






1. 定义
下面将针对CUDA中的 latency 和 overhead,给出解释。
1.1 Latency
latency(延迟)有两种常见的定义:
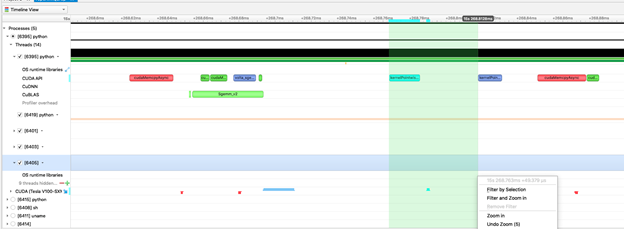
- Launch latency,有时也叫induction time,是从请求异步任务到开始执行它之间的时间。例如,CUDA内核启动延迟可以定义为从启动API调用开始到内核执行开始的时间范围。如下图1 所示,从开始启动调用(CUDA API 行)到开始内核执行(CUDA Tesla v100r - ssm 行)之间大约有20 μs的启动延迟。
- Task latency,或者叫做 total time,是将任务添加到队列和任务完成之间的时间。在这篇文章中,我们主要讨论的是Launch latency。
在异步系统中,延迟并不见得是坏事。想象一下,您进行10个简短的API调用来启动由10个大内核组成的依赖序列。从第一个API调用到第一次内核执行的延迟应该最小。但序列中的第10个内核可能会有很大的启动延迟,因为CPU排队执行10个启动命令并快速返回,而GPU必须在启动第10个之前完成前9个内核。
CPU使用异步launch的目的是允许CPU向GPU发送命令,然后在GPU执行命令时去执行其他任务。
1.2 Overhead
overhead(开销)即执行某个操作所需的时间,理想情况下您希望该操作所需的时间为零,但是额外工作所花费的时间(延迟)将会限制操作的执行速度。例如,启动CUDA内核时CPU代码的开销。如果在某个系统上launch内核需要10个µs,那么每秒最多只能启动100,000个内核。
下面是几种开销的定义:CPU wrapper, memory, and GPU launch overhead。
1.2.1 CPU wrapper overhead
这是在主机CPU端wrapper围绕CUDA内核的开销。在Nsight Systems GUI中,你会看到这是启动内核API调用的全部持续时间(上图中CUDA API 行的蓝色范围)。这包括多线程启动时驱动程序中发生的任何互斥锁争用。您可以通过收集OS Runtime数据来查看是否在驱动程序中遇到了互斥锁争用,该数据显示了任何pthread_mutex_lock调用的持续时间超过了用户设置的阈值。
