







一、意义
在使用较深的网络时,BatchNormalization(批量归一化)几乎是必需的,可以加速收敛。
对于图1所示的全连接层神经网络,输出节点的GroundTruth为
,损失函数为
,则损失对权重
的梯度为:
更新权重的梯度为:
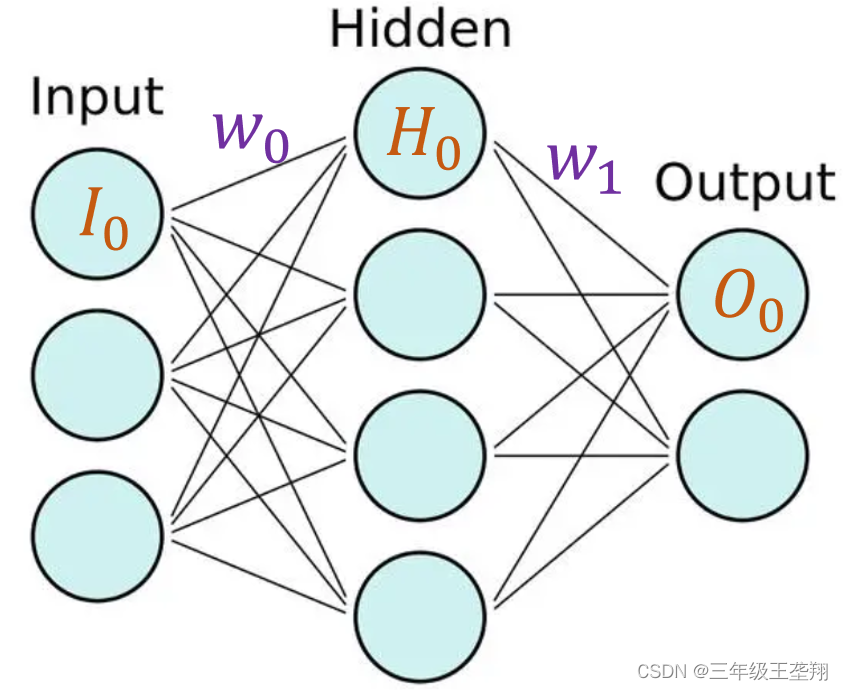
如果该网络有5个隐含层,那么更新底层权重的梯度为:
从上面的推导可知,如果网络非常深,那么更新底层权重的梯度后面会乘很多偏导数,而偏导数一般比较小,小于1,所以网络底层的梯度会非常小,从而权重更新很慢,造成底层训练速度慢。
而底层权重一旦改变,顶层权重也需要跟着改变,因此造成收敛变慢,网络训练速度慢。
解决这个问题的思路为在学习网络底层时避免变化网络顶层
二、定义
计算主要涉及如下公式:
为可学习的参数,对应新的方差和均值。
其中:
,
是一个很小的数,用于防止分母为零
三、用法
可用位置:
# 全连接层和卷积层的输出上,激活函数前
# 全连接层和卷积层的输入上
对于全连接层,作用在特征维,即
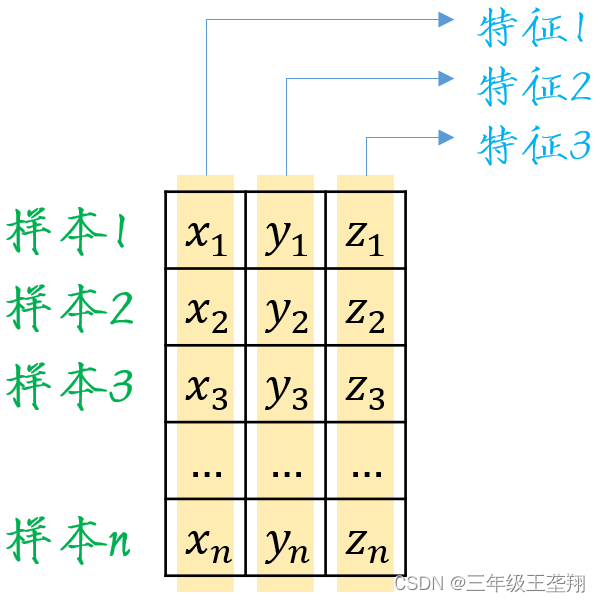
对于卷积层,作用在通道维
四、总结
# 最好不要与DropOut组合使用
# 可以加速收敛,一般不会增加正确率

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









