







文章目录
笔记
FOTS是一个快速的端到端的集成检测+识别的框架,和其他two-stage的方法相比,FOTS具有更快的速度。FOTS通过共享训练特征,互补监督,从而压缩了特征提取所占用的时间。

上图,蓝色框为FOTS,红色框为其他two-stage方法,可以看出FOTS消耗的时间是two-stage时间的一半。
FOTS的整体结构由四部分组成。分别是:
-
卷积共享特征(shared convolutions)
共享网络的主干是 ResNet-50。 受FPN的启发,我们连接了低级特征映射和高级语义特征映射。共享卷积产生的特征图的分辨率是输入图像的1/4。
FOTS的基础网络结构为ResNet-50,共享卷积层采用了类似U-net的卷积的共享方法,将底层和高层的特征进行了融合。这部分和EAST中的特征共享方式一样。最终输出的特征图大小为原图的1/4。

-
文本检测分支(the text detection branch)
采用完全卷积网络作为文本检测器。 由于自然场景图像中有许多小文本框,我们将共享卷积中原始输入图像的1/32到1/4大小的特征映射放大。 在提取共享特征之后,应用一个转换来输出密集的每像素的单词预测。 第一个通道计算每个像素为正样本的概率。 与EAST类似,原始文本区域的缩小版本中的像素被认为是正的。 对于每个正样本,以下4个通道预测其到包含此像素的边界框的顶部,底部,左侧,右侧的距离,最后一个通道预测相关边界框的方向。 通过对这些正样本应用阈值和NMS产生最终检测结果。
这一部分与EAST相同。损失函数包括了分类的loss(Cross Entropy Loss)和坐标的回归的loss(IOU Loss)。实验中的平衡因子, γ r e g = 1 \gamma_{reg}=1 γreg=1。 -
RoIRotate操作(RoIRotate operation)
将有角度的文本块,经过仿射变换,转化为正常的轴对齐的文本块。
在这项工作中,我们修正输出高度并保持纵横比不变以处理文本长度的变化。对比RRoI,其通过最大池化将旋转的区域转换为固定大小的区域,而本文使用双线性插值来计算输出的值。避免了RoI与提取特征不对准,使得输出特征的长度可变,更加适用于文本识别。这个过程分为两个步骤:
①通过文本提议的预测或ground truth坐标计算仿射变换参数。
②将仿射变换分别应用于每个区域的共享特征映射,并获得文本区域的正常情况下水平的特征映射。 -
文本识别分支(the text recognition branch)
文本识别分支旨在使用由共享卷积提取并由RoIRotate转换的区域特征来预测文本标签。 考虑到文本区域中标签序列的长度,LSTM的输入特征沿着宽度轴通过原始图像的共享卷积仅减少两次。 否则,将消除紧凑文本区域中的可辨别特征,尤其是窄形字符的特征。 我们的文本识别分支包括类似VGG的顺序卷积,仅沿高度轴减少的汇集,一个双向LSTM,一个完全连接和最终的CTC解码器。
1.FOTS: Fast Oriented Text Spotting with a Unified Network
2.Abstract
Incidental scene text spotting is considered one of the most difficult and valuable challenges in the document analysis community. Most existing methods treat text detection and recognition as separate tasks. In this work, we propose a unified end-to-end trainable Fast Oriented Text Spotting (FOTS) network for simultaneous detection and recognition, sharing computation and visual information among the two complementary tasks.
偶然的场景文本检测识别被认为是文档分析中最困难和最有价值的挑战之一。大多数现有方法将文本检测和识别视为分开的任务。在这项工作中,我们提出了一个统一的端到端可训练的快速定向文本检测识别(FOTS)网络,用于同时进行检测和识别,在两个互补任务之间共享计算和视觉信息。
Specially, RoIRotate is introduced to share convolutional features between detection and recognition. Benefiting from convolution sharing strategy, our FOTS has little computation overhead compared to baseline text detection network, and the joint training method learns more generic features to make our method perform better than these two-stage methods.
特别地,引入了RoIRotate以在检测和识别之间共享卷积特征。受益于卷积共享策略,与基线文本检测网络相比,我们的FOTS具有很少的计算开销,并且联合训练方法学习了更多的通用特征,以使我们的方法比这两个阶段的方法更好。
Experiments on ICDAR 2015, ICDAR 2017 MLT, and ICDAR 2013 datasets demonstrate that the proposed method outperforms state-of-the-art methods significantly, which further allows us to develop the first real-time oriented text spotting system which surpasses all previous state-of-theart results by more than 5% on ICDAR 2015 text spotting task while keeping 22.6 fps.
对ICDAR 2015,ICDAR 2017 MLT和ICDAR 2013数据集的实验表明,所提出的方法比当前最先进的方法表现更好,这使我们能够开发出第一个实时的面向文本的检测识别系统,在ICDAR 2015文本发现任务上比所有以前的最新技术结果高出5%以上。
3.Introduction
Reading text in natural images has attracted increasing attention in the computer vision community [49, 43, 53, 44, 14, 15, 34], due to its numerous practical applications in document analysis, scene understanding, robot navigation, and image retrieval. Although previous works have made significant progress in both text detection and text recognition, it is still challenging due to the large variance of text patterns and highly complicated background.
在计算机视觉界[49、43、53、44、14、15、34]中阅读自然图像中的文本已引起越来越多的关注,这是由于它在文档分析,场景理解,机器人导航和图像检索中有大量实际应用。 尽管先前的工作在文本检测和文本识别方面都取得了重大进展,但由于文本模式的差异很大且背景非常复杂,因此仍然具有挑战性。
The most common way in scene text reading is to divide it into text detection and text recognition, which are handled as two separate tasks [20, 34]. Deep learning based approaches become dominate in both parts. In text detection, usually a convolutional neural network is used to extract feature maps from a scene image, and then different decoders are used to decode the regions [49, 43, 53].
场景文本阅读中最常见的方法是将其分为文本检测和文本识别,这被视为两个单独的任务[20,34]。基于深度学习的方法在这两个方面都占主导地位。 在文本检测中,通常使用卷积神经网络从场景图像中提取特征映射,然后使用不同的解码器对区域进行解码[49、43、53]。
While in text recognition, a network for sequential prediction is conducted on top of text regions, one by one [44, 14]. It leads to heavy time cost especially for images with a number of text regions. Another problem is that it ignores the correlation in visual cues shared in detection and recognition. A single detection network cannot be supervised by labels from text recognition, and vice versa.
