







目录
1.简介
一种主观赋权的方法,在数据集比较小,实在不好比较的时候可以用这个方法,如果有别的选择还是尽量不要用这个算法比较好。
层次分析法的特点是在对复杂的决策问题的本质、影响因素及其内在关系等进行深入分析的基础上,利用较少的定量信息使决策的思维过程数学化,从而为多目标、多准则或无结构特性的复杂决策问题提供简便的决策方法。尤其适合于对决策结果难于直接准确计量的场合。
层次分析法是将决策问题按总目标、各层子目标、评价准则直至具体的备投方案的顺序分解为不同的层次结构,然后得用求解判断矩阵特征向量的办法,求得每一层次的各元素对上一层次某元素的优先权重,最后再加权和的方法递阶归并各备择方案对总目标的最终权重,此最终权重最大者即为最优方案。这里所谓“优先权重”是一种相对的量度,它表明各备择方案在某一特点的评价准则或子目标,标下优越程度的相对量度,以及各子目标对上一层目标而言重要程度的相对量度。层次分析法比较适合于具有分层交错评价指标的目标系统,而且目标值又难于定量描述的决策问题。其用法是构造判断矩阵,求出其最大特征值。及其所对应的特征向量W,归一化后,即为某一层次指标对于上一层次某相关指标的相对重要性权值。
2.算法解析
例如某研究对象的指标集
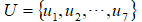
然后通过以下表格复制指标n对指标m的重要性

判断矩阵汇总指标n对指标m满足公式
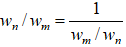
然后通过eig函数求取矩阵的特征向量

一致性检验
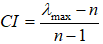
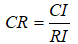
其中RI根据指标个数通过下表选择对应的RI值

如果CR<0.10时,则建立的判断矩阵的一致性认为是可接受的,否则应对其进行修正。
3.实例分析
小美要选男朋友了,现有小明、小李两个人选,到底该选谁呢?现在小美要从四个指标去选择,分别是身高、颜值、学历、性格。小美对他们各个指标的评分如下:
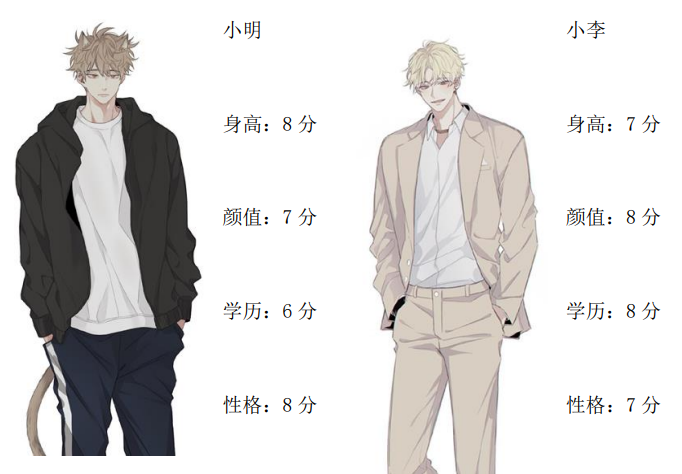
由于两者各有其优点,实在令人难以抉择,于是小美根据自己的主观判断,认为如下:
- 1.身高与颜值比较,身高稍重要
- 2.身高与学历相比,同样重要
- 3.身高和性格相比,性格稍重要
- 4.颜值和学历相比,学历介于相同重要和稍微重要之间
- 5.颜值和性格相比,性格明显重要
- 6.性格和学历相比,性格稍重
| 身高 | 颜值 | 学历 | 性格 | |
| 身高 | 1 | 3 | 1 | 1/3 |
| 颜值 | 1/3 | 1 | 1/2 | 1/5 |
| 学历 | 1 | 2 | 1 | 1/3 |
| 性格 | 3 | 5 | 3 | 1 |
由此,可得到判断矩阵

3.1 构造矩阵
p = np.mat('8 7 6 8;7 8 8 7') #每一行代表一个对象的指标评分
print(p)
#A为自己构造的输入判别矩阵
A = np.array([[1,3,1,1/3],[1/3,1,1/2,1/5],[1,2,1,1/3],[3,5,3,1]])
print(A)返回:

3.2 查看行数和列数
#查看行数和列数
[m,n] = A.shape
print(m,n)返回:
![]()
3.3 求特征向量
#求特征值和特征向量
V,D = np.linalg.eig(A)
print('特征值:')
print(V)
print('特征向量:')
print(D)返回:

3.4 找到最大特征值和最大特征向量
#最大特征值
tzz = np.max(V)
print(tzz)
#最大特征向量
k=[i for i in range(len(V)) if V[i] == np.max(V)]
tzx = -D[:,k]
print(tzx)返回:

3.5 计算权重
# #赋权重
quan=np.zeros((n,1))
for i in range(0,n):
quan[i]=tzx[i]/np.sum(tzx)
Q=quan
print(Q)返回:

3.6 一致性检验
#一致性检验
CI=(tzz-n)/(n-1)
RI=[0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49,1.52,1.54,1.56,1.58,1.59]
#判断是否通过一致性检验
CR=CI/RI[n-1]
if CR>=0.1:
print('没有通过一致性检验\n')
else:
print('通过一致性检验\n')返回:
![]()
3.7 计算评分
#显示出所有评分对象的评分值
score=p*Q
for i in range(len(score)):
print('object_score {}:'.format(i),float(score[i]))返回:
![]()
完整代码
#导入相关库
import numpy as np
import pandas as pd
p = np.mat('8 7 6 8;7 8 8 7') #每一行代表一个对象的指标评分
#A为自己构造的输入判别矩阵
A = np.array([[1,3,1,1/3],[1/3,1,1/2,1/5],[1,2,1,1/3],[3,5,3,1]])
#查看行数和列数
[m,n] = A.shape
#求特征值和特征向量
V,D = np.linalg.eig(A)
print('特征值:')
print(V)
print('特征向量:')
print(D)
#最大特征值
tzz = np.max(V)
# print(tzz)
#最大特征向量
k=[i for i in range(len(V)) if V[i] == np.max(V)]
tzx = -D[:,k]
# print(tzx)
# #赋权重
quan=np.zeros((n,1))
for i in range(0,n):
quan[i]=tzx[i]/np.sum(tzx)
Q=quan
# print(Q)
#一致性检验
CI=(tzz-n)/(n-1)
RI=[0,0,0.58,0.9,1.12,1.24,1.32,1.41,1.45,1.49,1.52,1.54,1.56,1.58,1.59]
#判断是否通过一致性检验
CR=CI/RI[n-1]
if CR>=0.1:
print('没有通过一致性检验\n')
else:
print('通过一致性检验\n')
#显示出所有评分对象的评分值
score=p*Q
for i in range(len(score)):
print('object_score {}:'.format(i),float(score[i]))














 880
880











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









