







自动驾驶场景中刚体和非刚体运动处理
1 D-RelNet: Joint Object and Relational Network for 3D Prediction https://github.com/nileshkulkarni/relative3d
提出了一种预测场景中物体三维形状和姿态的方法。追求这一目标的现有基于学习的方法会对每个对象进行独立预测,而不会利用它们之间的关系。我们认为,对这些关系进行推理是至关重要的,并提出了一种将其纳入三维预测框架的方法。除了独立的单目标预测之外,我们还以相对3D姿态的形式预测成对关系,并证明这些可以很容易地合并以改进目标级估计。我们报告了不同数据集(SUNCG,NYUv2)的性能,并表明我们的方法比独立的预测方法有显著的改进,同时也优于其他隐式推理方法。
2. Deep Non-Rigid Structure from Motion
非刚性运动结构(nrsfm)是指从具有二维对应关系的图像集合中重建摄像机和非刚性物体的三维点云的问题。目前的nrsfm算法局限于两个方面:(i)图像的数量,和(ii)它们可以处理的形状变化类型。这些困难源于系统条件和需要建模的自由度之间的内在冲突,这阻碍了它在视觉中的许多应用的实用性。本文提出了一种新的nrsfm分层稀疏编码模型,它可以克服(i)和(ii)在一定程度上,nrsfm可以应用于以前认为不适定的视觉问题。该方法在实际应用中被实现为一种具有独特结构的无监督深度神经网络(dnn)自动编码器的训练,该结构能够从三维结构中分离出姿态。利用现代的深度学习计算平台,我们可以以前所未有的规模和形状复杂度来解决nrsfm问题。我们的方法没有三维监控,仅依赖于二维点对应。此外,我们的方法还可以处理丢失/遮挡的二维点,而无需矩阵完成。大量的实验证明了我们的方法令人印象深刻的性能,在某些情况下,我们对所有可用的最先进的作品都表现出了卓越的精度和鲁棒性。我们进一步提出了一种新的质量度量(基于网络权值),它绕过了对三维地面真实性的需求,以确定我们对重建能力的信心。我们相信,我们的工作是一个重大的进步,超过当前最先进的方法。
3.DynamicFusion: Reconstruction and Tracking of Non-rigid Scenes in Real-Time