在文本识别中,在文本区域的顶部逐个进行用于顺序预测的网络[44,14]。 特别是对于具有多个文本区域的图像,这会导致沉重的时间成本。 另一个问题是, 它忽略了在检测和识别中共享的视觉线索之间的相关性。单个检测网络无法通过文本识别中的标签进行监督,反之亦然。
In this paper, we propose to simultaneously consider text detection and recognition. It leads to the fast oriented text spotting system (FOTS) which can be trained end-to-end. In contrast to previous two-stage text spotting, our method learns more generic features through convolutional neural network, which are shared between text detection and text recognition, and the supervision from the two tasks are complementary. Since feature extraction usually takes most of the time, it shrinks the computation to a single detection network, shown in Fig. 1. The key to connect detection and recognition is the ROIRotate, which gets proper features from feature maps according to the oriented detection bounding boxes.
在本文中,我们建议同时考虑文本检测和识别。 它可以定向端到端训练的快速定位文本发现系统(FOTS)。 与以前的两阶段文本发现相反,我们的方法通过卷积神经网络学习更多的通用特征,这些特征在文本检测和文本识别之间共享,并且来自两个任务的监督是互补的。 由于特征提取通常花费大部分时间,因此将计算范围缩小到单个检测网络,如图1所示。 连接检测和识别的关键是ROIRotate,它根据定向检测边界框从特征图获得适当的特征映。
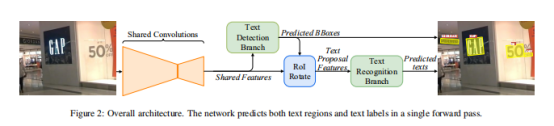
The architecture is presented in Fig. 2. Feature maps are firstly extracted with shared convolutions. The fully convolutional network based oriented text detection branch is built on top of the feature map to predict the detection bounding boxes. The RoIRotate operator extracts text proposal features corresponding to the detection results from the feature map. The text proposal features are then fed into Recurrent Neural Network (RNN) encoder and Connectionist Temporal Classification (CTC) decoder [9] for text recognition.
该体系结构如图2所示。首先使用共享卷积提取特征图。 基于全卷积网络的定向文本检测分支建立在特征图的顶部,以预测检测边界框。 RoIRotate运算符从特征图中提取相对应的文本提议特征和检测结果。 然后将文本建议特征输入到递归神经网络(RNN)编码器和连接器时序分类(CTC)解码器[9]中,以进行文本识别。
Since all the modules in the network are differentiable, the whole system can be trained end-to-end. To the best of our knoweldge, this is the first end-to-end trainable framework for oriented text detection and recognition. We find that the network can be easily trained without complicated post-processing and hyper-parameter tuning.
由于网络中的所有模块都是可区分的,因此可以对整个系统进行端到端的培训。 据我们所知,这是第一个用于定向文本检测和识别的端到端可训练框架。 我们发现,无需复杂的后处理和超参数调整,即可轻松训练网络。
The contributions are summarized as follows.
-
We propose an end-to-end trainable framework for fast oriented text spotting. By sharing convolutional features, the network can detect and recognize text simultaneously with little computation overhead, which leads to real-time speed.我们提出了一种用于快速定位文本的端到端可训练框架。 通过共享卷积特征,网络可以以很少的计算开销同时检测和识别文本,从而提高了实时速度。
-
We introduce the RoIRotate, a new differentiable operator to extract the oriented text regions from convolutional feature maps. This operation unifies text detection and recognition into an end-to-end pipeline.我们引入了RoIRotate,这是一种新的可微操作符,用于从卷积特征图中提取定向文本区域。 此操作将文本检测和识别统一到端到端管道中。
Without bells and whistles, FOTS significantly surpasses state-of-the-art methods on a number of text detection and text spotting benchmarks, including ICDAR 2015 [26], ICDAR 2017 MLT [1] and ICDAR 2013 [27].FOTS没有任何障碍的困难,在许多文本检测和文本发现基准上,远远超过了最新技术,包括ICDAR 2015 [26],ICDAR 2017 MLT [1]和ICDAR 2013 [27]。
4.Related Work
Text spotting is an active topic in computer vision and document analysis. In this section, we present a brief introduction to related works including text detection, text recognition and text spotting methods that combine both.
文本检测识别是计算机视觉和文档分析中的一个活跃主题。 在本节中,我们简要介绍相关工作,包括文本检测,文本识别和结合了两者的文本发现方法。
4.1.Text Detection
Most conventional methods of text detection consider text as a composition of characters. These character based methods first localize characters in an image and then group them into words or text lines. Sliding-window-based methods [22, 28, 3, 54] and connected-components based methods [18, 40, 2] are two representative categories in conventional methods.
大多数传统的文本检测方法都将文本视为字符的组合。 这些基于字符的方法首先将字符定位在图像中,然后将它们分组为单词或文本行。 基于滑动窗口的方法[22、28、3、54]和基于连接组件的方法[18、40、2]是常规方法中的两个代表性类别。
Recently, many deep learning based methods are proposed to directly detect words in images. 最近,提出了许多基于深度学习的方法来直接检测图像中的单词。
Tian et al. [49] employ a vertical anchor mechanism to predict the fixedwidth sequential proposals and then connect them.
田等[49]采用垂直锚机制预测固定宽度的顺序顺序候选位置,然后将它们连接起来。
Ma et al. [39] introduce a novel rotation-based framework for arbitrarily oriented text by proposing Rotation RPN and Rotation RoI pooling.
Ma等[39]通过提出旋转RPN和旋转RoI池,引入了一种新的基于旋转的框架,用于检测任意定向的文本。
Shi et al. [43] first predict text segments and then link them into complete instances using the linkage prediction.
Shi等[43]首先预测文本段,然后使用链接预测将它们链接到完整实例中。
With dense predictions and one step post processing, Zhou et al. [53] and He et al. [15] propose deep direct regression methods for multi-oriented scene text detection.
通过密集的预测和一步后处理,Zhou等[53]和He等[15]提出了用于多方向场景文本检测的深度直接回归方法。
4.2.Text Recognition
Generally, scene text recognition aims to decode a sequence of label from regularly cropped but variable-length text images. Most previous methods [8, 30] capture individual characters and refine misclassified characters later. Apart from character level approaches, recent text region recognition approaches can be classified into three categories: word classification based, sequence-to-label decode based and sequence-to-sequence model based methods.
