






目录
概述:
看下原文的描述,我英语比较差,只能看个大概意思,贴出原文,怕翻译错误。
文档地址
Getting Started with Distributed Data Parallel — PyTorch Tutorials 1.13.1+cu117 documentation

多机多卡:

这里告诉我们为什么要使用ddp,它更快。
进程组初始化:

告诉我们必须设置进程组属性。
def setup(rank, world_size):
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '12355'
# initialize the process group
dist.init_process_group("gloo", rank=rank, world_size=world_size)master_addr 很显然是主机地址, port是自己指定的。
它给的文档链接:
Writing Distributed Applications with PyTorch — PyTorch Tutorials 1.13.1+cu117 documentation

给出了多种不同的分布式策略。
点到点:
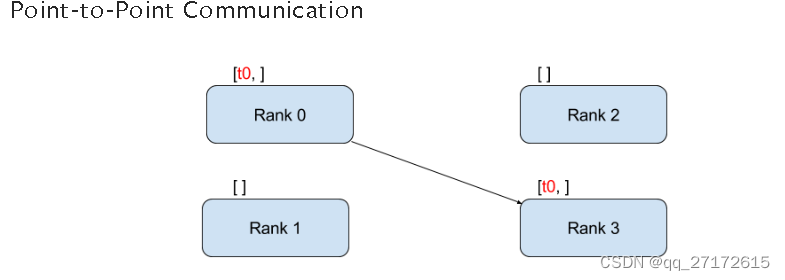
rank:是全局进程数, t0是数据。启动四个进程,将进程号为0的数据发送到 3号进程。
if __name__ == "__main__":
size = 2
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run))
p.start()
processes.append(p)
for p in processes:
p.join()def init_process(rank, size, fn, backend='gloo'):
""" Initialize the distributed environment. """
os.environ['MASTER_ADDR'] = '127.0.0.1'
os.environ['MASTER_PORT'] = '29500'
dist.init_process_group(backend, rank=rank, world_size=size)
fn(rank, size)def run(rank, size):
tensor = torch.zeros(1)
if rank == 0:
tensor += 1
# Send the tensor to process 1
dist.send(tensor=tensor, dst=1)
else:
# Receive tensor from process 0
dist.recv(tensor=tensor, src=0)
print('Rank ', rank, ' has data ', tensor[0])改写: 启动三个进程,进程0 发送数据到进程1,2。 进程1,2执行减法之后,再把数据发送到进程0。 然后进程0将数据合并
def run(rank, size):
tensor1 = torch.tensor([1, 2, 3], dtype=torch.float16)
tensor2 = torch.tensor([4, 5, 6], dtype=torch.float16)
if rank == 0:
# time.sleep(10)
# 0号进程发送数据
dist.send(tensor=tensor1, dst=1)
dist.send(tensor=tensor2, dst=2)
print(f"发送结束当前数据: {tensor1 + tensor2}")
dist.recv(tensor=tensor1, src=1)
dist.recv(tensor=tensor2, src=2)
print(f"接收结束 数据: {tensor1 + tensor2}")
elif rank == 1:
# Receive tensor from process 0
dist.recv(tensor=tensor1, src=0)
print(f"进程号:{rank} 接收后:{tensor1}")
tensor1 -= 1
dist.send(tensor=tensor1, dst=0)
else:
dist.recv(tensor=tensor2, src=0)
print(f"进程号:{rank} 接收后:{tensor2}")
tensor2 -= 1
dist.send(tensor=tensor2, dst=0)Gather:
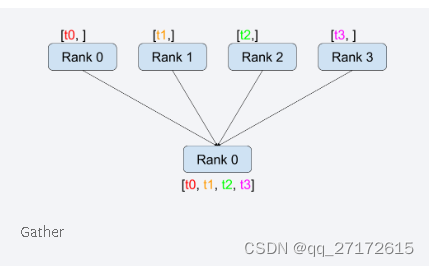
def run(rank, size):
tensor1 = torch.tensor([1, 2, 3], dtype=torch.float16)
tensor2 = torch.tensor([4, 5, 6], dtype=torch.float16)
if rank == 0:
# time.sleep(10)
print(f"接收前数据: {tensor1 + tensor2}")
dist.recv(tensor=tensor1, src=1)
dist.recv(tensor=tensor2, src=2)
print(f"接收结束 数据: {tensor1 + tensor2}")
elif rank == 1:
# Receive tensor from process 0
tensor1 -= 1
dist.send(tensor=tensor1, dst=0)
else:
tensor2 -= 1
dist.send(tensor=tensor2, dst=0)
print(f"当前进程号:{rank} 数据 {tensor1 + tensor2}")Reduce:
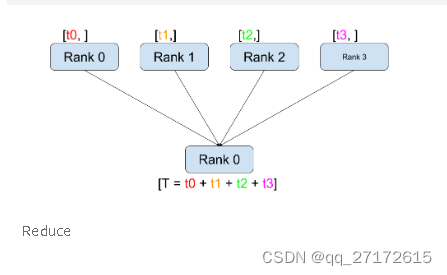
比之前多一个计算
All-Reduce:
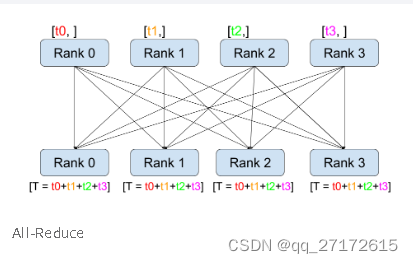
def run(rank, size):
tensor = torch.arange(2, dtype=torch.int64) + 1 + 2 * rank
print(f"当前进程号: {rank}, {tensor}")
tensor -= 1
print(f"当前进程号:{rank} 数据减一等于 {tensor}")
dist.all_reduce(tensor, op=ReduceOp.SUM)
print(f"当前进程号:{rank} 数据 {tensor}")每个节点都有一份完整的数据:
比如 to, t1, t2, t3 表示梯度。 那么意味着 rank 0, 1,2,3节点的梯度值都一样。

