






# GoogLeNet
1. 模型
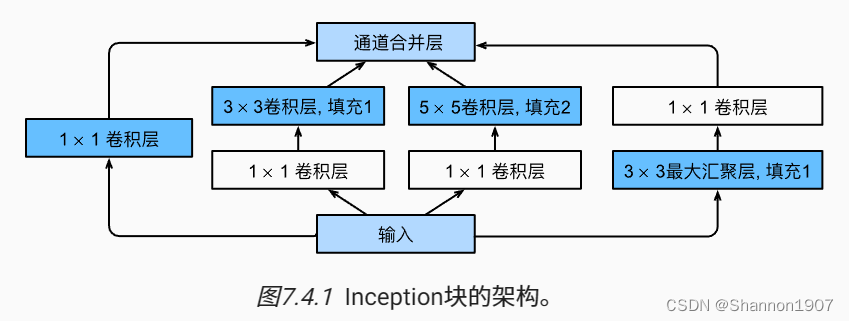
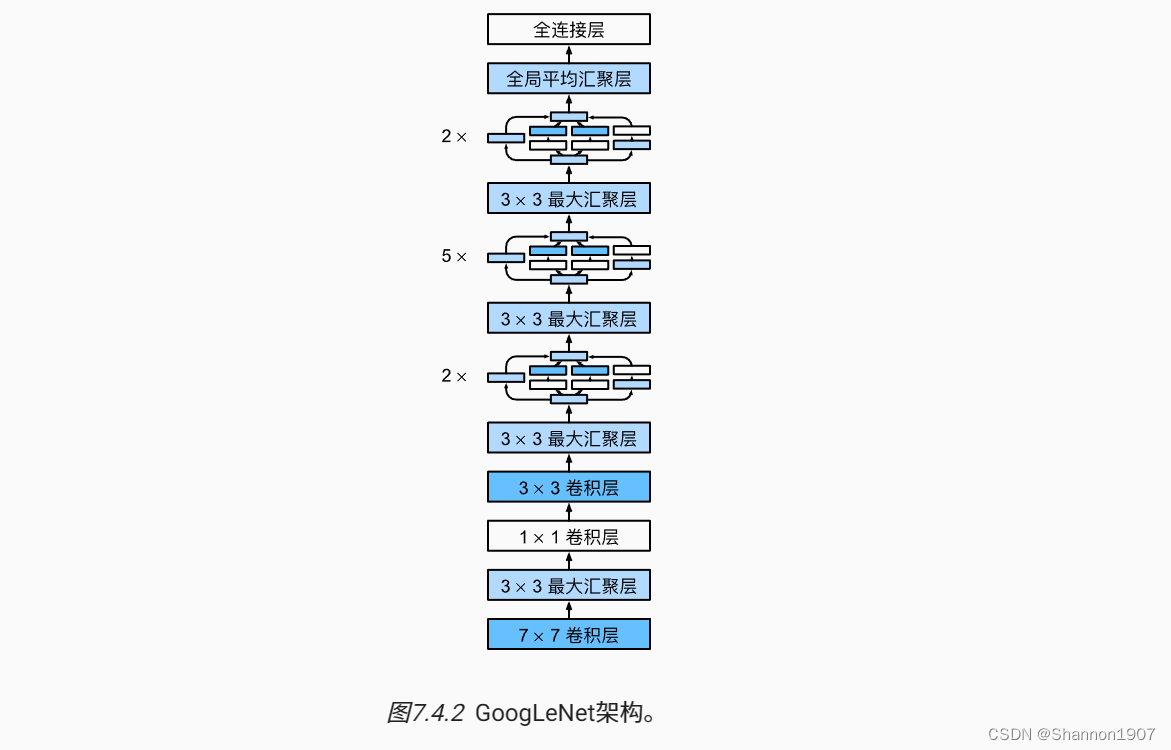
图片来源:动手学深度学习 by 李沐
2. 代码
import torch
from torch import nn
from torch.nn import functional as F
from d2l import torch as d2l
class Inception_my(nn.Module):
def __init__(self, in_channels, c1, c2, c3, c4, **kwargs):
super(Inception_my, self).__init__(**kwargs)
self.p1_1 = nn.Conv2d(in_channels, c1, kernel_size=1)
self.p2_1 = nn.Conv2d(in_channels, c2[0], kernel_size=1)
self.p2_2 = nn.Conv2d(c2[0], c2[1], kernel_size=3, padding=1)
self.p3_1 = nn.Conv2d(in_channels, c3[0], kernel_size=1)
self.p3_2 = nn.Conv2d(c3[0], c3[1], kernel_size=5, padding=2)
self.p4_1 = nn.MaxPool2d(3, stride=1, padding=1)
self.p4_2 = nn.Conv2d(in_channels, c4, kernel_size=1)
def forward(self, X):
p1 = F.relu(self.p1_1(X))
p2 = F.relu(self.p2_2(F.relu(self.p2_1(X))))
p3 = F.relu(self.p3_2(F.relu(self.p3_1(X))))
p4 = F.relu(self.p4_2(self.p4_1(X)))
return torch.concat((p1, p2, p3, p4), dim=1) #(0, 1, 2, 3), dim=1表channels
# 实现5个stage
b1 = nn.Sequential(nn.Conv2d(1, 64, kernel_size=7, stride=2, padding=3), nn.ReLU(),
nn.MaxPool2d(3, stride=2, padding=1))
b2 = nn.Sequential(nn.Conv2d(64, 64, kernel_size=1), nn.ReLU(),
nn.Conv2d(64, 192, kernel_size=3, padding=1),
nn.MaxPool2d(3, stride=2, padding=1))
b3 = nn.Sequential(Inception_my(192, 64, (96, 128), (16, 32), 32),
Inception_my(256, 128, (128, 192), (32, 96), 64),
nn.MaxPool2d(3, stride=2, padding=1))
b4 = nn.Sequential(Inception_my(480, 192, (96, 208), (16, 48), 64),
Inception_my(512, 160, (112, 224), (24, 64), 64),
Inception_my(512, 128, (128, 256), (24, 64), 64),
Inception_my(512, 112, (144, 288), (32, 64), 64),
Inception_my(528, 256, (160, 320), (32, 128), 128),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1))
b5 = nn.Sequential(Inception_my(832, 256, (160, 320), (32, 128), 128),
Inception_my(832, 384, (192, 384), (48, 128), 128),
nn.AdaptiveAvgPool2d((1,1)),
nn.Flatten())
net = nn.Sequential(b1, b2, b3, b4, b5, nn.Linear(1024, 10))
X = torch.rand((1, 1, 96, 96), dtype=torch.float32)
for layer in net:
X = layer(X)
print(layer.__class__.__name__, 'output shape:', X.shape)
lr, num_epochs, batch_size = 0.1, 10, 128
train_iter, test_iter = d2l.load_data_fashion_mnist(batch_size)
d2l.train_ch6(net, train_iter, test_iter, num_epochs, lr, torch.try_gpu())














 1160
1160

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