通常,场景文本识别旨在从规则裁剪但长度可变的文本图像中解码标签序列。 以前的大多数方法[8,30]捕获单个字符并在以后细化错误分类的字符。 除字符级方法外,最近的文本区域识别方法可分为三类:基于单词分类,基于序列到标签解码和基于序列到序列模型的方法。
Jaderberg et al. [19] pose the word recognition problem as a conventional multi-class classification task with a large number of class labels (about 90K words). Jaderberg等[19]提出了将单词识别问题作为具有大量类别标签(约90K个单词)的常规多类别分类任务。
Su et al. [48] frame text recognition as a sequence labelling problem, where RNN is built upon HOG features and adopt CTC as decoder. Su等[48]帧文本识别作为序列标记问题,其中RNN建立在HOG功能的基础上,并采用CTC作为解码器。
Shi et al. [44] and He et al. [14] propose deep recurrent models to encode the max-out CNN features and adopt CTC to decode the encoded sequence. Shi等[44]和He等[14]提出了深度递归模型来编码最大输出CNN特征并采用CTC来解码编码序列。
Fujii et al. [5] propose an encoder and summarizer network to produce input sequence for CTC. 藤井等[5]提出了一种编码器和汇总器网络,以按顺序生成CTC。
Lee et al. [31] use an attention-based sequence-to-sequence structure to automatically focus on certain extracted CNN features and implicitly learn a character level language model embodied in RNN. Lee等[31]使用基于注意力的序列到序列结构自动关注某些提取的CNN特征,并隐式学习RNN中体现的字符级语言模型。
To handle irregular input images, Shi et al. [45] and Liu et al. [37] introduce spatial attention mechanism to transform a distorted text region into a canonical pose suitable for recognition.为了处理不规则的输入图像,Shi等人[45]和刘等[37]介绍了空间注意力机制,将扭曲的文本区域转换为适合识别的规范姿势。
4.3.Text Spotting
Most previous text spotting methods first generate text proposals using a text detection model and then recognize them with a separate text recognition model.
以前的大多数文本发现方法首先使用文本检测模型生成文本提议,然后使用单独的文本识别模型对其进行识别。
Jaderberg et al. [20] first generate holistic text proposals with a high recall using an ensemble model, and then use a word classifier for word recognition.
Jaderberg等[20]首先使用整体模型生成具有高召回率的整体文本候选框,然后使用单词分类器进行单词识别。
Gupta et al. [10] train a Fully-Convolutional Regression Network for text detection and adopt the word classifier in [19] for text recognition. Gupta等[10]训练了一个全卷积回归网络进行文本检测,并采用[19]中的单词分类器进行文本识别。
Liao et al. [34] use an SSD [36] based method for text detection and CRNN [44] for text recognition. 廖等[34]使用基于SSD [36]的方法进行文本检测,并使用CRNN [44]进行文本识别。
Recently Li et al. [33] propose an end-to-end text spotting method, which uses a text proposal network inspired by RPN [41] for text detection and LSTM with attention mechanism [38, 45, 3] for text recognition.
最近李等人[33]提出了一种端到端的文本定位方法,该方法使用受RPN [41]启发的文本提议网络进行文本检测,并使用具有关注机制[38,45,3]的LSTM进行文本识别。
Our method has two mainly advantages compared to them: (1) We introduce RoIRotate and use totally different text detection algorithm to solve more complicated and difficult situations, while their method is only suitable for horizontal text. (2) Our method is much better than theirs in terms of speed and performance, and in particular, nearly cost-free text recognition step enables our text spotting system to run at realtime speed, while their method takes approximately 900ms to process an input image of 600×800 pixels.
与之相比,我们的方法有两个主要优点:(1)介绍了RoIRotate,并使用完全不同的文本检测算法来解决更复杂和更困难的情况,而它们的方法仅适用于水平文本。 (2)我们的方法在速度和性能方面都比他们的方法好得多,特别是几乎免费的文本识别步骤使我们的文本点播系统能够实时运行,而他们的方法大约需要900毫秒来处理 600×800像素的输入图像。
5.Methodology
FOTS is an end-to-end trainable framework that detects and recognizes all words in a natural scene image simultaneously. It consists of four parts: shared convolutions, the text detection branch, RoIRotate operation and the text recognition branch.
FOTS是一个端到端的可训练框架,可同时检测和识别自然场景图像中的所有单词。 它由四个部分组成:共享卷积,文本检测分支,RoIRotate操作和文本识别分支。
5.1.Overall Architecture
An overview of our framework is illustrated in Fig. 2. The text detection branch and recognition branch share convolutional features, and the architecture of the shared network is shown in Fig. 3. The backbone of the shared network is ResNet-50 [12]. Inspired by FPN [35], we concatenate low-level feature maps and high-level semantic feature maps. The resolution of feature maps produced by shared convolutions is 1/4 of the input image. 图2说明了我们的框架。文本检测分支和识别分支共享卷积特征,共享网络的体系结构如图3所示。共享网络的骨干是ResNet- 50 [12]。 受FPN [35]的启发,我们将低级特征图和高级语义特征图连接起来。 共享卷积产生的特征图的分辨率为输入图像的1/4。
The text detection branch outputs dense per-pixel prediction of text using features produced by shared convolutions. With oriented text region proposals produced by detection branch, the proposed RoIRotate converts corresponding shared features into fixed-height representations while keeping the original region aspect ratio.
文本检测分支使用共享卷积产生的特征来输出密集的每像素文本预测。 利用检测分支生成的定向文本区域建议,建议的RoIRotate将相应的共享特征转换为固定高度的表示,同时保持原始区域的宽高比。
Finally, the text recognition branch recognizes words in region proposals. CNN and LSTM are adopted to encode text sequence information, followed by a CTC decoder. The structure of our text recognition branch is shown in Tab. 1.
最后,文本识别分支识别区域提议中的单词。 CNN和LSTM用于编码文本序列信息,然后是CTC解码器。 Tab1中显示了文本识别分支的结构。

5.2.Text Detection Branch
Inspired by [53, 15], we adopt a fully convolutional network as the text detector. As there are a lot of small text boxes in natural scene images, we upscale the feature maps from 1/32 to 1/4 size of the original input image in shared convolutions. After extracting shared features, one convolution is applied to output dense per-pixel predictions of words. The first channel computes the probability of each pixel being a positive sample. Similar to [53], pixels in shrunk version of the original text regions are considered positive. For each positive sample, the following 4 channels predict its distances to top, bottom, left, right sides of the bounding box that contains this pixel, and the last channel predicts the orientation of the related bounding box. Final detection results are produced by applying thresholding and NMS to these positive samples.