梯度是个累加的,然后求一个均值。 比如:0 ,1, 2, 3 批量大小是16 然后求出了梯度值 to, t1, t2, t3。 则 (to + t1 + t2 + t3 )/ 4 === t / (16 * 4 )。
所以,假设我们要训练批量大小为64的数据, 4个gpu。那么每一个gpu取 16。
分布式实现:
基本思路: 如果我有四块gpu,那么启动四个进程。一个gpu对应一个进程。
1.每个进程自己去读数据。
根据dataset len()切分数据。 比如:dataset长 60000 ,我有四个进程 则每个进程的dataset为
15000。 如果我想训练128批量大小的数据,那么每个进程的批量大小 128 / 4 = 32
2. 每个进程单独计算梯度。 然后all_reduce所有梯度。 最后每个进程自己更新梯度值。
class Partition(object):
def __init__(self, data, index):
self.data = data
self.index = index
def __len__(self):
return len(self.index)
def __getitem__(self, index):
data_idx = self.index[index]
return self.data[data_idx]
class DataPartitioner(object):
def __init__(self, data, sizes=[0.7, 0.2, 0.1], seed=1234):
self.data = data
self.partitions = []
rng = Random()
rng.seed(seed)
data_len = len(data)
indexes = [x for x in range(0, data_len)]
rng.shuffle(indexes)
for frac in sizes:
part_len = int(frac * data_len)
self.partitions.append(indexes[0:part_len])
indexes = indexes[part_len:]
def use(self, partition):
return Partition(self.data, self.partitions[partition])
def partition_dataset():
dataset = datasets.MNIST('./data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
size = dist.get_world_size()
print(size)
bsz = 128 / float(size)
partition_sizes = [1.0 / size for _ in range(size)]
partition = DataPartitioner(dataset, partition_sizes)
partition = partition.use(dist.get_rank())
train_set = DataLoader(partition,
batch_size=int(bsz),
shuffle=True)
return train_set, bszdef run4(rank, size):
torch.manual_seed(1234)
train_set, bsz = partition_dataset()
model = nn.Sequential(nn.Flatten(), nn.Linear(784, 10))
optimizer = optim.SGD(model.parameters(),
lr=0.01, momentum=0.5)
num_batches = ceil(len(train_set.dataset) / float(bsz))
loss = nn.CrossEntropyLoss(reduction='none')
for epoch in range(10):
epoch_loss = 0.0
for data, target in train_set:
output = model(data)
l = loss(output, target)
if isinstance(optimizer, torch.optim.Optimizer):
optimizer.zero_grad()
epoch_loss += float(l.detach().sum())
l.mean().backward()
average_gradients(model)
optimizer.step()
print('Rank ', dist.get_rank(), ', epoch ',
epoch, ': epoch_loss:', epoch_loss / num_batches)
""" Gradient averaging. """
def average_gradients(model):
size = float(dist.get_world_size())
for param in model.parameters():
dist.all_reduce(param.grad.data, op=dist.ReduceOp.SUM)
param.grad.data /= size if __name__ == "__main__":
size = 4
processes = []
mp.set_start_method("spawn")
for rank in range(size):
p = mp.Process(target=init_process, args=(rank, size, run4))
p.start()
processes.append(p)
for p in processes:
p.join()














 6288
6288











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









