






目录
步骤 2:设置 OLLAMA_MODELS 环境变量 (更改模型存储位置)
步骤 3:重启 Ollama 或 PowerShell 使环境变量生效
Ollama 是一个开源框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。 它旨在简化大型语言模型的部署过程,提供轻量级与可扩展的架构,使得研究人员、开发人员和爱好者能够更加方便地在本地环境中运行和定制这些模型。
一、Ollama 的核心功能
-
本地模型管理:
- 支持从官方模型库或自定义模型库拉取预训练模型,并在本地保存和加载。
- 支持多种流行的模型格式,如 ONNX、PyTorch、TensorFlow 等。
-
高效推理:
- 通过 GPU/CPU 的加速,提供高效的模型推理,适合本地化应用或需要控制数据隐私的场景。
-
多种接口访问:
- 支持命令行(CLI)、HTTP 接口访问推理服务。
- 提供与 OpenAI 兼容的 API 接口,方便用户集成到现有的应用程序或系统中。
-
环境变量配置:
- 通过灵活的环境变量,用户可以自定义推理设备(GPU/CPU)、缓存路径、并发数、日志级别等。
-
预构建模型库:
- 提供了一系列预先训练好的大型语言模型,用户可以直接使用这些模型进行文本生成、翻译、问答等任务。
二、Ollama 的优势
-
轻量级与易用性:
- Ollama 保持了较小的资源占用,同时简化了部署流程,使得非专业用户也能方便地管理和运行大型语言模型。
-
可扩展性:
- 允许用户根据需要调整配置以适应不同规模的项目和硬件条件。
-
跨平台支持:
- 提供针对 macOS、Windows、Linux 以及 Docker 的安装指南,确保用户能在多种操作系统环境下顺利部署和使用 Ollama。
-
丰富的功能和教程资源:
- Ollama 提供了丰富的功能和灵活的扩展性,用户可以根据自己的需求对框架进行定制和扩展。
- 社区中拥有活跃的开发者支持和丰富的教程资源,方便用户快速上手并使用 Ollama。
三、Ollama 的应用场景
-
文本生成:
- 生成高质量的文章、故事、对话等文本内容,为内容创作者提供强大的辅助工具。
-
翻译:
- 实现高效准确的机器翻译,帮助用户跨越语言障碍。
-
问答系统:
- 根据用户的问题提供智能回答,提升用户体验。
-
代码生成:
- 通过训练好的大型语言模型,生成高质量的代码片段,甚至能够完成整个项目的开发。
四、支持的模型
Ollama 支持的模型库列表 library。
下面是一些受欢迎的模型:
| Model | Tag | Parameters | Size | Download |
|---|---|---|---|---|
| DeepSeek-R1 | - | 7B | 4.7GB | ollama run deepseek-r1 |
| DeepSeek-R1 | - | 671B | 404GB | ollama run deepseek-r1:671b |
| Llama 3.3 | - | 70B | 43GB | ollama run llama3.3 |
| Llama 3.2 | - | 3B | 2.0GB | ollama run llama3.2 |
| Llama 3.2 | - | 1B | 1.3GB | ollama run llama3.2:1b |
| Llama 3.2 Vision | Vision | 11B | 7.9GB | ollama run llama3.2-vision |
| Llama 3.2 Vision | Vision | 90B | 55GB | ollama run llama3.2-vision:90b |
| Llama 3.1 | - | 8B | 4.7GB | ollama run llama3.1 |
| Llama 3.1 | - | 405B | 231GB | ollama run llama3.1:405b |
| Gemma 2 | - | 2B | 1.6GB | ollama run gemma2:2b |
| Gemma 2 | - | 9B | 5.5GB | ollama run gemma2 |
| Gemma 2 | - | 27B | 16GB | ollama run gemma2:27b |
| mistral | - | 7b | 4.1GB | ollama run mistral:7b |
| qwen | - | 110b | 63GB | ollama run qwen:110b |
| Phi 4 | - | 14B | 9.1GB | ollama run phi4 |
| codellama | Code | 70b | 39GB | ollama run codellama:70b |
| qwen2 | - | 72b | 41GB | ollama run qwen2:72b |