受[53,15]的启发,我们采用完全卷积的网络作为文本检测器。 由于自然场景图像中有许多小文本框,因此我们在共享卷积中将特征图的大小从原始输入图像的1/32放大到1/4。 提取共享特征后,将进行一次卷积以输出密集的每个像素的单词预测。 第一通道计算每个像素为正样本的概率。 类似于[53],原始文本区域的缩小版本中的像素被认为是正的。 对于每个正样本,以下4个通道预测其到包含此像素的边界框的顶部,底部,左侧,右侧的距离,最后一个通道预测相关边界框的方向。 最终检测结果是通过对这些阳性样品进行阈值分析和NMS产生的。

In our experiments, we observe that many patterns similar to text strokes are hard to classify, such as fences, lattices, etc. We adopt online hard example mining (OHEM) [46] to better distinguish these patterns, which also solves the class imbalance problem. This provides a F-measure improvement of about 2% on ICDAR 2015 dataset.
在我们的实验中,我们观察到许多类似于文本笔划的模式很难分类,例如栅栏,格子等。我们采用在线硬示例挖掘(OHEM)[46]来更好地区分这些模式,这也解决了类不平衡问题 问题。 这在ICDAR 2015数据集上提供了约2%的F量度改进。
The detection branch loss function is composed of two sterms: text classification term and bounding box regression term. The text classification term can be seen as pixel-wise classification loss for a down-sampled score map. Only shrunk version of the original text region is considered as the positive area, while the area between the bounding box and the shrunk version is considered as “NOT CARE”, and does not contribute to the loss for the classification. Denote the set of selected positive elements by OHEM in the score map as , the loss function for classification can be formulated as:
检测分支损失函数由两个项组成:文本分类项和边界框回归项。 文本分类术语可以看作是下采样分数图的逐像素分类损失。 仅将原始文本区域的缩小版本视为正区域,而将边界框和缩小版本之间的区域视为“NOT CARE”,并且不会造成分类损失。将OHEM在得分图中表示的一组选定的正元素表示为,分类的损失函数可以表示为:
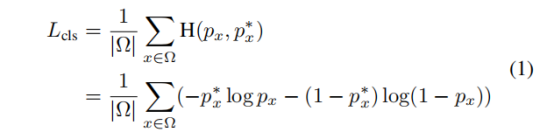
where
∣
⋅
∣
|\cdot|
∣⋅∣ is the number of elements in a set, and
H
(
p
x
,
p
x
∗
)
H(p_x,p^*_x)
H(px,px∗) represents the cross entropy loss between
p
x
p_x
px , the prediction of the score map, and
p
x
∗
p^*_x
px∗, the binary label that indicates text or non-text. As for the regression loss, we adopt the IoU loss in [52] and the rotation angle loss in [53], since they are robust to variation in object shape, scale and orientation:
其中,
∣
⋅
∣
|\cdot|
∣⋅∣是集合中元素的数量,
H
(
p
x
,
p
x
∗
)
H(p_x,p^*_x)
H(px,px∗)表示
p
x
p_x
px(分数图的预测)和
p
x
∗
p^*_x
px∗(指示文本或非文本的二进制标签)之间的交叉熵损失。 至于回归损失,我们在[52]中采用IoU损失,在[53]中采用旋转角损失,因为它们对于物体形状,比例和方向的变化具有鲁棒性:
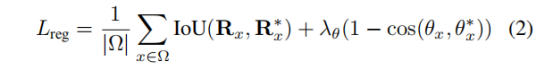
Here, IoU
R
x
,
R
x
∗
R_x,R^*_x
Rx,Rx∗ is the IoU loss between the predicted bounding box
R
x
R_x
Rx , and the ground truth
R
x
∗
R^*_x
Rx∗ . The second term is rotation angle loss, where
θ
x
θ_x
θxand
θ
x
∗
θ^*_x
θx∗ represent predicted orientation and the ground truth orientation respectively. We set the hyper-parameter
γ
θ
\gamma_\theta
γθ to 10 in experiments. Therefore the full detection loss can be written as:
在这里,IoU
R
x
,
R
x
∗
R_x,R^*_x
Rx,Rx∗是预测边界框
R
x
R_x
Rx和地面真实值
R
x
∗
R^*_x
Rx∗之间的IoU损耗。 第二项是旋转角损失,其中
θ
x
θ_x
θx和
θ
x
∗
θ^*_x
θx∗分别代表预测方向和真实标签的方向。 我们在实验中将超参数
γ
θ
\gamma_\theta
γθ设置为10。 因此,完整的检测损失可以写成:
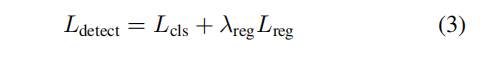
where a hyper-parameter
γ
r
e
g
\gamma_{reg}
γreg balances two losses, which is set to 1 in our experiments.
其中超参数
γ
r
e
g
\gamma_{reg}
γreg平衡了两个损耗,在我们的实验中将其设置为1。
5.3.RoIRotate
RoIRotate applies transformation on oriented feature regions to obtain axis-aligned feature maps, as shown in Fig. 4. In this work, we fix the output height and keep the aspect ratio unchanged to deal with the variation in text length. Compared to RoI pooling [6] and RoIAlign [11], RoIRotate provides a more general operation for extracting features for regions of interest. We also compare to RRoI pooling proposed in RRPN [39]. RRoI pooling transforms the rotated region to a fixed size region through max-pooling, while we use bilinear interpolation to compute the values of the output. This operation avoids misalignments between the RoI and the extracted features, and additionally it makes the lengths of the output features variable, which is more suitable for text recognition.
RoIRotate对定向的特征区域进行变换以获得轴对齐的特征图,如图4所示。在这项工作中,我们固定输出高度并保持宽高比不变,以处理文本长度的变化。 与RoI合并[6]和RoIAlign [11]相比,RoIRotate提供了更通用的操作来提取感兴趣区域的特征。 我们还与RRPN中提出的RRoI池进行了比较[39]。 RRoI池通过最大池化将旋转区域转换为固定大小的区域,而我们使用双线性插值来计算输出的值。 此操作避免了RoI和提取的特征之间的未对准,此外,它还使输出特征的长度可变,这更适合于文本识别。
This process can be divided into two steps. First, affine transformation parameters are computed via predicted or ground truth coordinates of text proposals. Then, affine transformations are applied to shared feature maps for each region respectively, and canonical horizontal feature maps of text regions are obtained. The first step can be formulated as:
此过程可以分为两个步骤。 首先,仿射变换参数是通过文本提议的预测坐标或真实坐标来计算的。 然后,将仿射变换分别应用于每个区域的共享特征图,并获得文本区域的规范水平特征图。 第一步可以表述为:

where M is the affine transformation matrix.