我们提出了第一个能够实时重建非刚性变形场景的稠密slam系统,通过融合从消费级传感器捕获的rgbd扫描。我们的dynamicfusion方法重建场景几何体,同时估计密集的6d运动场,该运动场将估计的几何体扭曲成实时帧。与KinectFusion一样,我们的系统随着更多测量数据的融合而产生越来越多的去噪、详细和完整的重建,并实时显示更新的模型。由于不需要模板或其他先验场景模型,该方法适用于范围广泛的运动对象和场景。
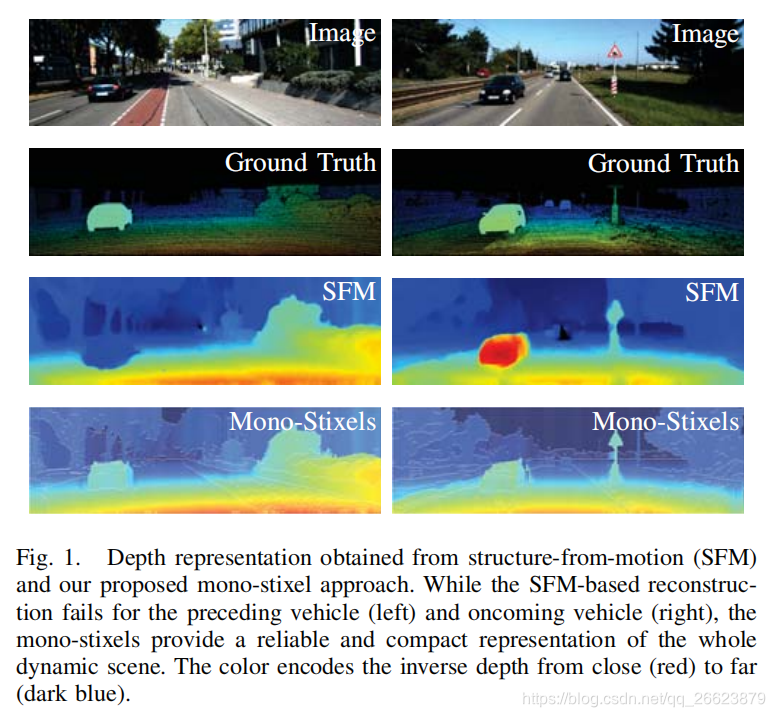
4.Mono-Stixels: Monocular depth reconstruction of dynamic street scenes Mono-Stixels
本文提出了一种用于动态街道场景的紧凑的环境表示方法——单像素。单点体像素是一种从单目相机序列中估计单点体像素的新方法,取代了传统的立体深度测量方法。该方法基于光流估计、像素语义分割和摄像机运动,将动态场景的深度、运动和语义信息作为一维能量最小化问题进行联合推理。stixel的光流由单应描述。通过应用单体stixel模型,一个stixel单应的自由度降低到只有两个自由度。此外,我们利用场景模型和语义信息来处理移动对象。在我们的实验中,我们使用公共可用的deepflow进行光流估计,使用fcn8s作为语义信息的输入,并在kitti 2015数据集上显示,单体像素提供了场景静态部分和移动部分的紧凑和可靠的深度重建。因此,单体stixels从运动方法上克服了以往结构对静态场景的限制。
————————————————
版权声明:本文为CSDN博主「流浪机器人」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_26623879/article/details/102749123
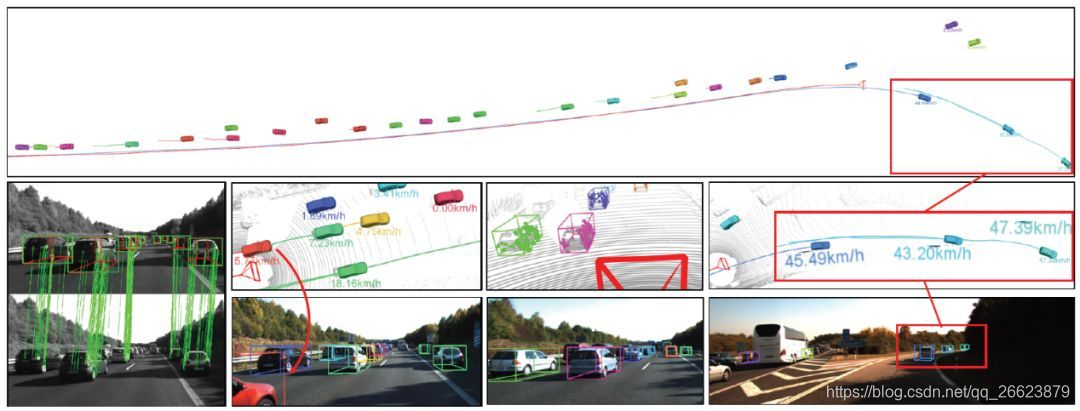
5.Beyond Pixels: Leveraging Geometry and Shape Cues for OnlineMulti-Object Tracking
介绍了一种用于道路场景中多目标跟踪的几何模型、新的目标形状和姿态代价。仅使用单目相机的图像,我们就可以根据几个3D提示(如对象姿势、形状和运动)来计算对象轨迹的成对偏差。 所提出的代价与数据关联方法无关,可以合并到任何优化框架中以输出并行数据关联。这些代价易于实现,可以实时计算,并相互补充,以计算检测帧跟踪中可能出现的误差。我们对设计成本进行了广泛的分析,并通过经验证明,在使用一系列目标探测器、展示各种相机和目标运动以及更重要的是,不依赖于关联框架的选择的各种条件下,与现有技术相比,我们的技术水平有了一致的提高。我们还表明,通过使用simplestof关联框架(两帧匈牙利赋值),我们在道路场景中的多目标跟踪方面超过了最新水平
