







一、引言
在自然语言处理(NLP)领域,分词和嵌入是非常重要的两个步骤,它们能够将自然语言转换为机器能够理解和识别的表示(Embedding)。只有在将自然语言转化为机器能够理解和识别的表示之后,才有之后各种学习和处理。
在NLP发展过程中,分词和嵌入也在随之不断地进步和发展。这篇文章就围绕什么是分词器、主流的分词器的原理来展开讲解。
二、什么是分词器(Tokenizer)
计算机是无法直接理解自然语言的文本,我们需要进行文本预处理 ,而最重要的第一步就是分词(Tokenization)。
那什么是分词?一个典型的分词过程如下图所示:
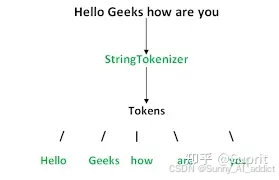
分词这个过程,是将输入的整个文本,根据分词规则,将整个文本拆成一个个小词;每一个小词都有一个自己对应的index(或者向量),从而做到将整段文本转换成一个仅包含数字的序列。
其中,执行分词的算法模型称为分词器(Tokenizer) ,划分好的一个个词称为 Token。
Tokenizer 允许使用两种方法向量化一个文本语料库:
1. 将每个token转化为一个整数序列(每个整数都是词典中标记的索引);
2; 将每个token转化为一个向量,其中每个token对应的向量可以是二进制值、词频、TF-IDF权重等。
三、主流分词器
在理解了分词的过程后,tokenzier的功能可以总结为:
1. 将文本切分成token;
2. 将切分好的文本数值化,并输入至后续模型;
为了更高效地分词以及实现后续的任务,我们希望分词器尽可能地让每个token向量蕴含更多有用的信息,然后再把这些向量输入到算法模型中。
但是在实际的分词实现过程中,往往会遇到的问题是:文本的词太多了 。如果把所有的词都放入tokenizer中,这不现实,也不高效。
因此,为了方便后续算法模型训练,我们会选取出频率 (也可能是其它的权重)最高的若干个词组成一个词表(Vocabulary),从而根据这个词表再来对文本进行分词。
根据这个原则,有很多的分词方法衍生出来,帮助NLP模型更高效地理解、处理文本。这篇文章就古典分词法、子词分词法(Subword Tokenization)、BPE 和BBPE、WordPiece、Unigram这些分词法来进行详细介绍。
3.1 古典分词法
古典分词法,也是最基础的分词法,包括基于word和基于character的分词方法。
3.1.1 基于词的(word-based)分词法
基于词的(word-based) tokenizer,通常很容易设置和使用,只需几条规则(例如,基于空格分词,基于标点符号分词),并且通常会产生不错的结果。
一个典型的基于词的分词过程如下所示:

基于词的古典分词法,优点缺点都很鲜明:
优点:
- 确实很容易理解,也易于操作;
缺点:
-
这种分词法会得到非常大的“词汇表”,其中词汇表由语料库中拥有的独立标记的总数定义(这个数量是不可详尽的)。
- 对于未在词表中出现的词(Out Of Vocabulary, OOV ),模型将无法处理(未知符号标记为
[UNK])。 - 词表中的低频词在模型训无法得到训练(因为词表大小有限,太大的话会影响效率)。
- 很多语言难以用空格进行分词,例如英语单词的多种形态,"look"衍生出的"looks", "looking", "looked",其实都是一个意思,但是在词表中却被当作不同的词处理,模型也无法通过"old", "older","oldest"之间的关系学到另外的形容词之间的关系。这一方面增加了训练冗余,另一方面也造成了大词汇量问题。
3.1.2 基于字符的(Character-based)分词法
基于字符的标记器(tokenizer)将文本拆分为字符,而不是单词。
一个典型的基于字符的分词过程如下所示:

这有两个主要好处:
- 词汇量要小得多。
- 词汇外(未知)标记(token)要少得多,因为每个单词都可以从字符构建。
这种分词方法虽然能解决 OOV 问题,也避免了大词汇量问题,但缺点也十分明显:
- 粒度太细(一个词会被分成很多个字符),每个token的信息密度低。
- 训练花费的成本太高;解码效率很低。
- 在某些语言中,由于现在表示是基于字符而不是单词。每个字符本身并没有多大意义。
3.2 基于子词的分词方法(Subword Tokenization)
在分析完基于词和基于字符的古典分词法的优缺点之后,我们自然希望通过某种方式结合两种分词法分优点,并尽可能地克制缺点,但问题是,到底怎么做才能实现强强联合呢?
我们都知道,随着 BERT 算法的横空出世,NLP 中的很多领域都被颠覆性的改变了,BERT 也成为了一个非常主流的 NLP 算法。由于 BERT 的特性,要求分词方法也必须作出改变。从此,基于子词的分词方法(Subword Tokenization)诞生了 ,该算法现在已经成为一种标配。
基于子词的分词方法(Subword Tokenization) ,简称为 Subword 算法,意思就是把词切成更小的一块一块的子词,这些子词本身也具有一定的语义:
-
高频词依旧切分成完整的整词
-
低频词被切分成有意义的子词,例如 dogs => [dog, ##s]
这种方法的目的是通过一个有限的词表 来解决所有单词的分词问题,同时尽可能将结果中词汇表的数目降到最低。例如,可以用更小的sub-word组成更大的词,例如:
“unfortunately” = “un ” + “for ” + “tun ” + “ate ” + “ly ”。
可以看到,有点类似英语中的词根词缀拼词法,其中的这些小片段又可以用来构造其他词。可见这样做,既可以降低词表的大小,同时对相近词也能更好地处理。
这种方法在土耳其语等粘着型语言(agglutinative languages)中特别有用,可以通过将子词串在一起来形成(几乎)任意长的复杂词。
Subword 相较于传统分词方法的优点:
- 学习到词之间的关系:传统分词法不利于模型学习词缀之间的关系,例如模型无法学习到“old”, “older”, and “oldest”之间的关系。
- 平衡 OOV 问题:传统分词法无法很好的处理未知或罕见的词汇(OOV 问题),而基于字符的分词法作为 OOV 的解决方法又有粒度太细的问题;subword分词法可以通过“拼词”的方式处理很多罕见的词汇,其粒度在词与字符之间,能够较好的平衡 OOV 问题。
目前有三种主流的 Subword 算法,它们分别是:Byte Pair Encoding (BPE)、WordPiece 和 Unigram Language Model。
3.2.1 字节对编码(BPE, Byte Pair Encoding)
字节对编码(BPE)最初被开发为一种压缩文本的算法,后来在预训练 GPT 模型时被 OpenAI 用于分词。发展到现在,许多 Transformer 模型都使用它,包括 GPT、GPT-2、RoBERTa、BART 和 DeBERT;许多的开源LLM模型使用的也是BPE或者BPE的改进分词法,例如Llama系列、Mistral、Qwen等。
BPE分词算法的过程如下:
- 准备足够大的训练语料,并确定期望的词表大小;
- 在每个单词末尾添加后缀 </w> (用于标明词尾),统计每个单词出现的频率;例如,low的频率为 5,那么我们将其改写为"low </w>" : 5
注:停止符 </w> 的意义在于标明词尾。为什么需要标明词尾呢?举例来说:st不加 </w> 可以出现在词首,如star;加了</w>之后表明该子词位于词尾,如west </w>,二者意义截然不同。 - 将语料库中所有单词拆分为单个字符,用所有单个字符建立最初的词典,并统计每个字符的频率(这一步和基于字符的分词法类似);
- 在语料上统计单词内相邻单元对的频数,选取频数最高的单元对合并成新的Subword单元;
- 重复第3步直到达到第1步设定的Subword词表大小或下一个最高频数为1。
我们用一个例子来更进一步地说明BPE的大致过程:
1. 第一步,准备语料库。我们以以下这段话为例:“FloydHub is the fastest way to build, train and deploy deep learning models. Build deep learning models in the cloud. Train deep learning models.”
2. 加后缀,统计词汇频率:
| WORD | FREQUENCY | WORD | FREQUENCY |
| deep </w> | 3 | build </w> | 1 |
| learning < |
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1714
1714

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