h
t
h_t
ht,
w
t
w_t
wt represent height (equals 8 in our setting) and width of feature maps after affine transformation. (x, y) represents the coordinates of a point in shared feature maps and (t, b, l, r) stands for distance to top, bottom, left, right sides of the text proposal respectively, and θ for the orientation. (t, b, l, r) and θ can be given by ground truth or the detection branch. With the transformation parameters, it is easy to produce the final RoI feature using the affine transformation:
其中M是仿射变换矩阵。
h
t
h_t
ht,
w
t
w_t
wt 代表仿射变换后的高度(在我们的设置中为8)和特征图的宽度。(x,y)表示共享特征图中点的坐标,(t,b,l,r)分别表示距文本提议的顶部,底部,左侧,右侧的距离,而θ表示方向。(t,b,l,r)和θ可以由真实标签或检测分支给出。 使用转换参数,可以使用仿射转换轻松生成最终的RoI功能:

where
V
i
j
c
V^c_{ij}
Vijc is the output value at location (i, j) in channel c and
U
i
j
c
U^c_{ij}
Uijc is the input value at location (n, m) in channel c.
h
s
h_s
hs,
w
s
w_s
ws represent the height and width of the input, and
ϕ
x
\phi_x
ϕx,
ϕ
y
\phi_y
ϕy are the parameters of a generic sampling kernel k(), which defines the interpolation method, specifically bilinear interpolation in this work. As the width of text proposals may vary, in practice, we pad the feature maps to the longest width and ignore the padding parts in recognition loss function.
其中
V
i
j
c
V^c_{ij}
Vijc是通道c中位置(i,j)的输出值,
U
i
j
c
U^c_{ij}
Uijc是通道c中位置(n,m)的输入值。
h
s
h_s
hs,
w
s
w_s
ws 代表输入的高度和宽度,而
ϕ
x
\phi_x
ϕx,
ϕ
y
\phi_y
ϕy 是通用采样内核k()的参数,该内核定义了插值方法,尤其是这项工作中的Biliear。 由于文本建议的宽度可能会有所不同,因此在实践中,我们将要素映射填充到最长宽度,而忽略识别损失函数中的填充部分。
Spatial transformer network [21] uses affine transformation in a similar way, but gets transformation parameters via a different method and is mainly used in the image domain, i.e. transforming images themselves. RoIRotate takes feature maps produced by shared convolutions as input, and generates the feature maps of all text proposals, with fixed height and unchanged aspect ratio.
空间变换器网络[21]以相似的方式使用仿射变换,但是通过不同的方法获得变换参数,并且主要用于图像领域,即变换图像本身。 RoIRotate将共享卷积生成的特征图作为输入,并生成所有文本建议的特征图,高度固定且纵横比不变。
Different from object classification, text recognition is very sensitive to detection noise. A small error in predicted text region could cut off several characters, which is harmful to network training, so we use ground truth text regions instead of predicted text regions during training. When testing, thresholding and NMS are applied to filter predicted text regions. After RoIRotate, transformed feature maps are fed to the text recognition branch.
与对象分类不同,文本识别对检测噪声非常敏感。 预测文本区域中的一个小错误可能会切断多个字符,这对网络训练有害。因此,在训练过程中,我们使用地面真实文本区域而不是预测文本区域。 测试时,将应用阈值和NMS来过滤预测的文本区域。 在RoIRotate之后,将转换后的特征图馈送到文本识别分支。
5.4.Text Recognition Branch
The text recognition branch aims to predict text labels using the region features extracted by shared convolutions and transformed by RoIRotate. Considering the length of the label sequence in text regions, input features to LSTM are reduced only twice (to 1/4 as described in Sec. 3.2) along width axis through shared convolutions from the original image. Otherwise discriminable features in compact text regions, especially those of narrow shaped characters, will be eliminated. Our text recognition branch consists of VGGlike [47] sequential convolutions, poolings with reduction along height axis only, one bi-directional LSTM [42, 16], one fully-connection and the final CTC decoder [9].
文本识别分支旨在使用通过共享卷积提取并由RoIRotate转换的区域特征来预测文本标签。 考虑到文本区域中标签序列的长度,通过与原始图像共享卷积,LSTM的输入特征沿宽度轴仅减少了两次(如第3.2节中所述为1/4)。 否则,将消除紧凑文本区域中的可辨别特征,尤其是那些狭窄形状的字符。 我们的文本识别分支包括VGGlike [47]顺序卷积,仅沿高度轴缩减的池,一个双向LSTM [42,16],一个完全连接和最终的CTC解码器[9]。
First, spatial features are fed into several sequential convolutions and poolings along height axis with dimension reduction to extract higher-level features. For simplicity, all reported results here are based on VGG-like sequential layers as shown in Tab. 1.
首先,将空间特征沿高度轴输入到几个顺序的卷积和池中,并缩小尺寸以提取更高级别的特征。 为了简单起见,此处所有报告的结果均基于Tab1所示的VGG类连续层。

Next, the extracted higher-level feature maps
L
∈
R
C
∗
H
∗
W
L \in R^{C*H*W}
L∈RC∗H∗W are permuted to time major form as a sequence
l
1
,
.
.
.
,
l
w
∈
R
C
∗
H
l_1,...,l_w \in R^{C*H}
l1,...,lw∈RC∗H and fed into RNN for encoding. Here we use a bi-directional LSTM, with D = 256 output channels per direction, to capture range dependencies of the input sequential features. Then, hidden states
h
1
,
.
.
.
,
h
w
∈
R
D
h_1,...,h_w \in R^D
h1,...,hw∈RD calculated at each time step in both directions are summed up and fed into a fully-connection, which gives each state its distribution
x
t
∈
R
∣
S
∣
x_t \in R^{|S|}
xt∈R∣S∣ over the character classes S. To avoid overfitting on small training datasets like ICDAR 2015, we add dropout before fully-connection. Finally, CTC is used to transform frame-wise classification scores to label sequence. Given probability distribution
x
t
x_t
xt over S of each
h
t
h_t
ht, and ground truth label sequence
y
∗
=
y
1
,
.
.
.
,
y
T
,
T
<
=
W
y^*={y_1,...,y_T},T<=W
y∗=y1,...,yT,T<=W, the conditional probability of the label
y
∗
y^*
y∗ is the sum of probabilities of all paths π agreeing with [9]:
接下来,将提取的高级特征图
L
∈
R
C
∗
H
∗
W
L \in R^{C*H*W}
L∈RC∗H∗W排列为时间主形式,序列为
l
1
,
.