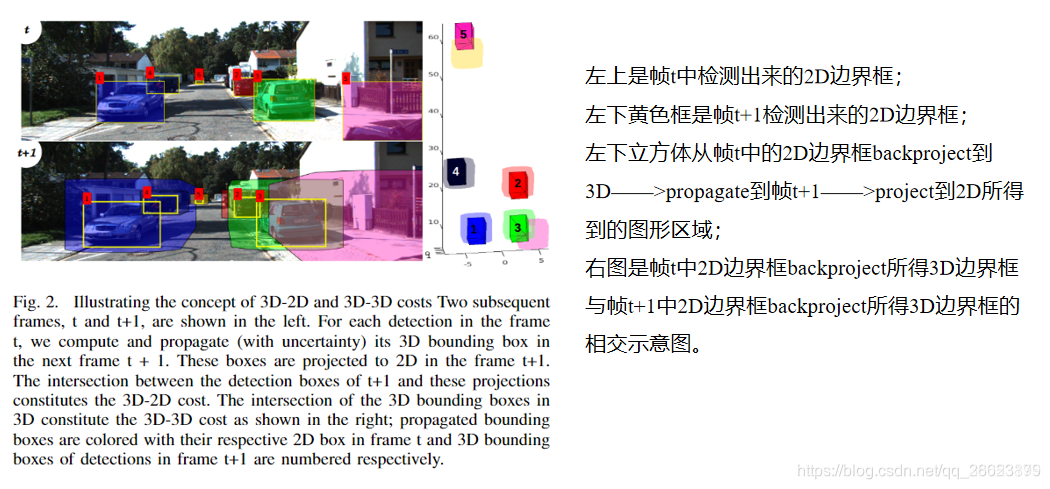
6.Stereo Vision-based Semantic 3D Object and Ego-motion Tracking for Autonomous Driving
用2D目标检测和轻量级语义分割结合推断出场景中3D目标的粗轮廓。在估计相机运动的基础上进一步推断场景中3D物体的位姿
-
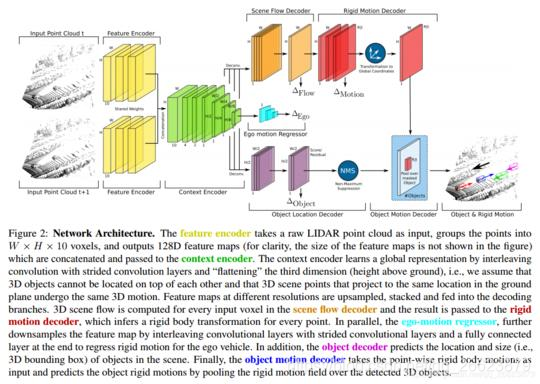
PointFlowNet: Learning Representations for Rigid Motion Estimation from Point Clouds
尽管基于图像的三维场景流估计取得了显著进展,但这种方法的性能还没有达到许多应用所要求的逼真度。同时,这些应用通常不局限于基于图像的估计:激光扫描器提供了传统相机的流行替代品,例如在自动驾驶汽车的环境中,因为它们直接产生一个三维点云。本文提出了一种利用深度神经网络对非结构化点云进行三维运动估计的方法。在单次前进过程中,我们的模型共同预测三维场景流以及场景中对象的三维边界框和刚体运动。虽然从非结构化点云估算三维场景流的前景很好,但这也是一项具有挑战性的任务。研究表明,传统的刚体运动全局表示方法禁止CNN进行推理,并提出了一种平移等变表示方法来规避这一问题。为了训练我们的深层网络,需要一个大的数据集。正因为如此,我们用虚拟物体增强了KITTI的真实场景,真实地模拟了遮挡,并模拟了传感器噪声。与传统的和基于学习的技术进行了彻底的比较,突出了该方法的鲁棒性。
8.从光流角度考虑
Self-supervised Learning with Geometric Constraints in Monocular Video Connecting Flow, Depth, and Camera
