







这里主要介绍我使用过的两种根据文本生成语言模型的两种方法
1. 通过网站: Sphinx 上传文件,生成对应的语言模型,需要注意的是文件最好不要太大,网站容易报504错误,贴下图吧,傻瓜式的操作方式:

2. 使用SRILM 训练语言模型
SRILM基本使用方法
1、从语料库中生成n-gram计数文件:
|
1
|
ngram-count -text train.txt -order 3 -write train.txt.count
|
-text指向输入文件
-order指向生成几元的n-gram,即n
-write指向输出文件
2、从上一步生成的计数文件中训练语言模型:
|
1
|
ngram-count -read train.txt.count -order 3 -lm LM -interpolate -kndiscount
|
-read指向输入文件,为上一步的输出文件
-order与上同
-lm指向训练好的语言模型输出文件
最后两个参数为所采用的平滑方法,-interpolate为插值平滑,-kndiscount为 modified Kneser-Ney 打折法,这两个是联合使用的
3、利用上一步生成的语言模型计算测试集的困惑度:
|
1
|
ngram -ppl test.txt -order 3 -lm LM > result
|
-ppl为对测试集句子进行评分(logP(T),其中P(T)为所有句子的概率乘积)和计算测试集困惑度的参数
result为输出结果文件
其他参数同上。
如果想要每条句子单独打分,则使用以下命令:
|
1
|
ngram -ppl test.txt -order 3 -lm LM -debug 1 > result
|
安装SRILM
首先安装tcl
1、去官网下载tcl8.6.6-src.tar.gz(http://www.tcl.tk/software/tcltk/download.html)
2、解压到/home/user目录
3、cd /tcl8.6.6/unix/
4、make
5、sudo make install
安装SRILM
1、官网下载http://www.speech.sri.com/projects/srilm/download.html
2、解压到/home/user/srilm/
3、修改MakeFile文件:
|
1
2
3
4
|
# SRILM = /home/wm/srilm
SRILM = /home/wm/srilm
#MACHINE_TYPE := $(shell $(SRILM)/sbin/machine-type)
MACHINE_TYPE := i686-m64
|
4、修改srilm/common/makefile.i686-m64
找到:GAWK = /usr/bin/awk
修改为:GAWK = /usr/bin/gawk
5、srilm目录下面执行:make World
6、继续执行make test
7、添加环境变量:
|
1
|
export PATH=