Nsight Systems在捕获跟踪数据时增加了一些开销。事件在时间轴中的显示时间可能比应用程序在没有工具的情况下运行时要长。如果Nsight Systems跟踪的事件持续时间相对较短(几微秒或更短),并且在工作负载中频繁发生,由于跟踪事件的固定成本,Nsight系统的开销似乎更高。
1.2.2 Memory overhead
内存开销是将数据从CPU来回移动到GPU,或从一个GPU移动到另一个GPU的开销。例如,读取输入张量和将输出写入DRAM,该操作的内存开销表现为从API调用到队列 -> 排队 -> 输入数据复制到GPU内存直到复制完成的时间范围。
内存开销可以在内核启动时隐藏,因为GPU可以在执行一个内核的同时上传下一个内核的输入数据,并从上一个内核下载输出。
1.2.3 GPU launch overhead
这是GPU取出命令并开始执行它所需要的时间。包括:
- 如果GPU之前有一个命令需要等待未完成的工作完成,那么它可能会被阻塞。
- CUDA 流允许用户异步启动一系列必须按顺序执行的内核和memcpy。GPU会自动等待流中的前一项完成,然后再开始下一项。
- GPU可能需要完成高优先级的内核,然后才能启动低优先级的内核。
2. 理解时间轴上的overhead 和 latency
2.1 内核生命周期
使用Nsight Systems GUI,您可以跟踪内核生命周期中发生的事件。
- CPU events: 上图标记为 CUDA API 的行包含与内核执行相关的CPU CUDA调用。红色的事件是来自CPU的内存传输调用。蓝色的是启动CUDA内核的调用,绿色的是CUDA同步调用。
- GPU events: 左边CUDA标签下面的线表示在这个GPU上发生的事件。绿色的事件表示从主机复制到设备的内存。蓝色的事件是实际的内核工作。粉红色的事件是从设备返回到主机的内存传输。灰色条是用户在他们的代码中创建的NVTX注释范围,投影到在GPU上运行的时间。
- Launch latency: 这是从开始调用工作到开始执行工作之间的时间。在这个视图中,它是CPU第一个蓝框开始和GPU第一个蓝框开始之间的时间,如示例中的黑线所示。
2.2 CPU gaps
在分析以下vectorAdd CUDA Toolkit示例时,您可以在CPU时间轴上找到一个间隙的示例。
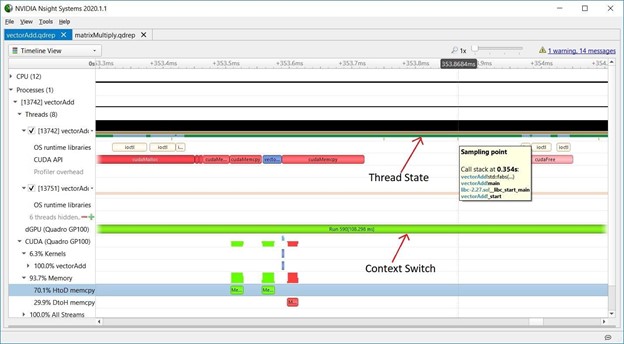
