







PaddlePaddle|CV疫情特辑(三):车牌识别
本节内容来自:百度AIstudio课程
做一个记录。
本次方法和PaddlePaddle|CV疫情特辑(二):手势识别 基本一致,所以只说改动和差异。
1.数据集通道改变
- 首先数据集一个有65类
- 数据集的大小(shape)为
1
∗
20
∗
20
1*20*20
1∗20∗20,即每张图片只有
20
∗
20
20*20
20∗20的大小,且为单通道。
所以需要对resnet-18进行修改: - 通道改变:
# ResNet的第一个模块,包含1个7x7卷积,后面跟着1个最大池化层
self.conv = ConvBNLayer(
num_channels=1, # 3 -> 1
num_filters=64,
filter_size=7,
stride=2,
act='relu')
由于图片太小,
- 最后一层的池化层的卷积核的size不需要 7 7 7那么大,虽然设置为 7 7 7也没问题,但是会参数冗余:
# 在c5的输出特征图上使用全局池化
self.pool2d_avg = Pool2D(pool_size=1, pool_type='avg', global_pooling=True) # 7--> 1
2. 训练与测试
- 和PaddlePaddle|CV疫情特辑(二):手势识别 一致,使用带softmax的交叉熵作为损失函数。
- 使用余弦退火作为学习率衰减策略。
resnet-18最终的准确率:0.98526263
resnet-50最终的准确率:0.98607314
提高了0.8%…
3. 分割车牌
# 对车牌图片进行处理,分割出车牌中的每一个字符并保存
license_plate = cv2.imread('./车牌.png')
gray_plate = cv2.cvtColor(license_plate, cv2.COLOR_RGB2GRAY)
ret, binary_plate = cv2.threshold(gray_plate, 175, 255, cv2.THRESH_BINARY)
result = []
for col in range(binary_plate.shape[1]):
result.append(0)
for row in range(binary_plate.shape[0]):
result[col] = result[col] + binary_plate[row][col]/255
character_dict = {}
num = 0
i = 0
while i < len(result):
if result[i] == 0:
i += 1
else:
index = i + 1
while result[index] != 0:
index += 1
character_dict[num] = [i, index-1]
num += 1
i = index
for i in range(8):
if i==2:
continue
padding = (170 - (character_dict[i][1] - character_dict[i][0])) / 2
ndarray = np.pad(binary_plate[:,character_dict[i][0]:character_dict[i][1]], ((0,0), (int(padding), int(padding))), 'constant', constant_values=(0,0))
ndarray = cv2.resize(ndarray, (20,20))
cv2.imwrite('./' + str(i) + '.png', ndarray)
def load_image(path):
img = paddle.dataset.image.load_image(file=path, is_color=False)
img = img.astype('float32')
img = img[np.newaxis, ] / 255.0
return img
简单分析一下这段代码:
-
首先由于训练集都是黑白图,所以需要把车牌图片也进行相应的转换:
gray_plate = cv2.cvtColor(license_plate, cv2.COLOR_RGB2GRAY),先转换成灰度图 -
接着把灰度图进行阈值分割:
ret, binary_plate = cv2.threshold(gray_plate, 175, 255, cv2.THRESH_BINARY),转换成黑白图。
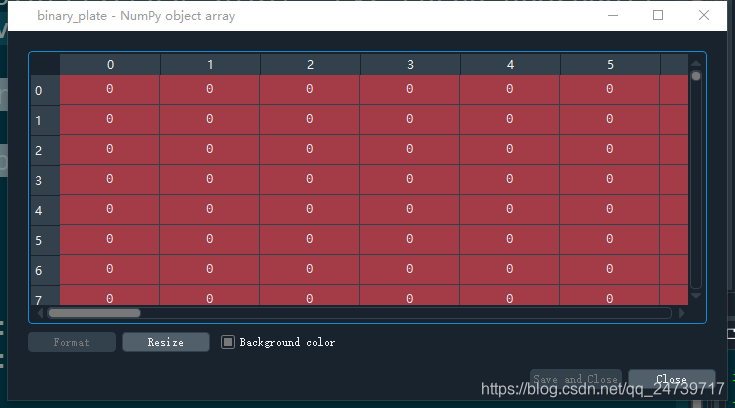
binary_plate 则保存的是阈值分割过后的二值图像:
result则按列保存像素值结果:
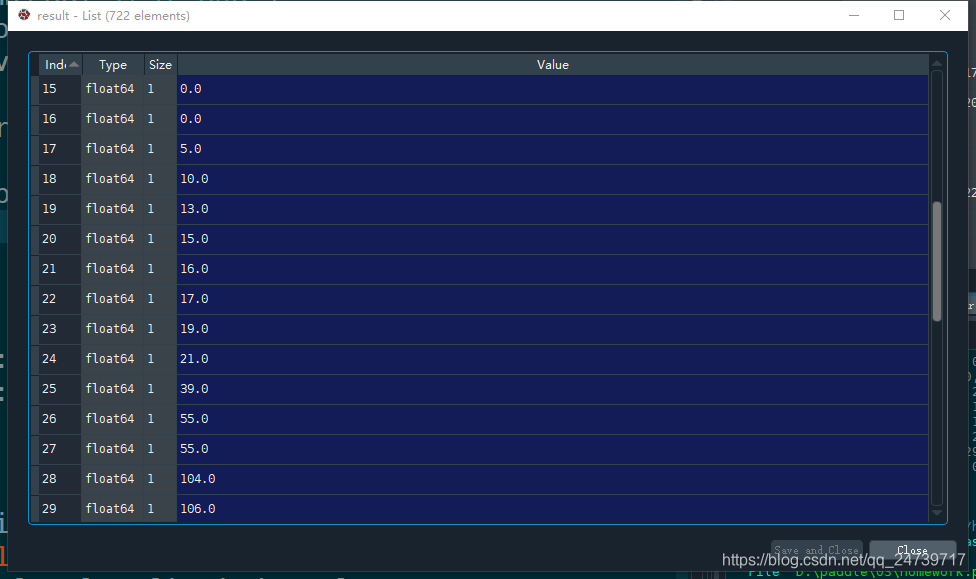
然后字符是按照result[i] == 0进行分割的,因为二值化之后,如果能够地方没有字符,那么像素值之后为0。为什么循环8次呢?因为车牌有8个字符,即包括 中间那个点。