| llava | Vision | 7b | 4.7GB | ollama run llava:7b |
| nomic-embed-text | Embedding | v1.5 | 274MB | ollama pull nomic-embed-text:v1.5 |
所有支持的模型(数据统计至2024.8.2)。
| Model | Tag | Parameters | Size | Download |
|---|---|---|---|---|
| llama3.1 | - | 405b | 231GB | ollama run llama3.1:405b |
| llama3.1 | - | 70b | 40GB | ollama run llama3.1:70b |
| llama3.1 | - | 8b | 4.7GB | ollama run llama3.1:8b |
| gemma2 | - | 27b | 16GB | ollama run gemma2:27b |
| gemma2 | - | 9b | 5.4GB | ollama run gemma2:9b |
| gemma2 | - | 2b | 1.6GB | ollama run gemma2:2b |
| mistral-nemo | - | 12b | 7.1GB | ollama run mistral-nemo:12b |
| mistral-large | - | 123b | 69GB | ollama run mistral-large:123b |
| qwen2 | - | 72b | 41GB | ollama run qwen2:72b |
| qwen2 | - | 7b | 4.4GB | ollama run qwen2:7b |
| qwen2 | - | 1.5b | 935MB | ollama run qwen2:1.5b |
| qwen2 | - | 0.5b | 352MB | ollama run qwen2:0.5b |
| deepseek-coder-v2 | Code | 236b | 133GB | ollama run deepseek-coder-v2:236b |
| deepseek-coder-v2 | Code | 16b | 8.9GB | ollama run deepseek-coder-v2:16b |
| phi3 | - | 14b | 7.9GB | ollama run phi3:14b |
| phi3 | - | 3.8b | 2.2GB | ollama run phi3:3.8b |
| mistral | - | 7b | 4.1GB | ollama run mistral:7b |
| mixtral | - | 8x22b | 80GB | ollama run mixtral:8x22b |
| mixtral | - | 8x7b | 26GB | ollama run mixtral:8x7b |
| codegemma | Code | 7b | 5.0GB | ollama run codegemma:7b |
| codegemma | Code | 2b | 1.6GB | ollama run codegemma:2b |
| command-r | - | 35b | 20GB | ollama run command-r:35b |
| command-r-plus | - | 104b | 59GB | ollama run command-r-plus:104b |
| llava | Vision | 34b | 20GB | ollama run llava:34b |
| llava | Vision | 13b | 8.0GB | ollama run llava:13b |
| llava | Vision | 7b | 4.7GB | ollama run llava:7b |
| llama3 | - | 70b | 40GB | ollama run llama3:70b |
| llama3 | - | 8b | 4.7GB | ollama run llama3:8b |
| gemma | - | 7b | 5.0GB | ollama run gemma:7b |
| gemma | - | 2b | 1.7GB | ollama run gemma:2b |
| qwen | - | 110b | 63GB | ollama run qwen:110b |
| qwen | - | 72b | 41GB | ollama run qwen:72b |
| qwen | - | 32b | 18GB | ollama run qwen:32b |