.
.
,
l
w
∈
R
C
∗
H
l_1,...,l_w \in R^{C*H}
l1,...,lw∈RC∗H,并馈入RNN进行编码。 在这里,我们使用双向LSTM,每个方向D = 256个输出通道,以捕获输入顺序特征的范围依赖性。 然后,将在每个时间步长上在两个方向上计算出的隐藏状态
h
1
,
.
.
.
,
h
w
∈
R
D
h_1,...,h_w \in R^D
h1,...,hw∈RD 相加并馈入完全连接,从而给出每个状态的分布
x
t
∈
R
∣
S
∣
x_t \in R^{|S|}
xt∈R∣S∣。 为了避免过度适合于像ICDAR 2015这样的小型训练数据集,我们在完全连接之前添加了dropout。 最后,使用CTC将逐帧分类评分转换为标签序列。 给定每个
h
t
h_t
ht的S上的概率分布
x
t
x_t
xt,并且真值标签序列
y
∗
=
y
1
,
.
.
.
,
y
T
,
T
<
=
W
y^*={y_1,...,y_T},T<=W
y∗=y1,...,yT,T<=W,标签
y
∗
y^*
y∗条件概率是所有路径π同意的概率之和 与[9]:
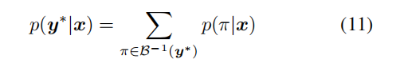
where B defines a many-to-one map from the set of possible labellings with blanks and repeated labels to
y
∗
y_∗
y∗. The training process attempts to maximize the log likelihood of summation of Eq. (11) over the whole training set. Following [9], the recognition loss can be formulated as:
其中B定义了从一组可能的带有空白和重复标签的标
y
∗
y_∗
y∗签到的多对一映射。 训练过程试图在整个训练集中,使等式(11)求和的对数似然性最大化。根据[9],识别损失可以表述为:
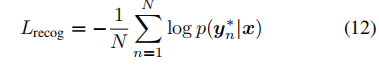
where N is the number of text regions in an input image, and
y
n
∗
y^*_n
yn∗ is the recognition label. Combined with detection loss
L
d
e
t
e
c
t
L_{detect}
Ldetect in Eq. (3), the full multi-task loss function is:
其中N是输入图像中文本区域的数量,
y
n
∗
y^*_n
yn∗是识别标签。 与等式(3)中的检测损失
L
d
e
t
e
c
t
L_{detect}
Ldetect相结合,完整的多任务丢失功能是:
where a hyper-parameter
γ
r
e
c
o
g
\gamma_{recog}
γrecog controls the trade-off between two losses.
γ
r
e
c
o
g
\gamma_{recog}
γrecog is set to 1 in our experiments.
其中超参数
γ
r
e
c
o
g
\gamma_{recog}
γrecog控制两个损耗之间的权衡。 在我们的实验中,
γ
r
e
c
o
g
\gamma_{recog}
γrecog设置为1。
5.5.Implementation Details
We use model trained on ImageNet dataset [29] as our pre-trained model. The training process includes two steps: first we use Synth800k dataset [10] to train the network for 10 epochs, and then real data is adopted to fine-tune the model until convergence. Different training datasets are adopted for different tasks, which will be discussed in Sec. 4. Some blurred text regions in ICDAR 2015 and ICDAR 2017 MLT datasets are labeled as “DO NOT CARE”, and we ignore them in training.
我们使用在ImageNet数据集[29]上训练的模型作为我们的预训练模型。 训练过程包括两个步骤:首先,我们使用Synth800k数据集[10]训练网络10个时间段,然后采用实际数据对模型进行微调,直到收敛为止。 针对不同的任务采用不同的训练数据集,这将在节4中讨论。 ICDAR 2015和ICDAR 2017 MLT数据集中的一些模糊文本区域被标记为“请勿关注”,我们在训练中将其忽略。
Data augmentation is important for robustness of deep neural networks, especially when the number of real data is limited, as in our case. First, longer sides of images are resized from 640 pixels to 2560 pixels. Next, images are rotated in range [ 10◦, 10◦] randomly. Then, the heights of images are rescaled with ratio from 0.8 to 1.2 while their widths keep unchanged. Finally, 640×640 random samples are cropped from the transformed images.
数据扩充对于深度神经网络的鲁棒性很重要,尤其是在实际数据数量有限的情况下(如本例所示)。 首先,将图像的较长边从640像素调整为2560像素。 接下来,将图像随机旋转到[10°,10°]范围内。 然后,图像的高度以0.8到1.2的比例重新缩放,而宽度保持不变。 最后,从转换后的图像中裁剪出640×640个随机样本。
As described in Sec. 3.2, we adopt OHEM for better performance. For each image, 512 hard negative samples, 512 random negative samples and all positive samples are selected for classification. As a result, positive-to-negative ratio is increased from 1:60 to 1:3. And for bounding box regression, we select 128 hard positive samples and 128 random positive samples from each image for training.
如3.2节所述,我们采用OHEM以获得更好的性能。 对于每个图像,选择512个硬阴性样本,512个随机阴性样本和所有阳性样本进行分类。 结果,正负比从1:60增加到1:3。 对于边界框回归,我们从每个图像中选择128个硬阳性样本和128个随机阳性样本进行训练。
At test time, after getting predicted text regions from the text detection branch, the proposed RoIRotate applys thresholding and NMS to these text regions and feeds selected text features to the text recognition branch to get final recognition result. For multi-scale testing, results from all scales are combined and fed to NMS again to get the final results.
在测试时,从文本检测分支获取预测的文本区域后,拟议的RoIRotate将阈值和NMS应用于这些文本区域,并将选定的文本特征馈送到文本识别分支以获取最终的识别结果。 对于多尺度测试,将所有尺度的结果合并并再次馈入NMS,以获得最终结果。


6.Experiments
We evaluate the proposed method on three recent challenging public benchmarks: ICDAR 2015 [26], ICDAR 2017 MLT [1] and ICDAR 2013 [27], and surpasses state-of-the-art methods in both text localization and text spotting tasks. All the training data we use is publicly available.