我们提出了一个自监督学习框架来估计视频中单个物体的运动和单目深度。我们将物体运动建模为6自由度刚体变换。实例分割掩码用于引入对象信息。与预测像素级光流图以模拟运动的方法相比,我们的方法显著减少了要估计的值的数量。此外,我们的系统通过使用预先计算的摄像机自我运动和左右一致性来消除预测的尺度模糊性。在KITTI数据集上的实验表明,我们的系统能够在不需要外部标注的情况下捕捉物体的运动,有助于动态区域的深度预测。我们的系统在三维场景流预测方面优于早期的自监督方法,并且在光流估计方面产生了可比的结果。

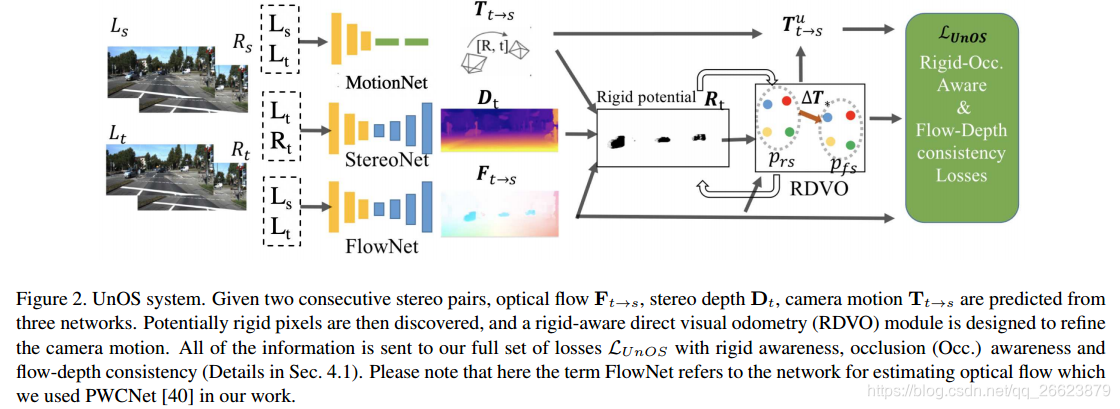
UnOS: Unified Unsupervised Optical-flow and Stereo-depth Estimation by Watching Videos
本文在文献[31]的基础上,利用卷积神经网络(CNN)固有的几何一致性,提出了UnOS,一个统一的无监督光流和立体深度估计系统。UnOS明显优于其他独立处理这两个任务的最新(SOTA)无监督方法。具体来说,给定视频中的两个连续立体图像对,UnOS使用三个平行cnn估计每像素立体深度图像、相机ego运动和光流。基于这些量,UnOS计算刚性光流,并将其与从流网络估计的光流进行比较,得到满足刚性场景假设的像素。然后,我们鼓励在刚性区域内两个估计流之间的几何一致性,并由此导出刚性感知直接视觉里程(RDVO)模块。我们还提出了刚性和阻塞感知的流一致性损失来学习UnOS。我们在流行的KITTI数据集上评估了4个相关任务的结果,即立体深度、光流、视觉里程和运动分割。
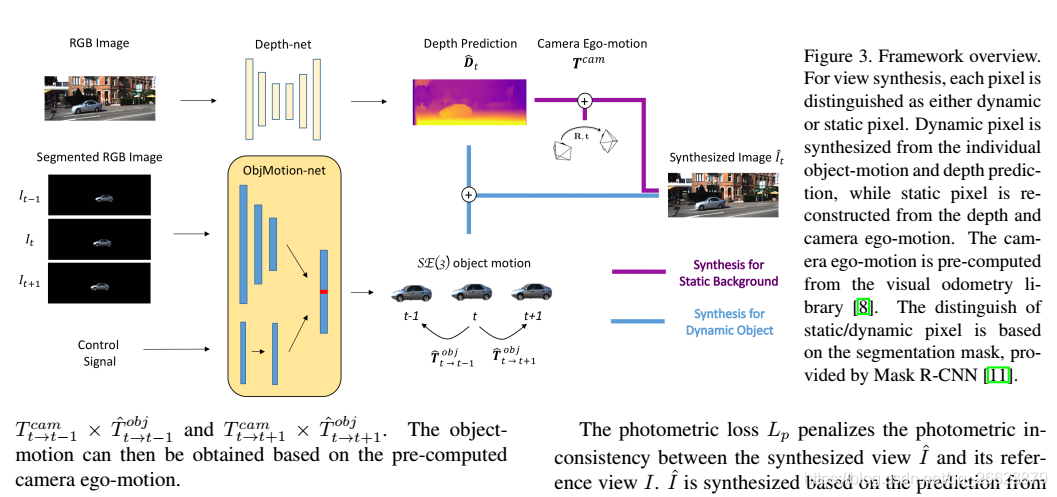
Self-supervised Object Motion and Depth Estimation from Video
我们提出了一个自监督学习框架来估计视频中单个物体的运动和单目深度。我们将物体运动建模为6自由度刚体变换。实例分割掩码用于引入对象信息。与预测像素级光流图以模拟运动的方法相比,我们的方法显著减少了要估计的值的数量。此外,我们的系统通过使用预先计算的摄像机自我运动和左右一致性来消除预测的尺度模糊性。在KITTI数据集上的实验表明,我们的系统能够在不需要外部标注的情况下捕捉物体的运动,有助于动态区域的深度预测。我们的系统在三维场景流预测方面优于早期的自监督方法,并且在光流估计方面产生了可比的结果。














 3116
3116











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









