







Token和Tokenizer
你应该知道大模型的输入输出的单位是token,不是单词,也不是字母【在中文语境,不是词,不是字】,那么,token是什么呢?
虽然我们经常直接用token,但有的文献会翻译为标记。下文中看到标记,代表token。
Token是使用Tokenizer(翻译为分词器)分词后的结果,Tokenizer是什么呢?Tokenizer是将文本分割成token的工具。
在大模型中,Tokenizer有三种常见的分词方式:word level,char level,subword level。我们会用几篇小短文来讲解这三种分词方式。同时,我会从英文(拉丁语系)和中文(汉语系)两个语言的角度来讲解。
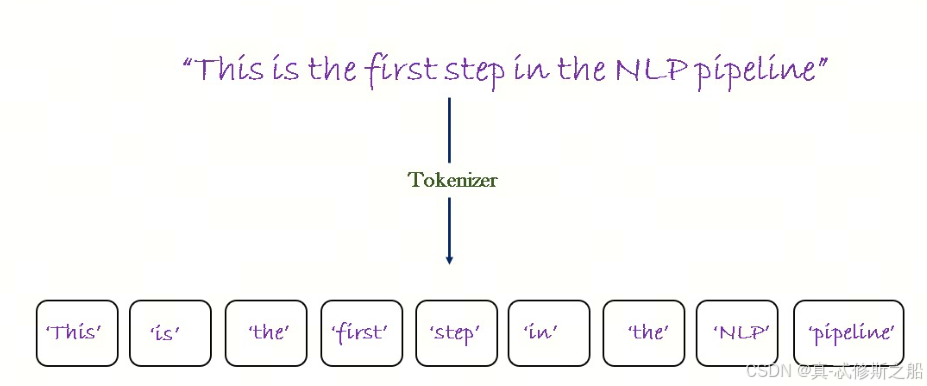
1. word level
英文:
word level是最简单的分词方式,就是将文本按照空格或者标点分割成单词。
比如,下面的句子:
Let’s do some NLP tasks.
按照空格分词后,得到的token是:
Let’s, do, some, NLP, tasks.
按照标点分词后,得到的token是:
Let, ', s, do, some, NLP, tasks, .
中文:
在中文中,分词是一个比较复杂的问题。中文没有空格,所以分词的难度要比英文大很多。下面举个例子:
我们来做一个自然语言处理任务。
一个可能的分词结果是:
我们,来,做,一个,自然语言处理,任务。
这种分词方式的优点是简单易懂,缺点是无法处理未登录词(Out-of-Vocabulary,简称OOV)。我们熟悉的jieba分词就是基于这种分词方式的。
jieba分词基于统计和规则的方法,结合了TF-IDF算法、TextRank算法等多种技术,通过构建词图(基于前缀词典)并使用动态规划查找最大概率路径来确定分词结果。此外,对于未登录词,jieba分词使用了基于汉字成词能力的HMM(隐马尔科夫模型)和Viterbi算法来进行识别和分词.
2. Character level
英文:
Character level是将文本按照字母级别分割成token。这样的好处是
- 词汇量要小得多;
- OOV要少得多,因为每个单词都可以从字符构建。
比如,下面的句子:
Let’s do some NLP tasks.
按照字母分词后,得到的token是:
L, e, t, ', s, d, o, s, o, m, e, N, L, P, t, a, s, k, s, .
中文:
在中文中,Character level是将文本按照字级别分割成token。
比如,下面的句子:
我们来做一个自然语言处理任务。
按照字分词后,得到的token是:
我,们,来,做,一,个,自,然,语,言,处,理,任,务,。
这种方法也不是完美的。基于字符而不是单词,从直觉上讲意义不大:在英文中每个字母本身并没有多大意义,单词才有意义。然而在中文中,每个字比拉丁语言中的字母包含更多的信息。
另外,我们的模型最终会处理大量的token:使用基于单词(word)的标记器(tokenizer),单词只会是单个标记,但当转换为字母/字(character)时,它很容易变成 10 个或更多的标记(token)。
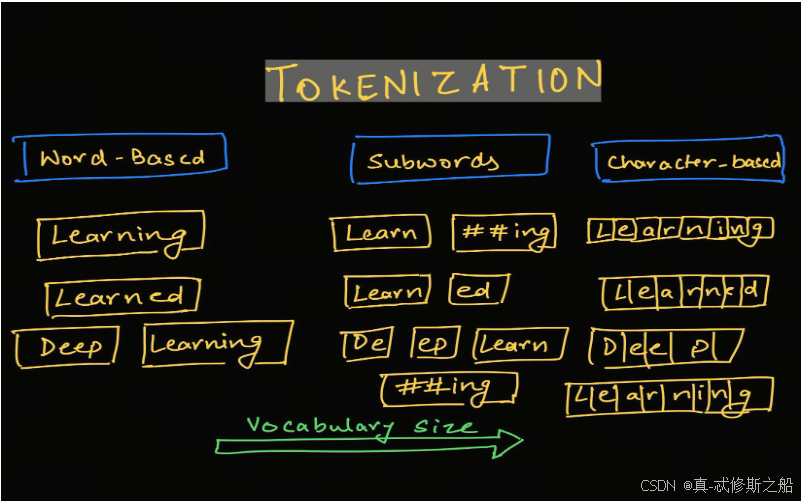
3. Sub-word level
在实际应用中,Character level和Word level都有一些缺陷。Sub-word level是一种介于Character level和Word level之间的分词方式。
Sub-word 一般翻译成子词
子词分词算法依赖于这样一个原则,即不应将常用词拆分为更小的子词,而应将稀有词分解为有意义的子词。
英文
我们来看下面的例子:
Let’s do Sub-word level tokenizer.
分词结果为:
let’s</ w>, do</ w>, Sub, -word</ w>, level</ w>, token, izer</ w>, .</ w>,
</ w>通常表示一个单词word的结尾。使用 “w” 是因为它是 “word” 的首字母,这是一种常见的命名约定。然而,具体的标记可能会根据不同的实现或者不同的分词方法有所不同。
中文
在中文中,似乎没有子词的概念,最小单元好像就是字了,那该如何使用子词分词?难道是偏旁部首吗?别着急,后面我们一起讨论。
4. 更多sub-word level的分词器
现在看来,要卷也是在子词分词器上卷,于是业界逐渐开发了一系列分词算法,包括:
- Byte-Pair Encoding(BPE)
- WordPiece
- Unigram
- SetencePiece
- BBPE
后续这个系列会继续分享这些常用的子词分词器。
参考
[1] 标记器(Tokenizer)
[2] word_vs_character_level_tokenization
[3] tokenization-in-natural-language-processing
欢迎关注我的GitHub和微信公众号,来不及解释了,快上船!
仓库上有原始的Markdown文件,完全开源,欢迎大家Star和Fork!


















 667
667

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