"$PATH:/home/user/srilm/bin/i686-m64:/home/user/srilm/bin"
|
添加之后执行ngram-count还是找不到命令,解决方法:i686-m6目录下创建新目录TEST,创建链接,把命令链接到TEST下面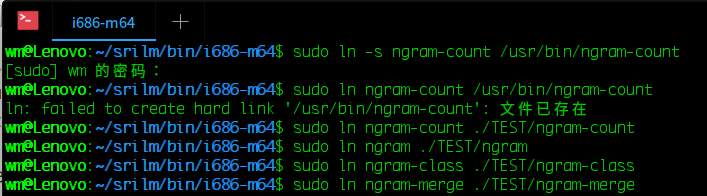
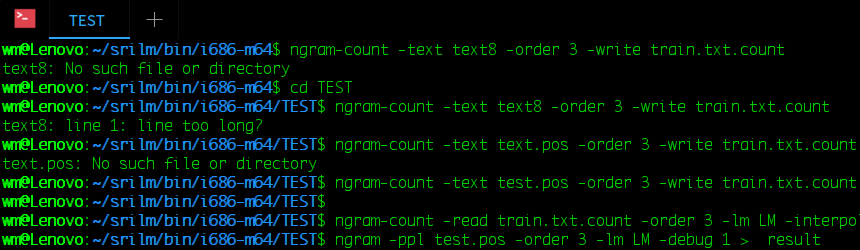
训练语言模型
1、需要训练好的语料数据
训练的语料和训练结果是相关的,假如语料是言情小说那么训练的language model也是言情风格的。接下来要对语料进行分词,英文不需要分词,处理标点符号。
2、训练
先从语料库生成n-gram计数文件
|
1
|
ngram-count -text test.pos -order 3 -write train.txt.count
|
生成的train.text.count第一列为n元词,第二列为相应的频率统计,结果如下: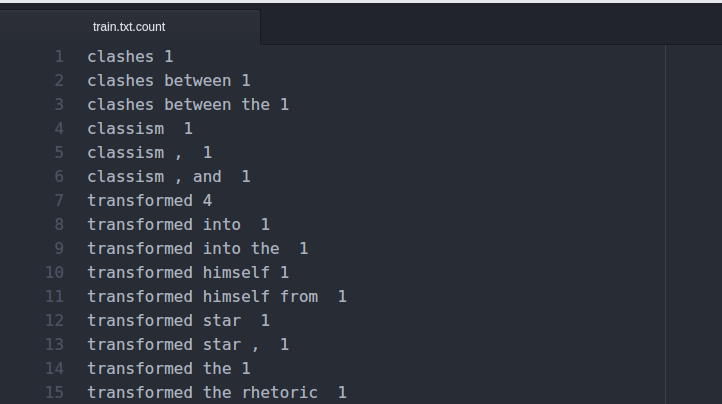
3、接着从上一步的结果计数文件中训练语言模型
|
1
|
ngram-count -read train.txt.count -order 3 -lm LM -interpolate -kndiscount
|
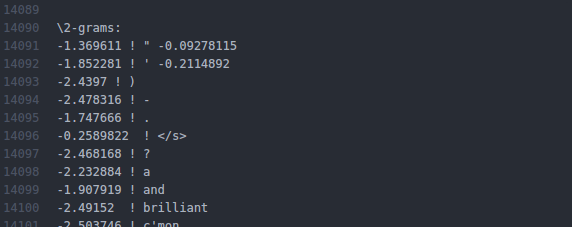
看看结果,一元词有14081个,二元词有63891个,三元词有6644个
以第一个为例:-0.3054161 ! -0.4752966
-0.3054161 :log(概率),以10为底
-0.4752966 :log(回退权重),以10为底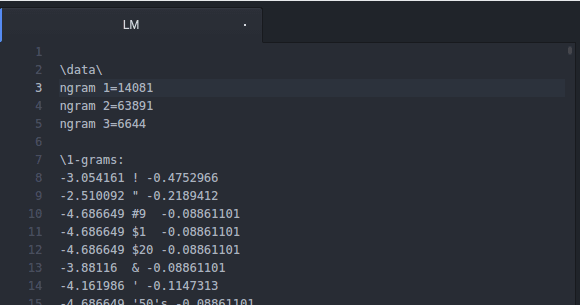
4、利用上一步生成的语言模型计算测试集的困惑度:
|
1
|
ngram -ppl test.txt -order 3 -lm LM -debug 1 > result
|
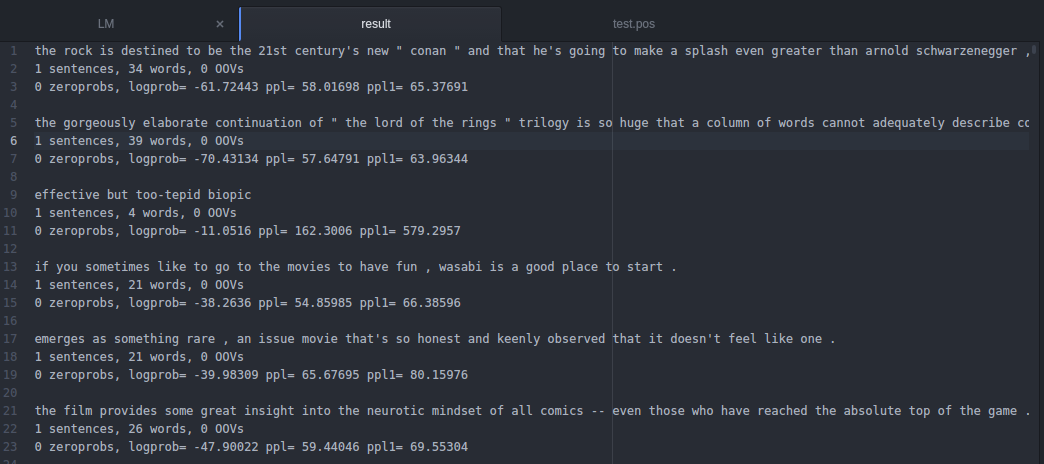
ppl为对测试集句子进行评分(logP(T),其中P(T)为所有句子的概率乘积)和计算测试集困惑度的参数,结果如下:
0 zeroprobs, logprob= -61.72443 ppl= 58.01698 ppl1= 65.37691分别表示:
无0概率;logP(T)=-105980,ppl==90.6875, ppl1= 107.805,均为困惑度。
但公式稍有不同,如下:
ppl=10^{-{logP(T)}/{Sen+Word}}; ppl1=10^{-{logP(T)}/Word}
其中Sen和Word分别代表句子和单词数
第二种方法是copy过来的, 原地址是:SRILM 训练语言模型
好的语言模型可以得到更好的解码结果!!!















 6560
6560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









