







先看看不同的显卡上工作组的数量情况。
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 0, data);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 1, data + 1);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_COUNT, 2, data + 2);
glGetIntegerv(GL_MAX_COMPUTE_WORK_GROUP_INVOCATIONS,data + 3);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 0, data + 4);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 1, data + 5);
glGetIntegeri_v(GL_MAX_COMPUTE_WORK_GROUP_SIZE, 2, data + 6);
cout << "GL_MAX_COMPUTE_WORK_GROUP_COUNT:" << data[0] << " " << data[1] << " " << data[2] << endl;
cout << "GL_MAX_COMPUTE_WORK_GROUP_INVOCATIONS:" << data[3] << endl;
cout << "GL_MAX_COMPUTE_WORK_GROUP_SIZE:" << data[4] << " " << data[5] << " " << data[6] << endl;
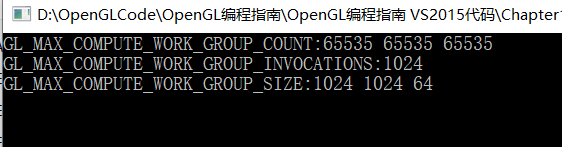
集成显卡:
高性能INVIDIA处理器:
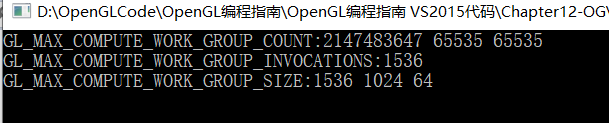
很明显独显可设置的工作组数量要比集成显卡多一些。先看一下相同的维度下集成显卡和独显的运行时间(毫秒)。
glDispatchCompute(8000, 1, 1);
//着色器设置
layout (local_size_x = 1024,local_size_y = 1) in;
集成:

独显:

很明显,独显的运行速度要比集成显卡快很多。
再在集成显卡下,修改一下工作组维度看下。
glDispatchCompute(20, 20, 20);
//着色器设置
layout (local_size_x = 256,local_size_y = 2,local_size_z = 2) in;

本地工作组的积都是1024的时候,好像并没有什么的改善。。。。。。。也许只要设置成x单维的,用gl_GlobalInvocationID.x做为索引就行。。。
再试下把本地工作组的值减小:
glDispatchCompute(64000, 1, 1);
layout (local_size_x = 128,local_size_y = 1) in;

再对比一下感觉31和32占的比例明显增多。个人认为还是最好把本地工作组设成一个显卡能支持的最大值 ,但是不同的显卡支持的最大值又不同,该怎么设置?
https://blog.csdn.net/DSQ_17/article/details/21457507















 892
892











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