在CUDA API时间轴的上方,线程的状态表明它很忙,即CPU正在执行一些其他操作。在Nsight系统中,CPU采样,操作系统运行时,API跟踪,添加NVTX工具和跟踪NVTX可以帮助您弄清楚CPU在CUDA API调用之间做了什么。要了解更多关于NVIDIA Tools Extension (NVTX) API的信息,请参见CUDA Pro Tip: Generate Custom Application Profile Timelines with NVTX。在GPU时间轴上,GPU可能正在执行另一个上下文(它可能已经切换了上下文),或者它可能处于空闲状态在等待更多的工作被调度。
2.3 GPU context switching
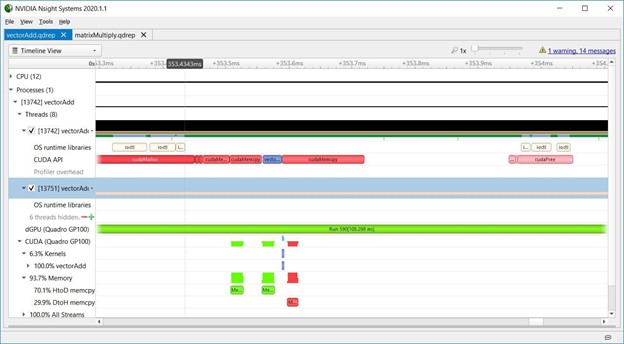
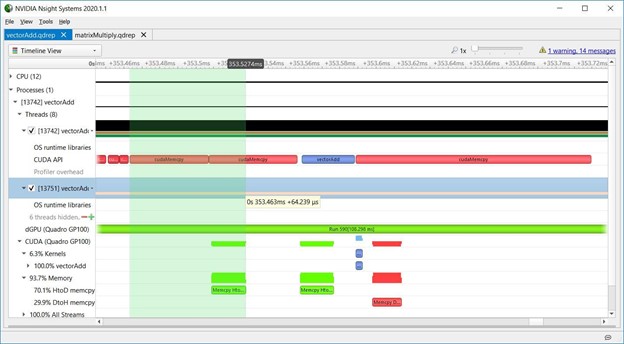
下图是Nsight Systems时间轴的屏幕截图,显示了vectorAdd CUDA Toolkit示例的重要部分。“dGPU (Quadro GP100)”行表示GPU上下文切换。在此期间,长条绿色的Run范围表明GPU没有从vectorAdd的上下文切换。
2.4 Host to device memory overhead
下图显示了vectorAdd中的HtoD内存开销。尽管使用了cudaMemcpy API,但这是一个来自可分页内存的异步HtoD拷贝。使用异步拷贝操作,并且将拷贝和内核启动重叠可以隐藏拷贝带来延迟。延迟隐藏是GPU编程中的一项重要技术。有关CUDA memcpy行为的更多信息,请参见API同步行为。
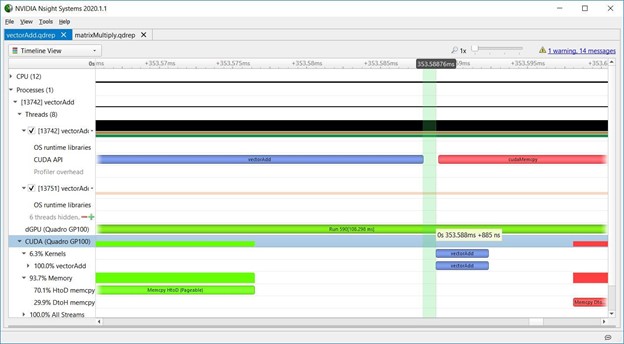
2.5 Nsight Systems overhead
下图显示内核启动API和内核在GPU上的执行之间的间隙,表示Nsight Systems开销,通常少于一微秒,如截图所示,表示在这种情况下,GPU在启动API调用完成后开始执行内核大约需要一微秒。
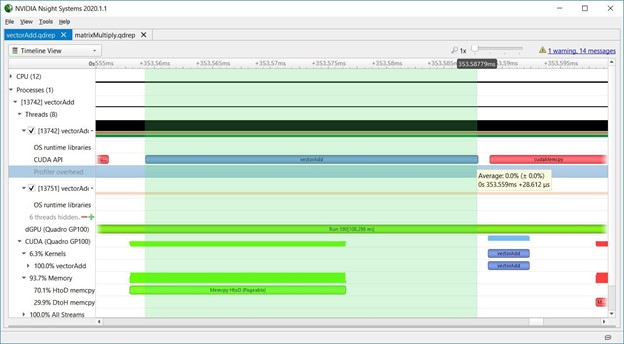
2.6 CPU overhead
下图显示了整个启动API调用期间的CPU开销。
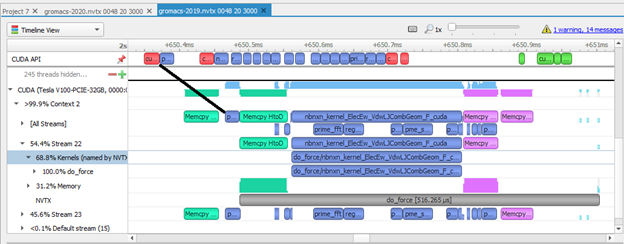
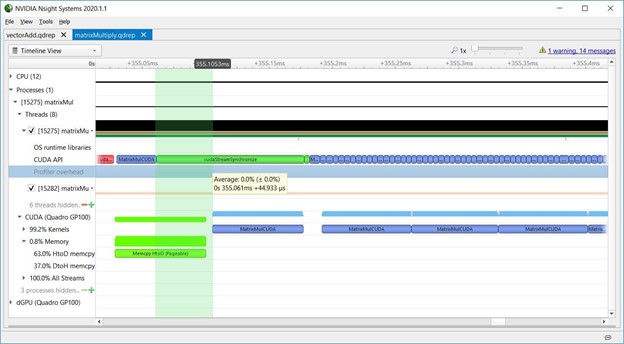