| qwen | - | 14b | 8.2GB | ollama run qwen:14b |
| qwen | - | 7b | 4.5GB | ollama run qwen:7b |
| qwen | - | 4b | 2.3GB | ollama run qwen:4b |
| qwen | - | 1.8b | 1.1GB | ollama run qwen:1.8b |
| qwen | - | 0.5b | 395MB | ollama run qwen:0.5b |
| llama2 | - | 70b | 39GB | ollama run llama2:70b |
| llama2 | - | 13b | 7.4GB | ollama run llama2:13b |
| llama2 | - | 7b | 3.8GB | ollama run llama2:7b |
| codellama | Code | 70b | 39GB | ollama run codellama:70b |
| codellama | Code | 34b | 19GB | ollama run codellama:34b |
| codellama | Code | 13b | 7.4GB | ollama run codellama:13b |
| codellama | Code | 7b | 3.8GB | ollama run codellama:7b |
| dolphin-mixtral | - | 8x7b | 26GB | ollama run dolphin-mixtral:8x7b |
| dolphin-mixtral | - | 8x22b | 80GB | ollama run dolphin-mixtral:8x22b |
| nomic-embed-text | Embedding | v1.5 | 274MB | ollama pull nomic-embed-text:v1.5 |
| llama2-uncensored | - | 70b | 39GB | ollama run llama2-uncensored:70b |
| llama2-uncensored | - | 7b | 3.8GB | ollama run llama2-uncensored:7b |
| phi | - | 2.7b | 1.6GB | ollama run phi:2.7b |
| deepseek-coder | Code | 33b | 19GB | ollama run deepseek-coder:33b |
| deepseek-coder | Code | 6.7b | 3.8GB | ollama run deepseek-coder:6.7b |
| deepseek-coder | Code | 1.3b | 776MB | ollama run deepseek-coder:1.3b |
| dolphin-mistral | - | 7b | 4.1GB | ollama run dolphin-mistral:7b |
| orca-mini | - | 70b | 39GB | ollama run orca-mini:70b |
| orca-mini | - | 13b | 7.4GB | ollama run orca-mini:13b |
| orca-mini | - | 7b | 3.8GB | ollama run orca-mini:7b |
| orca-mini | - | 3b | 2.0GB | ollama run orca-mini:3b |
| mxbai-embed-large | Embedding | 335m | 670MB | ollama pull mxbai-embed-large:335m |
| dolphin-llama3 | - | 70b | 40GB | ollama run dolphin-llama3:70b |
| dolphin-llama3 | - | 8b | 4.7GB | ollama run dolphin-llama3:8b |
| zephyr | - | 141b | 80GB | ollama run zephyr:141b |
| zephyr | - | 7b | 4.1GB | ollama run zephyr:7b |
| starcoder2 | Code | 15b | 9.1GB | ollama run starcoder2:15b |
| starcoder2 | Code | 7b | 4.0GB | ollama run starcoder2:7b |
| starcoder2 | Code | 3b | 1.7GB | ollama run starcoder2:3b |
