







opencv 实时识别指定物体
一. 引入
opencv人脸识别大家应该都听说过,本篇目的是利用opencv从视频帧中识别指定的物体,并框出来,且可以保存截取到的物体图片,会将整个流程都讲一下,包括训练自己的分类器,使用训练好的分类器进行识别。这里以识别舌头为例。
二. 环境:
1. python 3.6.3
2. opencv 3.4.0
三. 训练自己的分类器
1. 注意点:训练集分为正样本,负样本,样本全部为灰度图片,正样本图片尺寸需要固定,一般40*40左右即可,大了电脑跑不动,负样本尺寸不固定,负样本数量要比正样本多才行,少了有问题。
图片批量缩小工具下载:链接:https://pan.baidu.com/s/1pMAp19p 密码:vpp1
图片批量灰度处理:使用美图秀秀
2. 正样本制作,使用美图秀秀将舌头的图片全部裁剪出来(尺寸一致为:40*40的),保存到一个文件夹pos中,当然可以先用大尺寸正方形框进行裁剪,然后再用图片缩小工具进行制定尺寸缩小。最后再用美图秀秀批量灰度化。
附上名字自动有序化Java代码:
String path = "C:\\Users\\Administrator\\Desktop\\pos\\";
File f = new File(path);
File[] files = f.listFiles();
for (File file : files) {
i++;
file.renameTo(new File(path+i+"."+file.getName().split("\\.")[1]));
}
处理后得到如下所示图片:

3. 负样本制作:如上操作类似,不过这里不要求尺寸一样,但是负样本图片中一定不要包含待识别的区域(如这里的:舌头)
如下所示:
4. 生成样本资源记录文件:
a. 正样本
资源记录文件
新建pos文件夹,将正样本的灰度图拷贝进去
使用JAVA代码生成正样本资源记录文件:
String path = "E:\\tools\\python\\eclipse\\work\\pythonTest\\demo\\0202\\img\\train\\tongue\\pos\\";
File txtfile = new File(path+"pos.txt");
FileOutputStream fos = new FileOutputStream(txtfile);
PrintWriter pw = new PrintWriter(fos,true);
String s = "";
File[] files = new File(path).listFiles();
for (File file : files) {
pw.println("pos/"+file.getName()+" 1 0 0 40 40");
}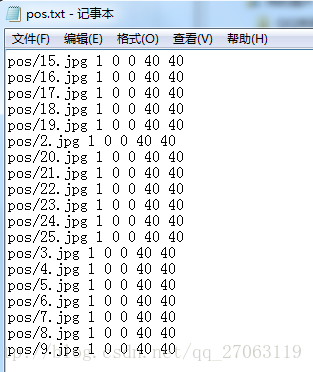
(1 0 0 40 40)分别指代: 数量 左上方的坐标位置(x,y) 右下方的坐标位置(x,y)
处理好后,将pos.txt 移动到上一级文件夹
b. 负样本资源记录文件
新建neg文件夹,将负样本的灰度图拷贝进去
使用JAVA代码生成负样本资源记录文件:
String path = "E:\\tools\\python\\eclipse\\work\\pythonTest\\demo\\0202\\img\\train\\tongue\\neg\\";
File txtfile = new File(path+"neg.txt");
FileOutputStream fos = new FileOutputStream(txtfile);
PrintWriter pw = new PrintWriter(fos,true);
String s = "";
File[] files = new File(path).listFiles();
for (File file : files) {
pw.println("neg/"+file.getName());
}
处理好后,将negtxt 移动到上一级文件夹
得到如图所示文件夹结构:

5. 使用opencv提供的opencv_createsamples.exe程序生成样本vec文件,新建批处理文件:createsamples.bat
内容如下:
opencv_createsamples.exe -vec pos.vec -info pos.txt -num 25 -w 40 -h 40
pause
说明:25是正样本图片的数量 40 40 是正样本图片的宽高
这些参数的详细解释:http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html
运行后会生成 pos.vec文件
6. 使用opencv提供的opencv_traincascade.exe程序训练分类器,新建xml文件夹,再新建批处理文件:LBP_train.bat
内容如下:
opencv_traincascade.exe -data xml -vec pos.vec -bg neg.txt -numPos 25 -numNeg 666 -numStages 10 -w 40 -h 40 -minHitRate 0.999 -maxFalseAlarmRate 0.2 -weightTrimRate 0.95 -featureType LBP
pause
具体参数解释请查看文档:http://www.opencv.org.cn/opencvdoc/2.3.2/html/doc/user_guide/ug_traincascade.html
运行后会在xml文件夹生成如下文件:
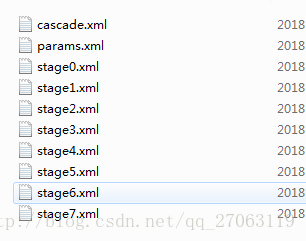
其中cascade.xml是我们需要使用的分类器
四 . 测试训练好的分类器
'''
Created on 2018年2月2日
实时人脸检测
@author: nuohy
'''
import cv2
# 加载opencv自带的人脸分类器
# faceCascade = cv2.CascadeClassifier("haarcascade_frontalface_alt2.xml")
# faceCascade.load('E:/python/opencv/opencv/sources/data/haarcascades/haarcascade_frontalface_alt2.xml')
faceCascade = cv2.CascadeClassifier("cascade.xml")
faceCascade.load('E:/tools/python/eclipse/work/pythonTest/demo/0202/img/train/tongue/xml/cascade.xml')
cap = cv2.VideoCapture(0)
flag = 0
timeF = 10
while True:
flag+=1
ret, frame = cap.read()
img = frame.copy()
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
rect = faceCascade.detectMultiScale(
gray,
scaleFactor=1.15,
minNeighbors=3,
minSize=(3,3),
flags = cv2.IMREAD_GRAYSCALE
)
for (x, y, w, h) in rect:
cv2.rectangle(frame, (x, y), (x+w, y+h), (0, 255, 0), 2)
#识别到物体后进行裁剪保存
#jiequ = img[x:(x+w), y:(y+h)]
#cv2.imwrite('E://tools//python//eclipse//work//pythonTest//demo//0202//img//save//'+str(flag) + '.jpg',jiequ) #save as jpg
#读取到保存图片
# if(flag%timeF==0):
# cv2.imwrite('E://tools//python//eclipse//work//pythonTest//demo//0202//img//save//'+str(flag) + '.jpg',frame) #save as jpg
cv2.imshow('frame', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()
效果图如下所示:

所有需要用到的文件下载地址: http://download.csdn.net/download/qq_27063119/10238488
(需要5积分,没有的至我邮箱 nuohy@qq.com)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









