







简介
此前,大量研究工作通过将CNN与不同的时序网络模型结合来实现时空域表示,这也意味着会存在因交替时间与空间信息的学习带来的大量计算开销,大量的参数与浮点数计算也使得网络难于收敛,且易过拟合。
由此自然的想到嵌入时间信息到空间信息中进行联合学习,此文提出的时间交错网络(TIN)正式通过交错过去到未来的空间信息,或是交错空间变化下的temporal信息,来实现融合两个域内的信息。
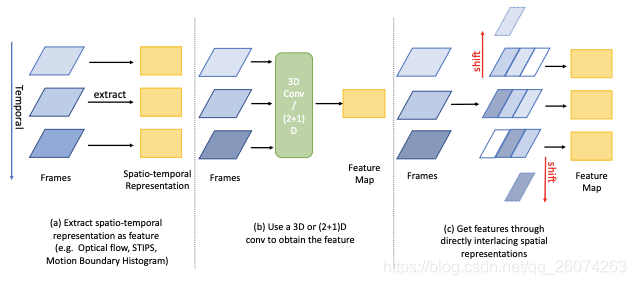
TIN理论上与标准时间卷积网络(r-TCN)是同等的,且TIN保持了输入特征图的空间尺寸,也就意味着在网络任意位置都可接入。
- 输入的channel-wise特征分为多个group,获取相邻帧的偏移于权重来混合时间信息。
- 通过shift操作并在时间维度使特征交错开,从而将学习到的偏移应用于对应的group。
- 串联特征并在时间维度上于学习的权重进行累加。
TIN模块可以捕捉到长范围的时间关系,并适用于不同采样率的数据集。group-wise的偏移也倾向于在不同时间戳上融合更多的时间信息。
Exhaustive
experiments further demonstrate the proposed TIN gains 4%
more accuracy with 6x less latency, and finally be the new
state-of-the-art method. Especially, TIN performs as the core
architecture in the 1
st solution of ICCV19 - Multi Moments
in Time challenge.
相关工作
视频理解
在静态图片取得巨大成果的CNN,在引入额外的时间维度后增大了数据复杂度和网络参数的浮点数运算以及训练难度。
可变形时序建模