| mistral-openorca | - | 7b | 4.1GB | ollama run mistral-openorca:7b |
| yi | - | 34b | 19GB | ollama run yi:34b |
| yi | - | 9b | 5.0GB | ollama run yi:9b |
| yi | - | 6b | 3.5GB | ollama run yi:6b |
| llama2-chinese | - | 13b | 7.4GB | ollama run llama2-chinese:13b |
| llama2-chinese | - | 7b | 3.8GB | ollama run llama2-chinese:7b |
| llava-llama3 | Vision | 8b | 5.5GB | ollama run llava-llama3:8b |
| vicuna | - | 33b | 18GB | ollama run vicuna:33b |
| vicuna | - | 13b | 7.4GB | ollama run vicuna:13b |
| vicuna | - | 7b | 3.8GB | ollama run vicuna:7b |
| nous-hermes2 | - | 34b | 19GB | ollama run nous-hermes2:34b |
| nous-hermes2 | - | 10.7b | 6.1GB | ollama run nous-hermes2:10.7b |
| tinyllama | - | 1.1b | 638MB | ollama run tinyllama:1.1b |
| wizard-vicuna-uncensored | - | 30b | 18GB | ollama run wizard-vicuna-uncensored:30b |
| wizard-vicuna-uncensored | - | 13b | 7.4GB | ollama run wizard-vicuna-uncensored:13b |
| wizard-vicuna-uncensored | - | 7b | 3.8GB | ollama run wizard-vicuna-uncensored:7b |
| codestral | Code | 22b | 13GB | ollama run codestral:22b |
| starcoder | Code | 15b | 9.0GB | ollama run starcoder:15b |
| starcoder | Code | 7b | 4.3GB | ollama run starcoder:7b |
| starcoder | Code | 3b | 1.8GB | ollama run starcoder:3b |
| starcoder | Code | 1b | 726MB | ollama run starcoder:1b |
| wizardlm2 | - | 8x22b | 80GB | ollama run wizardlm2:8x22b |
| wizardlm2 | - | 7b | 4.1GB | ollama run wizardlm2:7b |
| openchat | - | 7b | 4.1GB | ollama run openchat:7b |
| aya | - | 35b | 20GB | ollama run aya:35b |
| aya | - | 8b | 4.8GB | ollama run aya:8b |
| tinydolphin | - | 1.1b | 637MB | ollama run tinydolphin:1.1b |
| stable-code | Code | 3b | 1.6GB | ollama run stable-code:3b |
| openhermes | - | v2.5 | 4.1GB | ollama run openhermes:v2.5 |
| wizardcoder | Code | 33b | 19GB | ollama run wizardcoder:33b |
| wizardcoder | Code | python | 3.8GB | ollama run wizardcoder:python |
| codeqwen | Code | 7b | 4.2GB | ollama run codeqwen:7b |
| wizard-math | - | 70b | 39GB | ollama run wizard-math:70b |
| wizard-math | - | 13b | 7.4GB | ollama run wizard-math:13b |
| wizard-math | - | 7b | 4.1GB | ollama run wizard-math:7b |
