







机器学习技法 Lecture10: Random Forest
Random Forest Algorithm
回忆一下之前讲的两个算法,bagging与decision tree。

它们都有一些aggregation的成分,但是各自的差别也很明显。比如bagging是为了减少基函数结果的方差的,而decision tree有时候会导致比较大的方差。但是如果把这两个算法合到一起会怎么样?

把这两个合到一起就有了随机森林。森林很好理解,好多个树组成的算法叫森林很合理,而随机性体现在了很多方面,下面慢慢说。合并后的算法继承了决策树算法的优点,而且也没有了fully-grown的树的缺点。同时又有很好的并行性。
之前说到使用aggregation算法一般会增大基函数的差异性,这样合成后的算法效果会比较好。一般来说bagging里用的是抽取数据带来数据的差异性,但是还有一些其它方面的差异性:

比如在随机森林里可以在每个决策树分支的时候对样本特征进行筛选,只关注一小部分的特征。相当于对样本x做了一个非线性映射,映射到一个维度更小的空间里,而每个分支时选择的特征维度是随机的。

而这个特征挑选的想法也可以用到其它的算法中去。而这个挑选某些维度特征的想法可以写为矩阵映射的形式:

而且挑选某个特征作为分支的凭据相当于是映射矩阵P的每一行都是一个空间的自然基,也就是有一维是1其它都是0。而更一般化也能带来更多差异性的方式是让P的每一行都是一个普通的向量,这样得到的结果就相当于不同维度特征的线性组合,把它作为决策树选择分支的凭证:

这样得到的随机森林就更加具有随机性。
Out-Of-Bag Estimate
再回顾一下bagging算法:

因为每个基函数都是会抽取一部分样本作为训练数据,那么就会有没被抽取到的数据,用红色星号表示。这些数据对对应的基函数
g
t
g_{t}
gt来说叫做out-of-bag袋外数据。可以简单算一下对于每个基函数来说袋外数据的大小:

一个简单的推导,发现每个基函数大概会留下
N
/
e
N/e
N/e个样本作为袋外数据。由于袋外数据训练基函数的时候没有被用到,我们很自然就想到是否可以用它来作为验证集合。
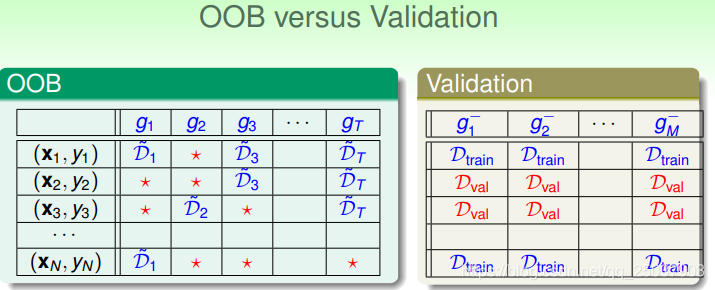
可以看出袋外数据与验证集数据很类似。实际上也可以做,不过有些注意的地方,那就是每个基函数的袋外数据都是不一样的,但是又不能只用来验证一个个基函数
g
t
g_{t}
gt,所以就需要一定的平均。最终得到
G
G
G的袋外错误来作为验证的结果。

而使用袋外错误作为选择随机森林结果的标准不需要重新的训练最终结果,而且一般来说对实际数据的指导效果非常精确。
Feature Selection
可以稍微提一些特征选择的问题。有时候数据中有很多特征,但是有些特征是冗余或者不相关的,想去掉这些特征,只留下对任务有用的特征。

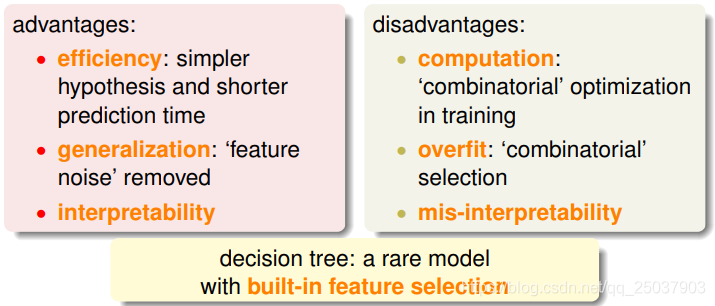
做特征选择有一些好处,比如会提高算法效率,更好的泛化性能以及带来更好的解释性。但是也有一些坏处,比如特征选择需要很大计算量,容易过拟合甚至导致错误的解释等等。
假如我们知道每一个特征的重要性,那么就能很简单的选择特征。得到特征重要性的一个最简单的方式是根据线性模型中每个特征的系数:

每个特征系数的绝对值就代表了这个特征的重要性。但是这个方法对于非线性模型没法应用。但是使用随机森林就可以简单的得到每个特征的重要性。
使用随机森林选择特征的想法是,将每个特征进行随机化,如果随机化之后对性能影响比较大就说明这个特征比较重要。而性能使用之前讲的袋外错误来表示的。

不过这里有个问题,就是特征随机化如何来做。如果是加入其它的分布作为噪声会导致原来的特征分布有所变化,评测的结果可能有额外的影响。所以使用一个permutation的方法,就是将特定维度的特征值在所有样本中进行打乱的操作。这样保持了原来特征的分布也带来了随机性。

特征的重要性就用打乱之后带来的性能下降来表示:

但是如果简单的这样做依然需要对模型在新数据上进行重新训练,非常麻烦。因此我们使用了一个取巧的方式,那就是模型本身不变,只改变用来评测性能时候的验证集。这样也能够说明性能的下降。(应该不完全等同吧?大概实际很好用就是了。)

Random Forest in Action
在实际使用中随机森林表现如何呢?

可以看出边界比较平滑,而且正负例到判别界面的距离都很远。
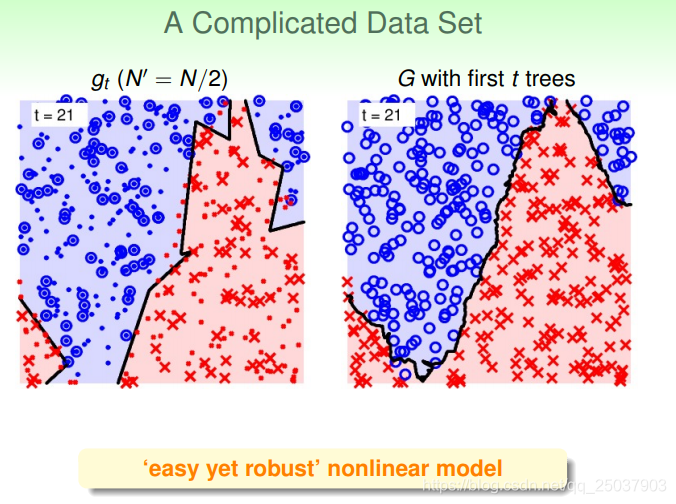
对于比较复杂的目标函数也有比较强的拟合能力。
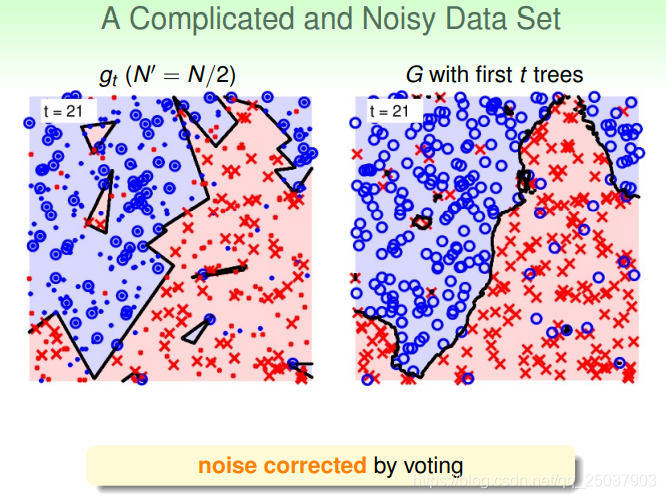
对于比较复杂而且带了噪音的数据,同样能够通过aggregation得到比较好的结果。
那么就会有一个问题,随机森林中决策树的数量如何选择?理论上是越多越好。一般来说这个不太好说,需要在实际使用中来判断。如果计算量足够的情况下,可以选择增加决策树数量直到结果能够保持一定的稳定性为止。















 1233
1233











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