我们在三个最新的具有挑战性的公开基准上评估了所提出的方法:ICDAR 2015 [26],ICDAR 2017 MLT [1]和ICDAR 2013 [27],并且在文本本地化和文本发现任务方面都超过了最先进的方法。 我们使用的所有培训数据都是公开的。
6.1.Benchmark Datasets
- ICDAR 2015
ICDAR 2015 is the Challenge 4 of ICDAR 2015 Robust Reading Competition, which is commonly used for oriented scene text detection and spotting. This dataset includes 1000 training images and 500 testing images. These images are captured by Google glasses without taking care of position, so text in the scene can be in arbitrary orientations. For text spotting task, it provides 3 specific lists of words as lexicons for reference in the test phase, named as “Strong”, “Weak” and “Generic”. “Strong” lexicon provides 100 words per-image including all words that appear in the image. “Weak” lexicon includes all words that appear in the entire test set. And “Generic” lexicon is a 90k word vocabulary. In training, we first train our model using 9000 images from ICDAR 2017 MLT training and validation datasets, then we use 1000 ICDAR 2015 training images and 229 ICDAR 2013 training images to fine-tune our model.
ICDAR 2015是ICDAR 2015鲁棒性阅读比赛的第4个挑战,通常用于定向的场景文本检测和发现。 该数据集包括1000个训练图像和500个测试图像。 这些图像是由Google眼镜捕获的,而无需考虑位置,因此场景中的文本可以是任意方向。 对于文本发现任务,它提供了3个特定的单词列表作为词典,供测试阶段参考,分别称为“强”,“弱”和“通用”。 “强”词典每个图像提供100个单词,包括图像中出现的所有单词。 “弱”词典包括出现在整个测试集中的所有单词。 而“通用”词典是一个90k单词的词汇表。 在训练中,我们首先使用ICDAR 2017 MLT训练和验证数据集中的9000张图像训练模型,然后使用1000张ICDAR 2015训练图像和229张ICDAR 2013训练图像对模型进行微调。
- ICDAR 2017 MLT
ICDAR 2017 MLT is a large scale multi-lingual text dataset, which includes 7200 training images, 1800 validation images and 9000 testing images. The dataset is composed of complete scene images which come from 9 languages, and text regions in this dataset can be in arbitrary orientations, so it is more diverse and challenging. This dataset does not have text spotting task so we only report our text detection result. We use both training set and validation set to train our model.
ICDAR 2017 MLT是一个大规模的多语言文本数据集,包括7200个训练图像,1800个验证图像和9000个测试图像。 该数据集由来自9种语言的完整场景图像组成,并且该数据集中的文本区域可以处于任意方向,因此它更具多样性和挑战性。 该数据集没有文本识别任务,因此我们仅报告文本检测结果。 我们同时使用训练集和验证集来训练我们的模型。
- ICDAR 2013
ICDAR 2013 consists of 229 training images and 233 testing images, and similar to ICDAR 2015, it also provides “Strong”, “Weak” and “Generic” lexicons for text spotting task. Different to above datasets, it contains only horizontal text. Though our method is designed for oriented text, results in this dataset indicate the proposed method is also suitable for horizontal text. Due to there are too few training images, we first use 9000 images from ICDAR 2017 MLT training and validation datasets to train a pre-trained model and then use 229 ICDAR 2013 training images to fine-tune.
ICDAR 2013由229张训练图像和233张测试图像组成,与ICDAR 2015相似,它还提供“强”,“弱”和“通用”词典来进行文本发现任务。 与上述数据集不同,它仅包含水平文本。 尽管我们的方法是针对定向文本而设计的,但该数据集中的结果表明,该方法也适用于水平文本。 由于训练图像太少,我们首先使用ICDAR 2017 MLT训练和验证数据集中的9000张图像来训练预训练模型,然后使用229个ICDAR 2013训练图像进行微调。
6.2.Comparison with Two-Stage Method
Different from previous works which divide text detection and recognition into two unrelated tasks, our method train these two tasks jointly, and both text detection and recognition can benefit from each other. To verify this, we build a two-stage system, in which text detection and recognition models are trained separately. The detection network is built by removing recognition branch in our proposed net-work, and similarly, detection branch is removed from origin network to get the recognition network. For recognition network, text line regions cropped from source images are used as training data, similar to previous text recognition methods [44, 14, 37].
与以前的将文本检测和识别分为两个不相关任务的工作不同,我们的方法联合训练了这两个任务,并且文本检测和识别都可以从中受益。 为了验证这一点,我们构建了一个两阶段系统,其中分别对文本检测和识别模型进行了训练。 通过在我们提出的网络中删除识别分支来构建检测网络,类似地,从原始网络中删除检测分支以获得识别网络。 对于识别网络,类似于以前的文本识别方法[44、14、37],将从源图像裁剪的文本行区域用作训练数据。


As shown in Tab. 2,3,4, our proposed FOTS significantly outperforms the two-stage method “Our Detection” in text localization task and “Our Two-Stage” in text spotting task. Results show that our joint training strategy pushes model parameters to a better converged state.
如标签所示。 2,3,4,我们提出的FOTS在文本定位任务中明显优于两阶段方法“我们的检测”,在文本发现任务中优于“我们的两阶段”方法。 结果表明,我们的联合训练策略将模型参数推向更好的收敛状态。
FOTS performs better in detection because text recognition supervision helps the network to learn detailed character level features. To analyze in detail, we summarize four common issues for text detection, Miss: missing some text regions, False: regarding some non-text regions as text regions wrongly, Split: wrongly spliting a whole text region to several individual parts, Merge: wrongly merging several independent text regions together. As shown in Fig. 5, FOTS greatly reduces all of these four types of errors compared to “Our Detection” method. Specifically, “Our Detection” method focuses on the whole text region feature rather than character level feature, so this method does not work well when there is a large variance inside a text region or a text region has similar patterns with its background, etc. As the text recognition supervision forces the model to consider fine details of characters, FOTS learns the semantic information among different characters in one word that have different patterns. It also enhances the difference among characters and background that have similar patterns.
FOTS在检测方面表现更好,因为文本识别监控可以帮助网络学习详细的字符级功能。为了进行详细分析,我们总结了四个常见的文本检测问题:丢失:缺少一些文本区域,错:将一些非文本区域错误地视为文本区域,拆分:错误地将整个文本区域拆分为几个单独的部分,合并:错误地将几个独立的文本区域合并在一起。如图5所示,与“我们的检测”方法相比,FOTS大大减少了这四种类型的错误。具体来说,“我们的检测”方法侧重于整个文本区域特征,而不是字符级特征,因此,当文本区域内部存在较大差异或文本区域的背景图案相似时,此方法效果不佳。随着文本识别监督迫使模型考虑字符的精细细节,FOTS学习了一个单词中具有不同的模式。它还可以增强具有相似图案的字符和背景之间的差异。
As shown in Fig. 5, for the Miss case, “Our Detection” method misses the text regions because their color is similar to their background. For the False case, “Our Detection” method wrongly recognizes a background region as text because it has “text-like” patterns (e.g., repetitive structured stripes with high contrast), while FOTS avoids this mistake after training with recognition loss which considers details of characters in the proposed region. For the Split case, “Our Detection” method splits a text region to two because the left and right sides of this text region have different colors, while FOTS predicts this region as a whole because patterns of characters in this text region are continuous and similar. For the Merge case, “Our Detection” method wrongly merges two neighboring text bounding boxes together because they are too close and have similar patterns, while FOTS utilizes the character level information given by text recognition and captures the space between two words.