| granite-code | Code | 34b | 19GB | ollama run granite-code:34b |
| granite-code | Code | 20b | 12GB | ollama run granite-code:20b |
| granite-code | Code | 8b | 4.6GB | ollama run granite-code:8b |
| granite-code | Code | 3b | 2.0GB | ollama run granite-code:3b |
| stablelm2 | - | 12b | 7.0GB | ollama run stablelm2:12b |
| stablelm2 | - | 1.6b | 983MB | ollama run stablelm2:1.6b |
| neural-chat | - | 7b | 4.1GB | ollama run neural-chat:7b |
| all-minilm | Embedding | 33m | 67MB | ollama pull all-minilm:33m |
| all-minilm | Embedding | 22m | 46MB | ollama pull all-minilm:22m |
| phind-codellama | Code | 34b | 19GB | ollama run phind-codellama:34b |
| dolphincoder | Code | 15b | 9.1GB | ollama run dolphincoder:15b |
| dolphincoder | Code | 7b | 4.2GB | ollama run dolphincoder:7b |
| nous-hermes | - | 13b | 7.4GB | ollama run nous-hermes:13b |
| nous-hermes | - | 7b | 3.8GB | ollama run nous-hermes:7b |
| sqlcoder | Code | 15b | 9.0GB | ollama run sqlcoder:15b |
| sqlcoder | Code | 7b | 4.1GB | ollama run sqlcoder:7b |
| llama3-gradient | - | 70b | 40GB | ollama run llama3-gradient:70b |
| llama3-gradient | - | 8b | 4.7GB | ollama run llama3-gradient:8b |
| starling-lm | - | 7b | 4.1GB | ollama run starling-lm:7b |
| xwinlm | - | 13b | 7.4GB | ollama run xwinlm:13b |
| xwinlm | - | 7b | 3.8GB | ollama run xwinlm:7b |
| yarn-llama2 | - | 13b | 7.4GB | ollama run yarn-llama2:13b |
| yarn-llama2 | - | 7b | 3.8GB | ollama run yarn-llama2:7b |
| deepseek-llm | - | 67b | 38GB | ollama run deepseek-llm:67b |
| deepseek-llm | - | 7b | 4.0GB | ollama run deepseek-llm:7b |
| llama3-chatqa | - | 70b | 40GB | ollama run llama3-chatqa:70b |
| llama3-chatqa | - | 8b | 4.7GB | ollama run llama3-chatqa:8b |
| orca2 | - | 13b | 7.4GB | ollama run orca2:13b |
| orca2 | - | 7b | 3.8GB | ollama run orca2:7b |
| solar | - | 10.7b | 6.1GB | ollama run solar:10.7b |
| samantha-mistral | - | 7b | 4.1GB | ollama run samantha-mistral:7b |
| dolphin-phi | - | 2.7b | 1.6GB | ollama run dolphin-phi:2.7b |
| stable-beluga | - | 70b | 39GB | ollama run stable-beluga:70b |
