







1.1 Optimization objective
先回顾一下逻辑回归的相关概念
hθ(x)=11+e−θTx
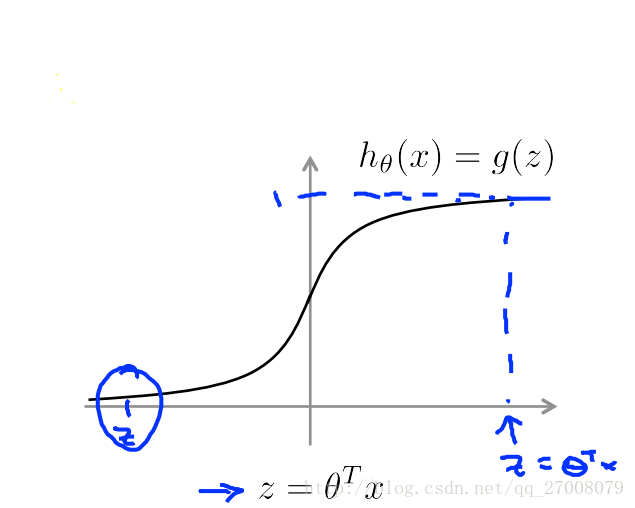
IF y=1, we want hθ(x)≈1 , θTx≫0
IF y=0, we want hθ(x)≈0 , θTx≪0
其CostFunction为:
J(θ)=1m[∑mi=1y(i)(−loghθ(x(i)))+(1−y(i))(−(log(1−hθ(x(i)))))]+λ2m∑mj=1θ2j
我们看下在SVM中对costfunction的改变
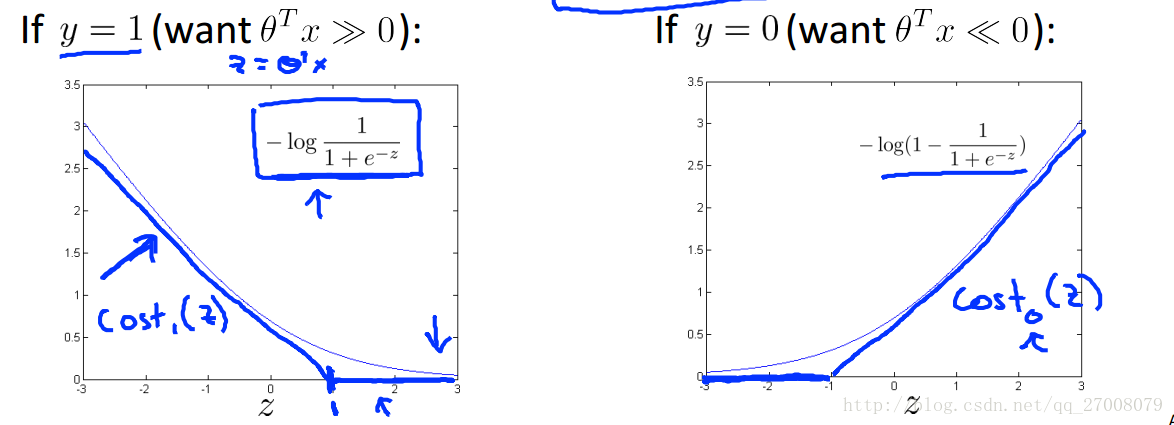
将其中log函数部分换成了蓝色折线所代表的cost函数。
costFunction也相应的改变为
J(θ)=1m[∑mi=1y(i)Cost1(θTx
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