如图5所示,对于Miss情况,“ Our Detection”方法会错过文本区域,因为它们的颜色与背景相似。对于False情况,“我们的检测”方法将背景区域错误地识别为文本,因为它具有“类似文本”的图案(例如,具有高对比度的重复结构条纹),而FOTS在训练后考虑了细节的识别损失避免了此错误建议区域中的字符数。对于分割情况,“我们的检测”方法将文本区域分为两个,因为该文本区域的左侧和右侧具有不同的颜色,而FOTS预测该区域为一个整体,因为该文本区域中的字符模式是连续且相似的。对于合并情况,“我们的检测”方法将两个相邻的文本边界框错误地合并在一起,因为它们太近且具有相似的样式,而FOTS利用了文本识别所提供的字符级信息并捕获了两个单词之间的空格。


6.3.Comparisons with State-of-the-Art Results
In this section, we compare FOTS to state-of-the-art methods. As shown in Tab. 2, 3, 4, our method outperforms all others by a large margin in all datasets. Since ICDAR 2017 MLT does not have text spotting task, we only report our text detection result. All text regions in ICDAR 2013 are labeled by horizontal bounding box while many of them are slightly tilted. As our model is pre-trained using ICDAR 2017 MLT data, it also can predict orientations of text regions. Our final text spotting results keep predicted orientations for better performance, and due to the limitation of the evaluation protocol, our detection results are the minimum horizontal circumscribed rectangles of network predictions. It is worth mentioning that in ICDAR 2015 text spotting task, our method outperforms previous best method [43, 44] by more than 15% in terms of F-measure.
在本节中,我们将FOTS与最新方法进行比较。 如标签2、3、4所示,我们的方法在所有数据集中的表现都比其他方法好很多。 由于IC DAR 2017 MLT没有文本识别任务,因此我们仅报告文本检测结果。 ICDAR 2013中的所有文本区域均由水平边界框标记,其中许多区域略微倾斜。 由于我们的模型已使用ICDAR 2017 MLT数据进行了预训练,因此也可以预测文本区域的方向。 我们最终的文本发现结果将保持预测的方向,以实现更好的性能,并且由于评估协议的限制,我们的检测结果是网络预测的最小水平外接矩形。 值得一提的是,在ICDAR 2015文本查找任务中,就F度量而言,我们的方法比以前的最佳方法[43,44]高出15%以上。
For single-scale testing, FOTS resizes longer side of input images to 2240, 1280, 920 respectively for ICDAR 2015, ICDAR 2017 MLT and ICDAR 2013 to achieve the best results, and we apply 3-5 scales for multi-scale testing.
对于单尺度测试,对于ICDAR 2015,ICDAR 2017 MLT和ICDAR 2013,FOTS会将较长图像的长边尺寸分别调整为2240、1280和920,以获得最佳结果,并且我们将3-5尺度用于多尺度测试。 。
6.4.Speed and Model Size
As shown in Tab. 5, benefiting from our convolution sharing strategy, FOTS can detect and recognize text jointly with little computation and storage increment compared to
a single text detection network (7.5 fps vs. 7.8 fps, 22.0 fps vs. 23.9 fps), and it is almost twice as fast as “Our Two-Stage” method (7.5 fps vs. 3.7 fps, 22.0 fps vs. 11.2 fps). As a consequence, our method achieves state-of-the-art performance while keeping real-time speed. All of these methods are tested on ICDAR 2015 and ICDAR 2013 test sets. These datasets have 68 text recognition labels, and we evaluate all test images and calculate the average speed. For ICDAR 2015, FOTS uses 2240×1260 size images as inputs, “Our Two-Stage” method uses 2240×1260 images for detection and 32 pixels height cropped text region patches for recognition. As for ICDAR 2013, we resize longer size of input images to 920 and also use 32 pixels height image patches for recognition. To achieve real-time speed, “FOTS RT” replaces ResNet-50 with ResNet-34 and uses 1280×720 images as inputs. All results in Tab. 5 are tested on a modified version Caffe [23] using a TITAN-Xp GPU.
如标签所示。 5,受益于我们的卷积共享策略,FOTS可以与较少的计算和存储增量相比,共同检测和识别文本
单个文本检测网络(7.5 fps对7.8 fps,22.0 fps对23.9 fps),几乎是“我们的两阶段”方法(7.5 fps对3.7 fps,22.0 fps对11.2 fps)的两倍。 )。结果,我们的方法在保持实时速度的同时达到了最先进的性能。所有这些方法都在ICDAR 2015和ICDAR 2013测试仪上进行了测试。这些数据集具有68个文本识别标签,我们评估所有测试图像并计算平均速度。对于ICDAR 2015,FOTS使用2240×1260尺寸的图像作为输入,“我们的两阶段”方法使用2240×1260的图像进行检测,并使用32像素高的裁剪文本区域补丁进行识别。对于ICDAR 2013,我们将输入图像的较长尺寸调整为920,并使用32像素高的图像块进行识别。为了实现实时速度,“ FOTS RT”将ResNet-50替换为ResNet-34,并使用1280×720图像作为输入。所有结果都在选项卡中。使用TITAN-Xp GPU在改进版Caffe [23]上测试了5个。
7.Conclusion
In this work, we presented FOTS, an end-to-end trainable framework for oriented scene text spotting. A novel RoIRotate operation is proposed to unify detection and recognition into an end-to-end pipeline. By sharing convolutional features, the text recognition step is nearly costfree, which enables our system to run at real-time speed. Experiments on standard benchmarks show that our method significantly outperforms previous methods in terms of efficiency and performance.
在这项工作中,我们介绍了FOTS,这是一种用于定向场景文本定位的端到端可训练框架。 提出了一种新颖的RoIRotate操作,以将检测和识别统一到端到端管道中。 通过共享卷积功能,文本识别步骤几乎是免费的,这使我们的系统能够实时运行。 在标准基准上进行的实验表明,在效率和性能方面,我们的方法明显优于以前的方法。














 1311
1311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