| stable-beluga | - | 13b | 7.4GB | ollama run stable-beluga:13b |
| stable-beluga | - | 7b | 3.8GB | ollama run stable-beluga:7b |
| moondream | Vision | 1.8b | 1.7GB | ollama run moondream:1.8b |
| snowflake-arctic-embed | Embedding | 335m | 669MB | ollama pull snowflake-arctic-embed:335m |
| snowflake-arctic-embed | Embedding | 137m | 274MB | ollama pull snowflake-arctic-embed:137m |
| snowflake-arctic-embed | Embedding | 110m | 219MB | ollama pull snowflake-arctic-embed:110m |
| snowflake-arctic-embed | Embedding | 33m | 67MB | ollama pull snowflake-arctic-embed:33m |
| snowflake-arctic-embed | Embedding | 22m | 46MB | ollama pull snowflake-arctic-embed:22m |
| bakllava | Vision | 7b | 4.7GB | ollama run bakllava:7b |
| wizardlm-uncensored | - | 13b | 7.4GB | ollama run wizardlm-uncensored:13b |
| deepseek-v2 | - | 236b | 133GB | ollama run deepseek-v2:236b |
| deepseek-v2 | - | 16b | 8.9GB | ollama run deepseek-v2:16b |
| medllama2 | - | 7b | 3.8GB | ollama run medllama2:7b |
| yarn-mistral | - | 7b | 4.1GB | ollama run yarn-mistral:7b |
| llama-pro | - | instruct | 4.7GB | ollama run llama-pro:instruct |
| nous-hermes2-mixtral | - | 8x7b | 26GB | ollama run nous-hermes2-mixtral:8x7b |
| meditron | - | 70b | 39GB | ollama run meditron:70b |
| meditron | - | 7b | 3.8GB | ollama run meditron:7b |
| nexusraven | - | 13b | 7.4GB | ollama run nexusraven:13b |
| codeup | Code | 13b | 7.4GB | ollama run codeup:13b |
| llava-phi3 | Vision | 3.8b | 2.9GB | ollama run llava-phi3:3.8b |
| everythinglm | - | 13b | 7.4GB | ollama run everythinglm:13b |
| glm4 | - | 9b | 5.5GB | ollama run glm4:9b |
| codegeex4 | Code | 9b | 5.5GB | ollama run codegeex4:9b |
| magicoder | Code | 7b | 3.8GB | ollama run magicoder:7b |
| stablelm-zephyr | - | 3b | 1.6GB | ollama run stablelm-zephyr:3b |
| codebooga | Code | 34b | 19GB | ollama run codebooga:34b |
| mistrallite | - | 7b | 4.1GB | ollama run mistrallite:7b |
| wizard-vicuna | - | 13b | 7.4GB | ollama run wizard-vicuna:13b |
| duckdb-nsql | Code | 7b | 3.8GB | ollama run duckdb-nsql:7b |
| megadolphin | - | 120b | 68GB | ollama run megadolphin:120b |