切割后的结果:

将车牌的所有字符进行转换:
将标签进行转换
print('Label:',LABEL_temp)
match = {'A':'A','B':'B','C':'C','D':'D','E':'E','F':'F','G':'G','H':'H','I':'I','J':'J','K':'K','L':'L','M':'M','N':'N',
'O':'O','P':'P','Q':'Q','R':'R','S':'S','T':'T','U':'U','V':'V','W':'W','X':'X','Y':'Y','Z':'Z',
'yun':'云','cuan':'川','hei':'黑','zhe':'浙','ning':'宁','jin':'津','gan':'赣','hu':'沪','liao':'辽','jl':'吉','qing':'青','zang':'藏',
'e1':'鄂','meng':'蒙','gan1':'甘','qiong':'琼','shan':'陕','min':'闽','su':'苏','xin':'新','wan':'皖','jing':'京','xiang':'湘','gui':'贵',
'yu1':'渝','yu':'豫','ji':'冀','yue':'粤','gui1':'桂','sx':'晋','lu':'鲁',
'0':'0','1':'1','2':'2','3':'3','4':'4','5':'5','6':'6','7':'7','8':'8','9':'9'}
L = 0
LABEL ={}
for V in LABEL_temp.values():
LABEL[str(L)] = match[V]
L += 1
print(LABEL)
输出:
Label: {'0': 'E', '1': 'gan', '2': 'zang', '3': 'R', '4': 'shan', '5': 'L', '6': 'gan1', '7': 'S', '8': '8', '9': 'D', '10': 'gui', '11': 'jing', '12': 'C', '13': 'gui1', '14': '4', '15': 'N', '16': 'X', '17': 'K', '18': 'qing', '19': '6', '20': 'U', '21': 'hu', '22': 'Y', '23': 'A', '24': 'xin', '25': '9', '26': '7', '27': 'jin', '28': 'B', '29': 'P', '30': 'jl', '31': 'wan', '32': '1', '33': 'F', '34': 'min', '35': 'cuan', '36': '3', '37': 'su', '38': 'Q', '39': 'xiang', '40': 'yun', '41': '2', '42': 'ning', '43': 'T', '44': 'W', '45': 'V', '46': 'H', '47': 'J', '48': 'sx', '49': 'lu', '50': '5', '51': 'G', '52': 'Z', '53': 'yu', '54': 'ji', '55': 'zhe', '56': 'liao', '57': 'M', '58': 'yue', '59': 'hei', '60': 'e1', '61': '0', '62': 'meng', '63': 'yu1', '64': 'qiong'}
{'0': 'E', '1': '赣', '2': '藏', '3': 'R', '4': '陕', '5': 'L', '6': '甘', '7': 'S', '8': '8', '9': 'D', '10': '贵', '11': '京', '12': 'C', '13': '桂', '14': '4', '15': 'N', '16': 'X', '17': 'K', '18': '青', '19': '6', '20': 'U', '21': '沪', '22': 'Y', '23': 'A', '24': '新', '25': '9', '26': '7', '27': '津', '28': 'B', '29': 'P', '30': '吉', '31': '皖', '32': '1', '33': 'F', '34': '闽', '35': '川', '36': '3', '37': '苏', '38': 'Q', '39': '湘', '40': '云', '41': '2', '42': '宁', '43': 'T', '44': 'W', '45': 'V', '46': 'H', '47': 'J', '48': '晋', '49': '鲁', '50': '5', '51': 'G', '52': 'Z', '53': '豫', '54': '冀', '55': '浙', '56': '辽', '57': 'M', '58': '粤', '59': '黑', '60': '鄂', '61': '0', '62': '蒙', '63': '渝', '64': '琼'}
接下来就是加载模型并进行车牌识别:
构建预测动态图过程
with fluid.dygraph.guard():
# model=MyLeNet()#模型实例化
# model = ResNet("ResNet", layers = 18, class_dim = 65)
model = ResNet("ResNet", layers = 50, class_dim = 65)
model_dict,_=fluid.load_dygraph('MyLeNet')
model.load_dict(model_dict)#加载模型参数
model.eval()#评估模式
lab=[]
for i in range(8):
if i==2:
continue
infer_imgs = []
infer_imgs.append(load_image('./' + str(i) + '.png'))
infer_imgs = np.array(infer_imgs)
infer_imgs = fluid.dygraph.to_variable(infer_imgs)
result=model(infer_imgs)
lab.append(np.argmax(result.numpy()))
# print(lab)
display(Image.open('./车牌.png'))
print('\n车牌识别结果为:',end='')
for i in range(len(lab)):
print(LABEL[str(lab[i])],end=''
输出:
车牌识别结果为:鲁A686EJ















 1589
1589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