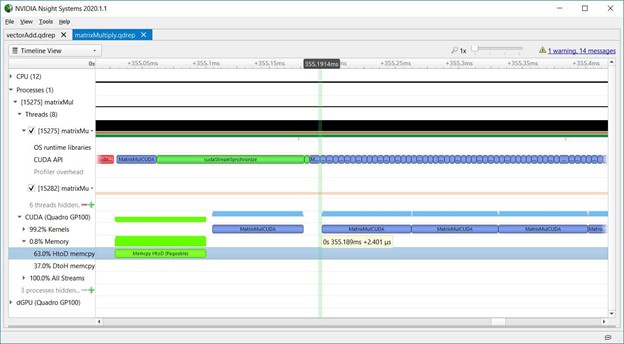
2.7 Stream synchronization
下图显示了matrixMul CUDA工具包示例,其中CPU将memcpy(红色)和内核(蓝色)入队到一个流中,然后调用cudaStreamSynchronize(绿色)阻塞,直到该流中排队的工作完成。这里的内核启动延迟是由于GPU必须按顺序执行流中的任务,直到前面的memcpy完成,内核才开始执行。对cudaStreamSynchronize的长调用显示了CPU在等待GPU工作完成。CPU可以在调用cudaStreamSynchronize之前去做其他工作,使CPU和GPU能够并行执行。
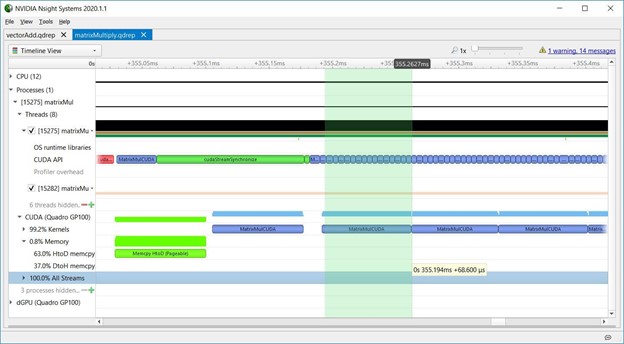
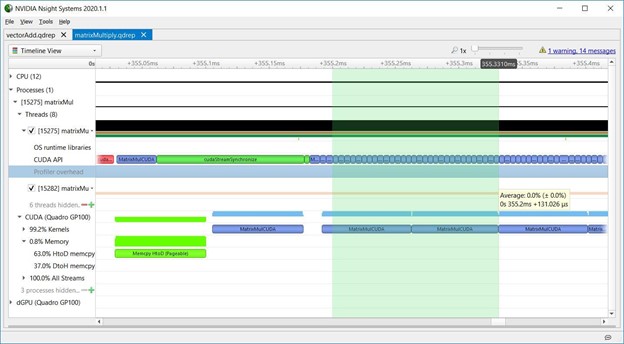
2.8 Launch latency
关于内核启动延迟,matrixMul还显示了CPU异步启动内核序列,GPU按顺序执行它们。下图显示了每次内核启动延迟是如何增加的,因为CPU API调用很短,而GPU内核执行时间更长。内核启动延迟的增加并不意味着效率低下。它显示CPU走在GPU前面,因此当GPU在队列中执行工作时,CPU可以自由地执行其他任务。这些数据表明,matrixMul在维持GPU的工作队列方面做得很好,因为GPU在这部分时间轴上的工作没有空白。
GPU编程的第一个挑战是避免CPU瓶颈并保持GPU繁忙——你希望GPU成为瓶颈。当你已经优化了程序的CPU部分,Nsight Systems显示GPU是瓶颈时,是时候使用NVIDIA Nsight Compute来分析各个内核,并研究如何使它们更高效。或者,您可以使用更快或更多的GPU来使程序的GPU部分执行得更快。
想知道内核总耗时中各部分工作的占比?Nsight Systems只是一个用来查看在时间轴上事件开始和结束的工具。所有由内核完成的工作——即算术和内存访问指令——都发生在蓝色条内。要了解内核内部发生了什么,请使用NVIDIA Nsight Compute。该工具分离单个内核并对它们进行深入分析。虽然运行时间较长,但可以获得更详细的信息。

















 821
821

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