| goliath | - | 120b-q4_0 | 66GB | ollama run goliath:120b-q4_0 |
| notux | - | 8x7b | 26GB | ollama run notux:8x7b |
| falcon2 | - | 11b | 6.4GB | ollama run falcon2:11b |
| open-orca-platypus2 | - | 13b | 7.4GB | ollama run open-orca-platypus2:13b |
| notus | - | 7b | 4.1GB | ollama run notus:7b |
| dbrx | - | 132b | 74GB | ollama run dbrx:132b |
| internlm2 | - | 7b | 4.5GB | ollama run internlm2:7b |
| alfred | - | 40b | 24GB | ollama run alfred:40b |
| llama3-groq-tool-use | - | 70b | 40GB | ollama run llama3-groq-tool-use:70b |
| llama3-groq-tool-use | - | 8b | 4.7GB | ollama run llama3-groq-tool-use:8b |
| mathstral | - | 7b | 4.1GB | ollama run mathstral:7b |
| firefunction-v2 | - | 70b | 40GB | ollama run firefunction-v2:70b |
| nuextract | - | 3.8b | 2.2GB | ollama run nuextract:3.8b |
最新支持模型请参考:Ollama
五、Ollama常见命令
终端输入 Ollama,输出如下:
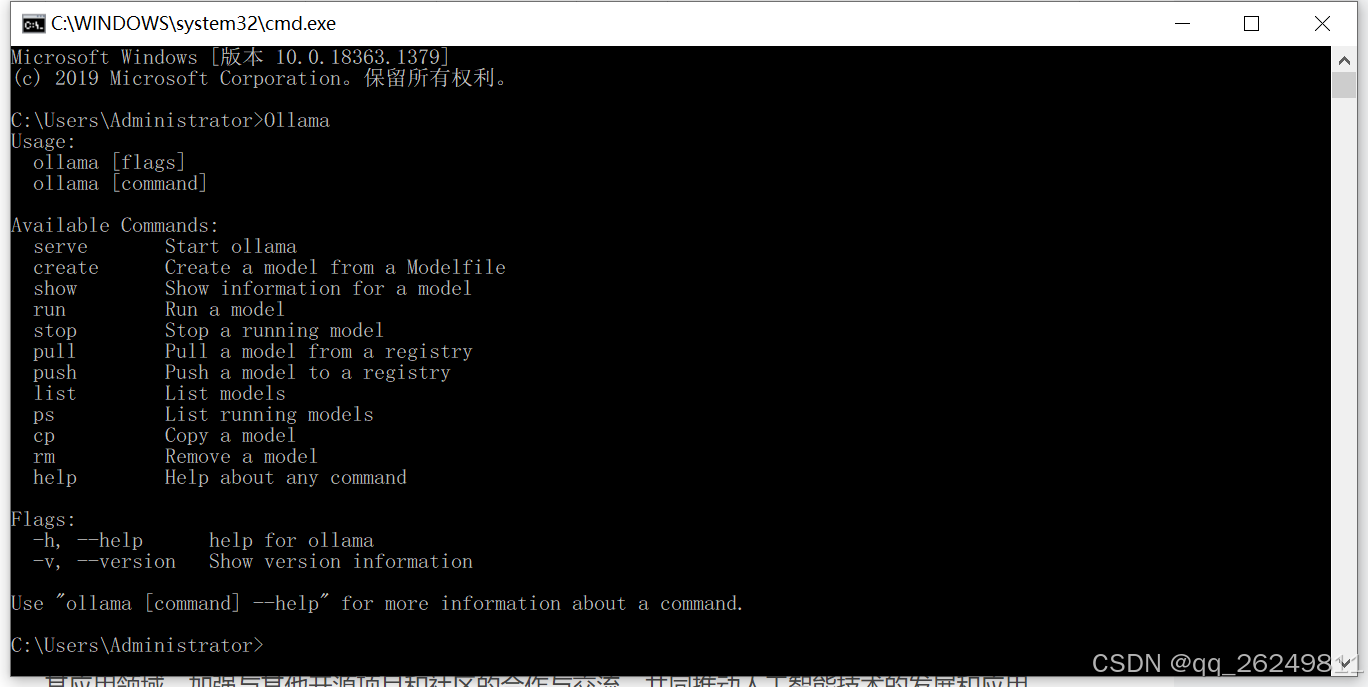
| 命令 | 描述 |
|---|---|
ollama serve | 启动 Ollama |
ollama create | 从 Modelfile 创建模型 |
ollama show | 显示模型信息 |
ollama run | 运行模型 |
ollama stop | 停止正在运行的模型 |
ollama pull | 从注册表中拉取模型 |
ollama push | 将模型推送到注册表 |
ollama list | 列出所有模型 |
ollama ps | 列出正在运行的模型 |
ollama cp | 复制模型 |
ollama rm | 删除模型 |
ollama help | 显示任意命令的帮助信息 |
| 标志 | 描述 |
|---|---|
-h, --help | 显示 Ollama 的帮助信息 |
-v, --version | 显示版本信息 |
六、Ollama 的未来展望
随着人工智能技术的不断进步和大型语言模型应用的日益广泛,Ollama 的未来发展前景广阔。它将不断优化其性能和功能,提供更加高效、稳定、易用的框架服务。同时,Ollama 还将积极拓展其应用领域,加强与其他开源项目和社区的合作与交流,共同推动人工智能技术的发展和应用。
概括而言,Ollama 是一个功能强大、易于使用的开源框架,为大型语言模型的本地部署和运行提供了便捷解决方案。
七、访问主页
-
访问官网主页
Ollama 下载:Download Ollama on macOS
Ollama 官方主页:https://ollama.com
Ollama 官方 GitHub 源代码仓库:https://github.com/ollama/ollama/
-
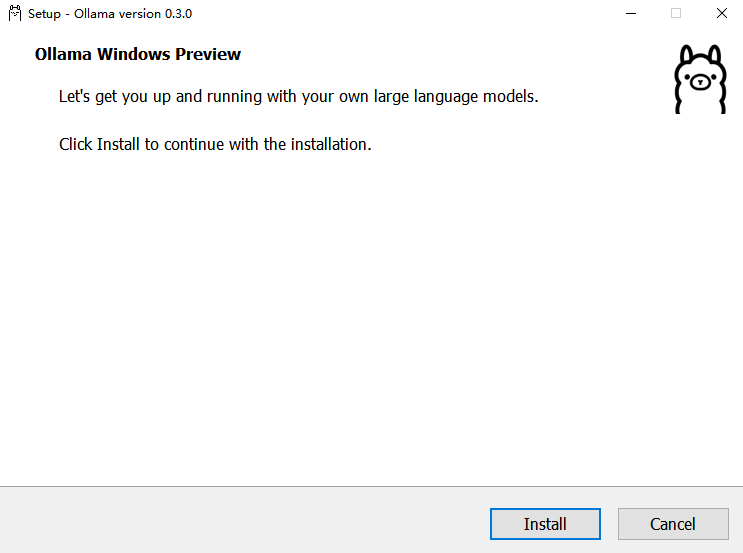
等待浏览器下载文件 OllamaSetup.exe,完成后双击该文件,出现如下弹窗,点击
Install等待下载完成即可。
-
安装完成后,可以看到 Ollama 已经默认运行了。可以通过底部的导航栏找到 Ollama 标志,并右键后点击
Quit Ollama退出Ollama或者查看logs。
八、环境变量配置
Ollama可以像其他软件一样在电脑上完成一键安装,不同的是,建议按照实际需求配置下系统环境变量参数。以下是 Ollama 的环境变量配置说明。
| 参数 | 标识与配置 |
|---|---|
| OLLAMA_MODELS | 表示模型文件的存放目录,默认目录为当前用户目录即 C:\Users%username%.ollama\modelsWindows 系统 建议不要放在C盘,可放在其他盘(如 E:\ollama\models) |
| OLLAMA_HOST | 表示ollama 服务监听的网络地址,默认为127.0.0.1 如果想要允许其他电脑访问 Ollama(如局域网中的其他电脑),建议设置成 0.0.0.0 |