DCNv1和DCNv2显著提升语义分割和物体检测的效果,Spatial Transformer Networks使用全局仿射变换来学习平移不变与旋转不变的特征表达。TSM提出基于TSN在时序维度上变化特征图。本文依此提出一种可变的变换操作,以适应特定的数据集和提取帧的特定分布。
自注意力机制
self-attention最早于机器翻译领域和其他NLP任务中提出,可以理解为一种使用所有位置上加权和来计算同一个位置上的上下文信息的方法。而后,自注意力也被运用于图像分类,视频分类,物体检测和实例分割来获取长期依赖性。
TIN
Intuition
联合学习时间和空间特征与其带来的巨大计算耗费的trade-offs一直存在,之前的工作focus on通过另外的时间维度来扩展2D CNN表示(时间卷积网络的提出)。静态的时序感受野降低计算成本的同时野丢失了多层空间信息,一个动态的时间感受野对于联合嵌入时间信息于空间信息中是至关重要的。
形变位移模块
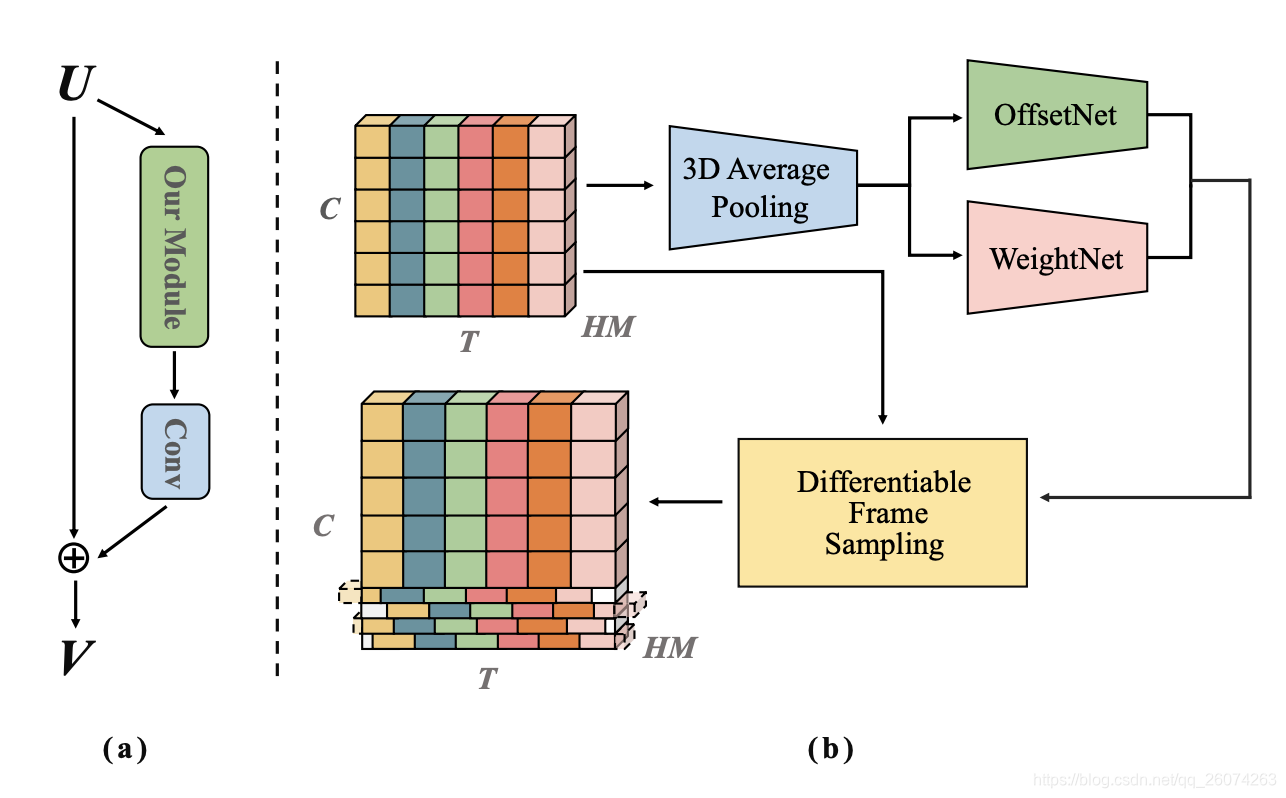
OffsetNet
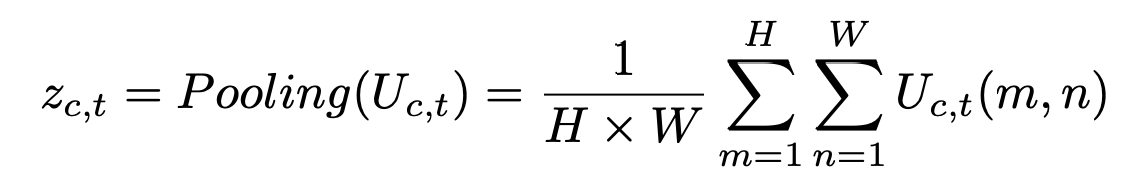
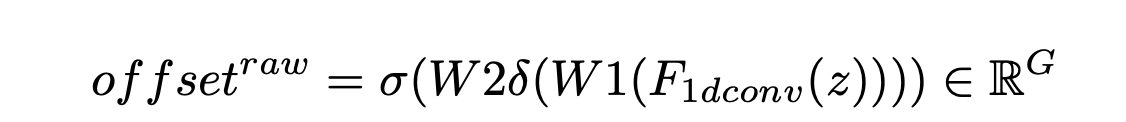
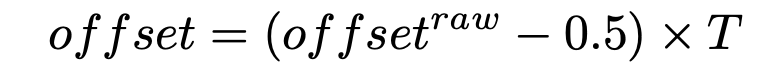
WeightNet
用于计算Eg,主要分为两部分:
- 卷积层(1D卷积层的kernel size为3,kernel数量等于group数量)
- sigmoid and rescale module(输出rescale到(0,2))
初始卷积层
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 397
397











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









