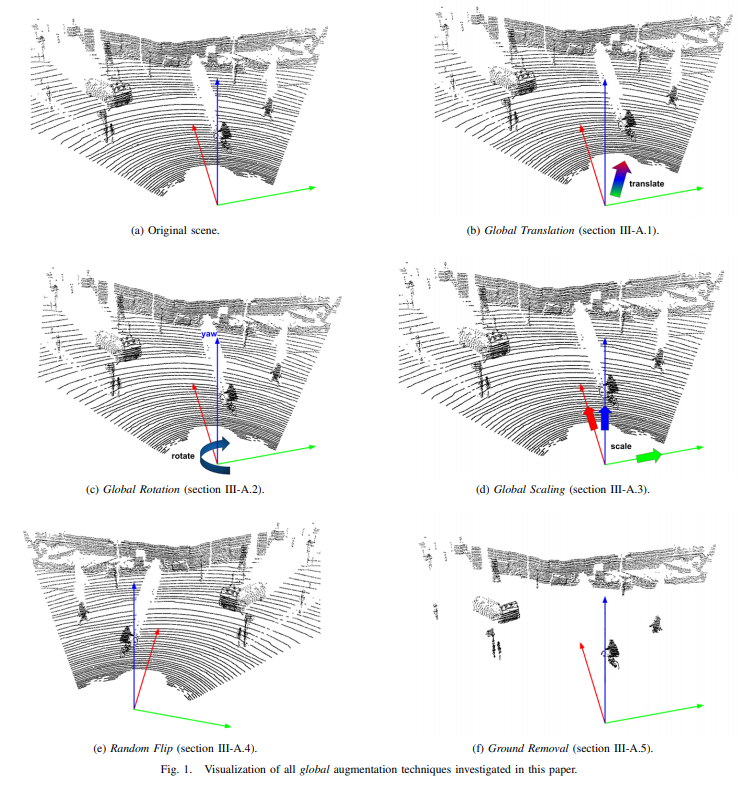
确乎有些无聊,也就是对整个场景的数据做这些变换
B. Local Augmentation
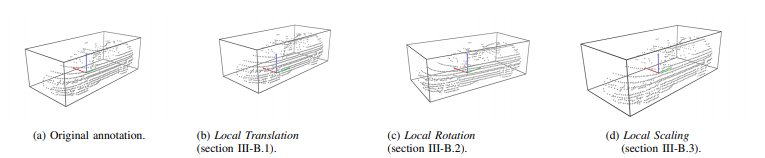
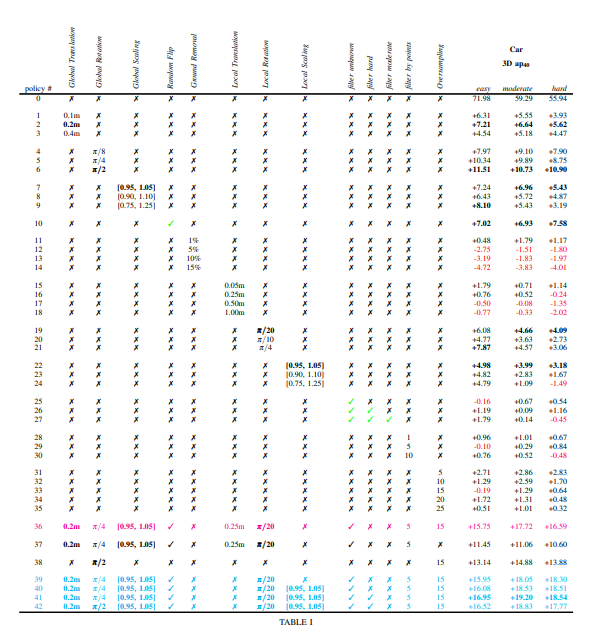
实验
这应该是算读过的比较简单的文章了吧QAQ。可以看的出实验还是做了一些,不过文章还是显得有些单薄,不做深入研究了。















 7524
7524











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