| OLLAMA_PORT | 表示ollama 服务监听的默认端口,默认为11434 如果端口有冲突,可以修改设置成其他端口(如8080等) |
| OLLAMA_ORIGINS | 表示HTTP 客户端的请求来源,使用半角逗号分隔列表 如果本地使用不受限制,可以设置成星号 * |
| OLLAMA_KEEP_ALIVE | 表示大模型加载到内存中后的存活时间,默认为5m即 5 分钟 (如纯数字300 代表 300 秒,0 代表处理请求响应后立即卸载模型,任何负数则表示一直存活) 建议设置成 24h ,即模型在内存中保持 24 小时,提高访问速度 |
| OLLAMA_NUM_PARALLEL | 表示请求处理的并发数量,默认为1 (即单并发串行处理请求) 建议按照实际需求进行调整 |
| OLLAMA_MAX_QUEUE | 表示请求队列长度,默认值为512 建议按照实际需求进行调整,超过队列长度的请求会被抛弃 |
| OLLAMA_DEBUG | 表示输出 Debug 日志,应用研发阶段可以设置成1 (即输出详细日志信息,便于排查问题) |
| OLLAMA_MAX_LOADED_MODELS | 表示最多同时加载到内存中模型的数量,默认为1 (即只能有 1 个模型在内存中) |
九、配置 OLLAMA_MODELS 来更改模型存储位置。
步骤 1:找到系统环境变量的设置入口。
方法 1:开始->设置->关于->高级系统设置->系统属性->环境变量。
方法 2:此电脑->右键->属性->高级系统设置->环境变量。
方法 3:开始->控制面板->系统和安全->系统->高级系统设置->系统属性->环境变量。
方法 4:Win+R 打开运行窗口,输入 sysdm.cpl,回车打开系统属性,选择高级选项卡,点击环境变量。
步骤 2:设置 OLLAMA_MODELS 环境变量 (更改模型存储位置)
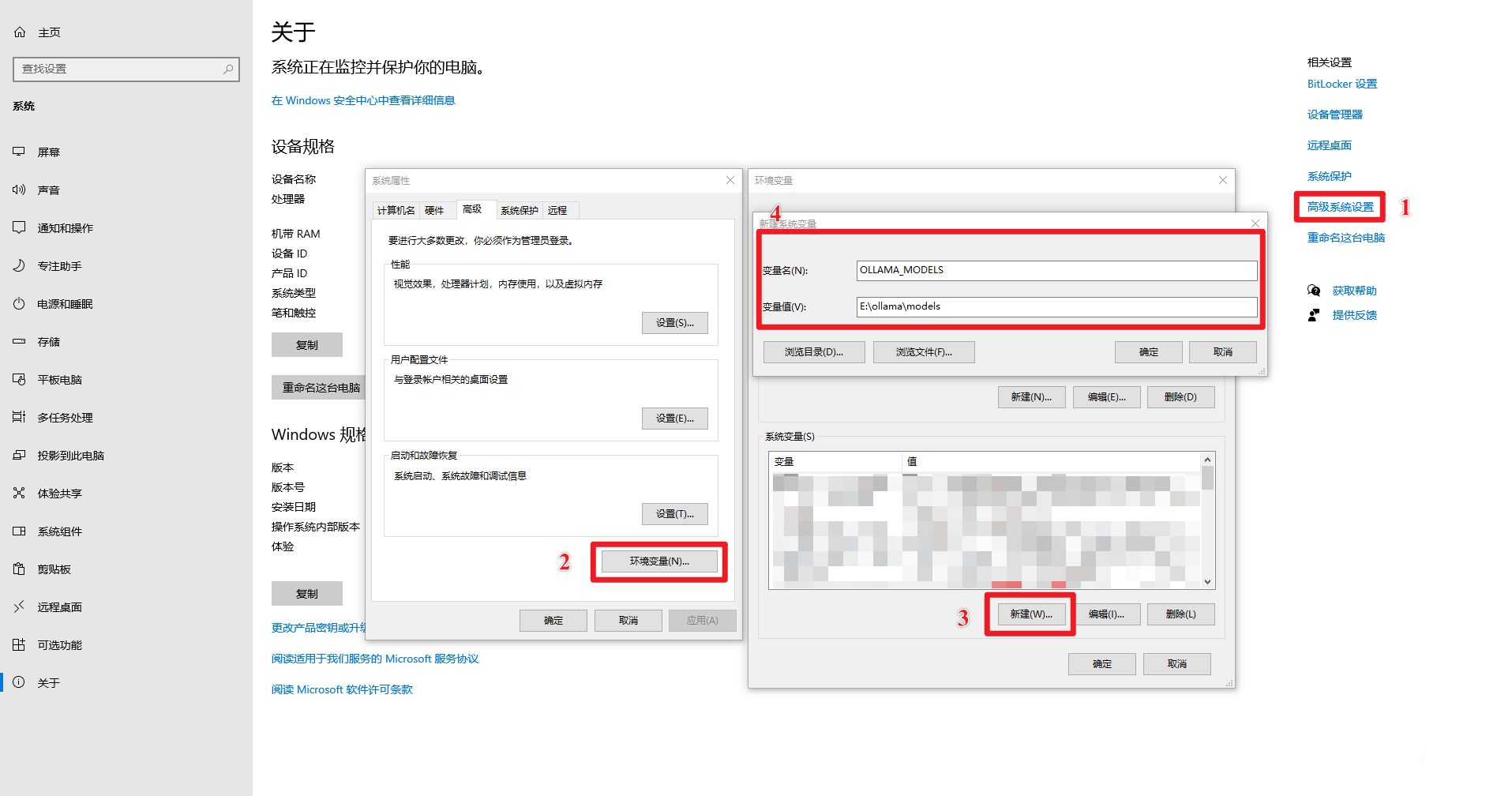
步骤 3:重启 Ollama 或 PowerShell 使环境变量生效
环境变量设置完成后,你需要 重启 Ollama 服务 或者 重新启动你的 命令提示符 (CMD) 或 PowerShell 窗口,才能让新的环境变量生效。
- 重启 Ollama 服务: 如果你运行了
ollama serve,先Ctrl + C停止,再重新运行ollama serve。 - 重启命令提示符/PowerShell: 关闭所有已打开的窗口,重新打开新的窗口。
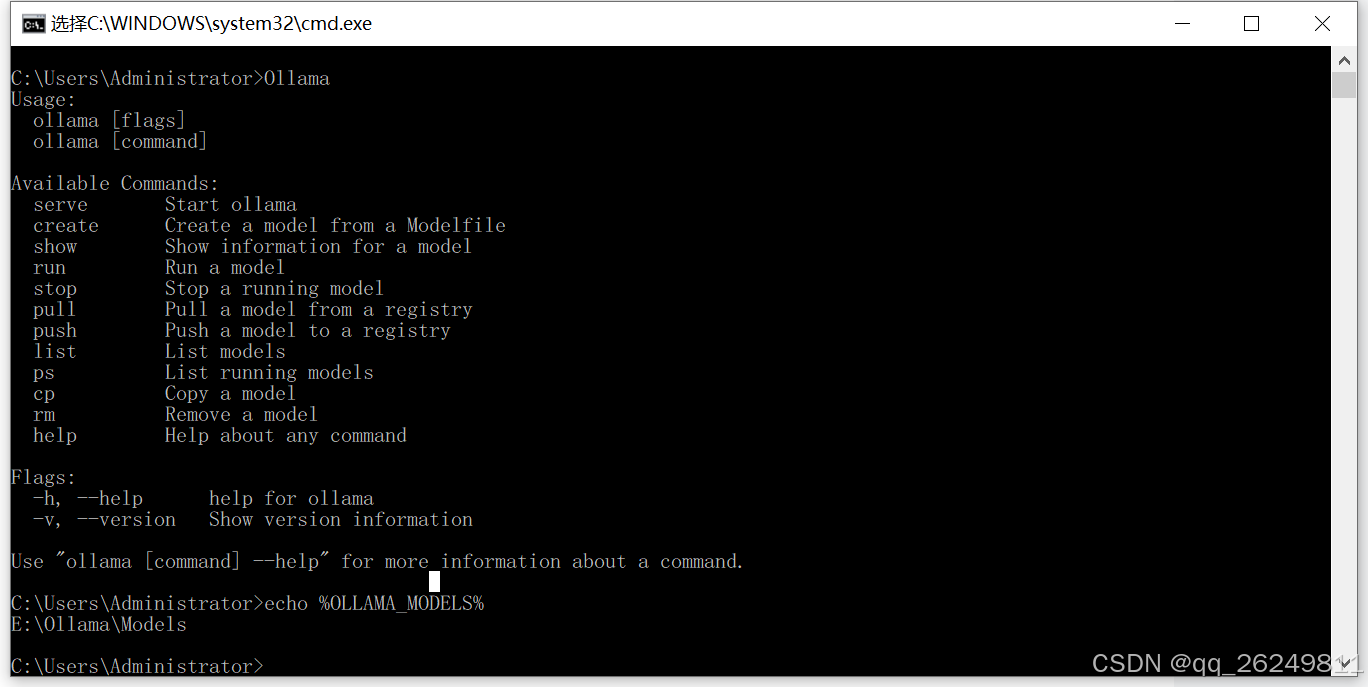
步骤 4:验证环境变量是否生效
-
重新打开 命令提示符 (CMD) 或者 PowerShell。
-
验证
OLLAMA_MODELS: 输入以下命令并回车:
echo %OLLAMA_MODELS%
十、运行ollma
- 命令行语句启动
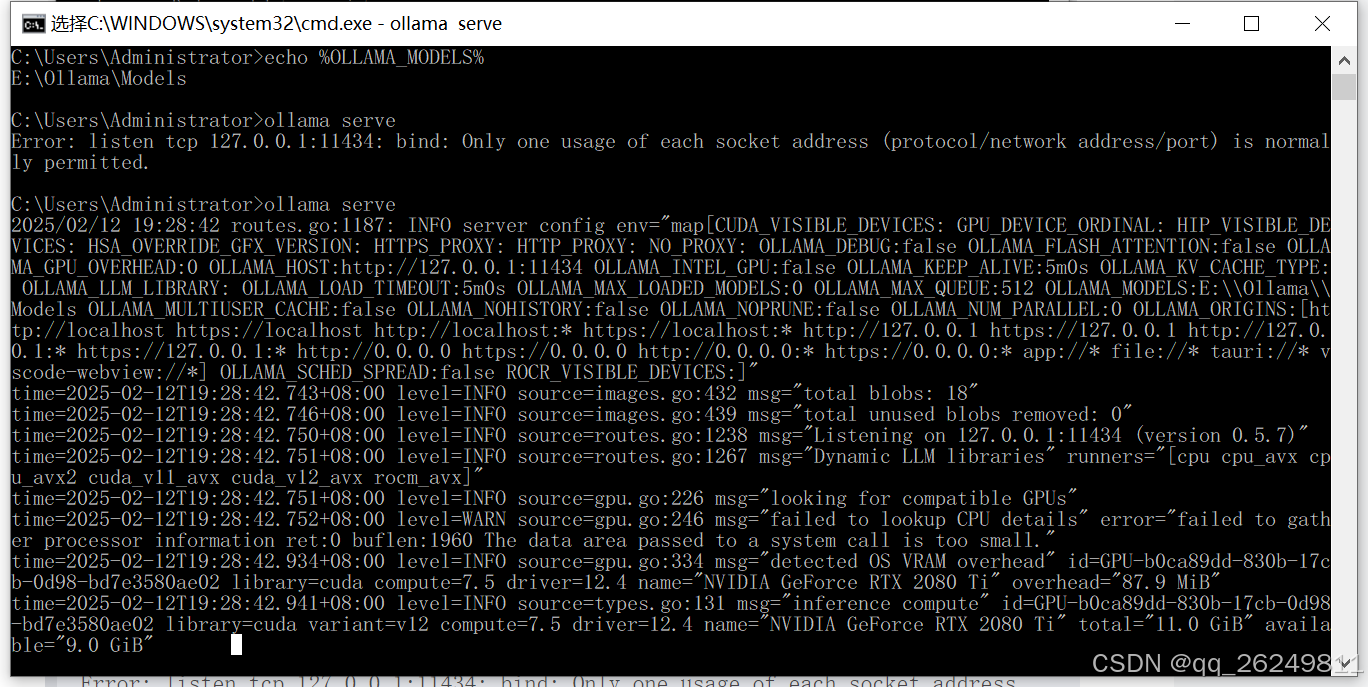
启动 Ollama 时会报错如下,因为 Windows 系统安装 Ollama 时会默认开机启动,Ollama 服务默认是 http://127.0.0.1:11434
Error: listen tcp 127.0.0.1:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
- 解决方法:
-
快捷键
Win+X打开任务管理器,点击启动,禁用 Ollama,并在进程中结束 Ollama 的任务。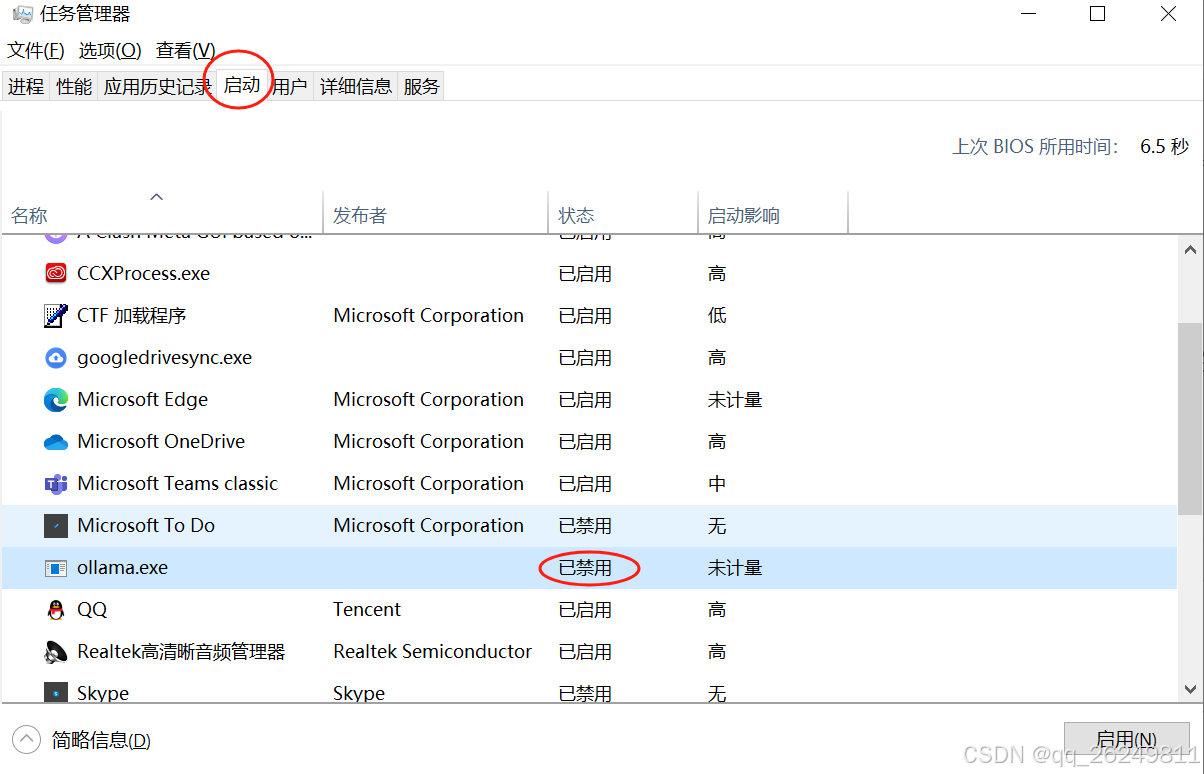
再次使用
ollama serve打开 Ollama。
- 验证成功启动:
- 快捷键
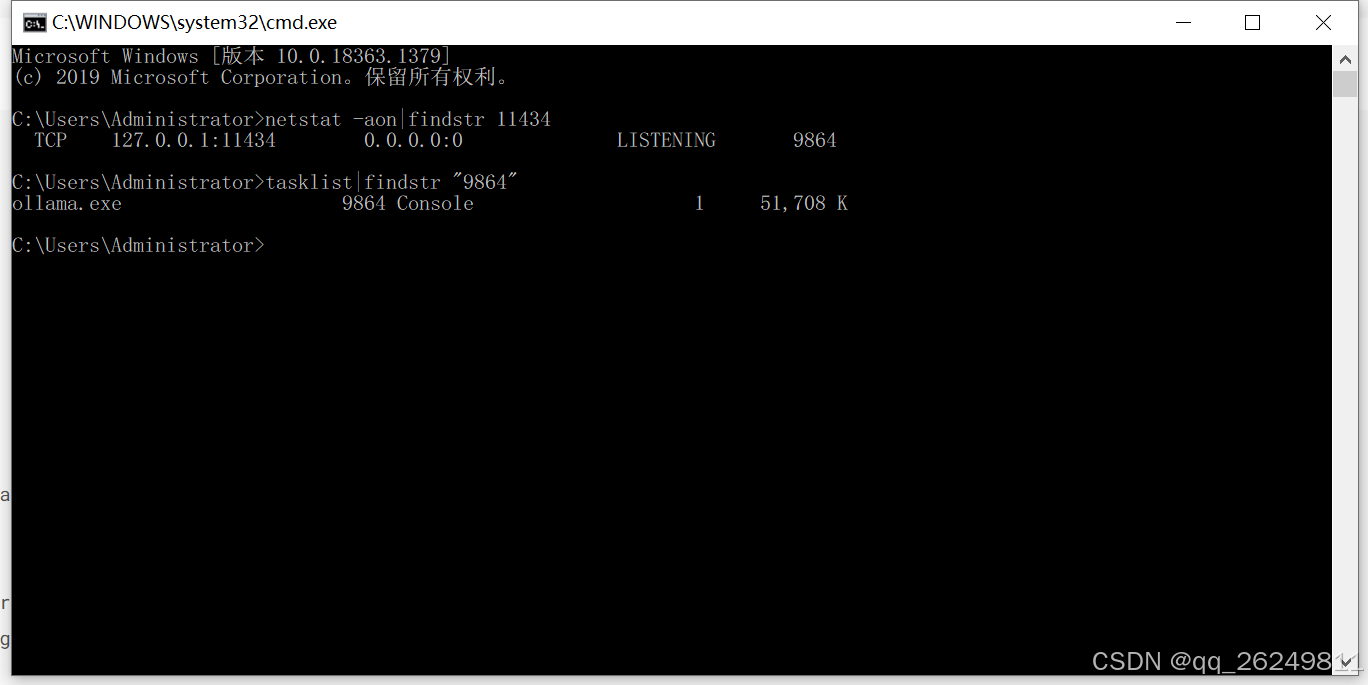
Win+R,输入cmd,打开命令行终端。 - 输入
netstat -aon|findstr 11434查看占用端口11434的进程。 - 查看该进程运行的情况,发现 Ollama 已经启动。
- tasklist|findstr "9864"
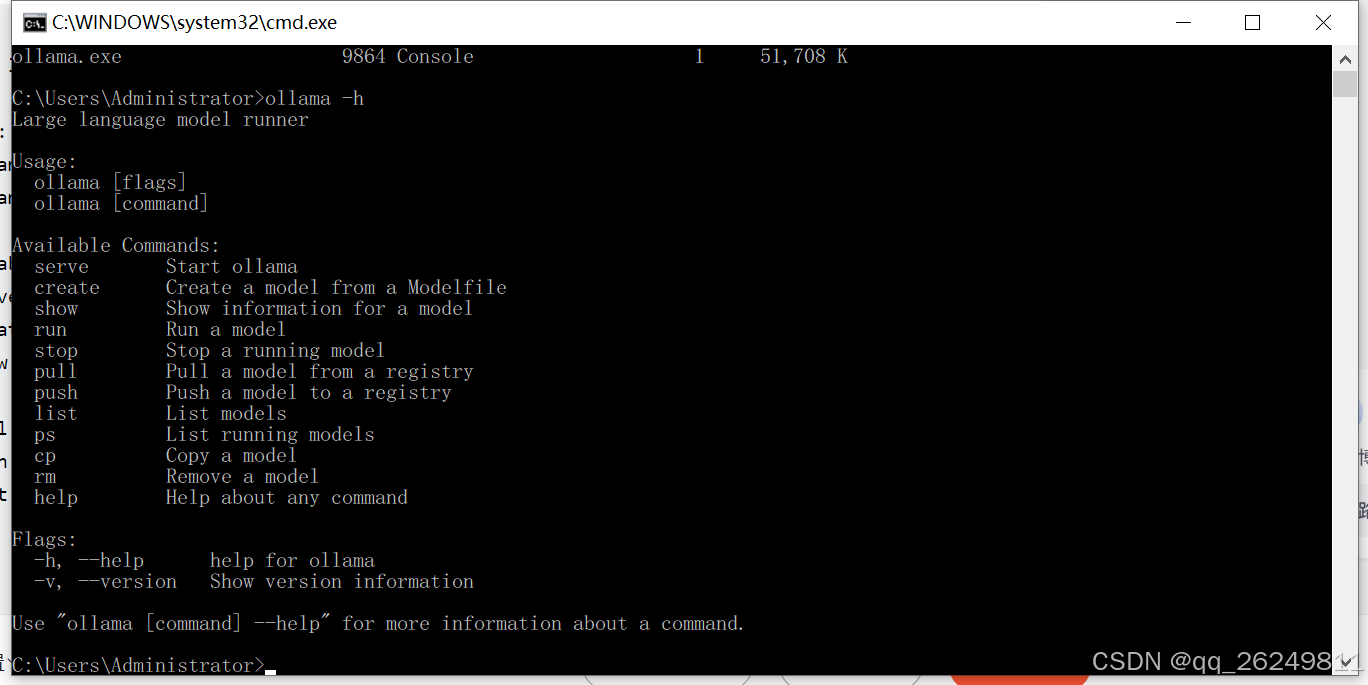
- 终端输入:
ollama -h
十一、Ollama 的使用示例
-
拉取模型:
- 使用
ollama pull <model-name>命令从官方模型库拉取预训练模型。
- 使用
-
运行模型:
- 使用
ollama run <model-name> "<prompt>"命令运行模型,并输入提示(prompt)进行推理。
- 使用
-
访问推理服务:
- 用户可以通过命令行、HTTP 接口或 OpenAI 客户端访问 Ollama 的推理服务。

















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









