







 本文介绍了一种使用Python爬虫从Wallhaven网站自动下载高清壁纸的方法。通过分析网站结构,利用正则表达式匹配图片链接并保存至本地。
本文介绍了一种使用Python爬虫从Wallhaven网站自动下载高清壁纸的方法。通过分析网站结构,利用正则表达式匹配图片链接并保存至本地。
得知wallpaper这个高清壁纸网站后,开始了漫长的手动下载壁纸。
但是这个过程实在是太浪费时间了,于是开始研究wallpaper网站的结构目录。
python定向爬取wallhaven壁纸一文中提供了一个最基本的爬图片方法,但是需要指定图片标号,不能根据分类来抓取图片。
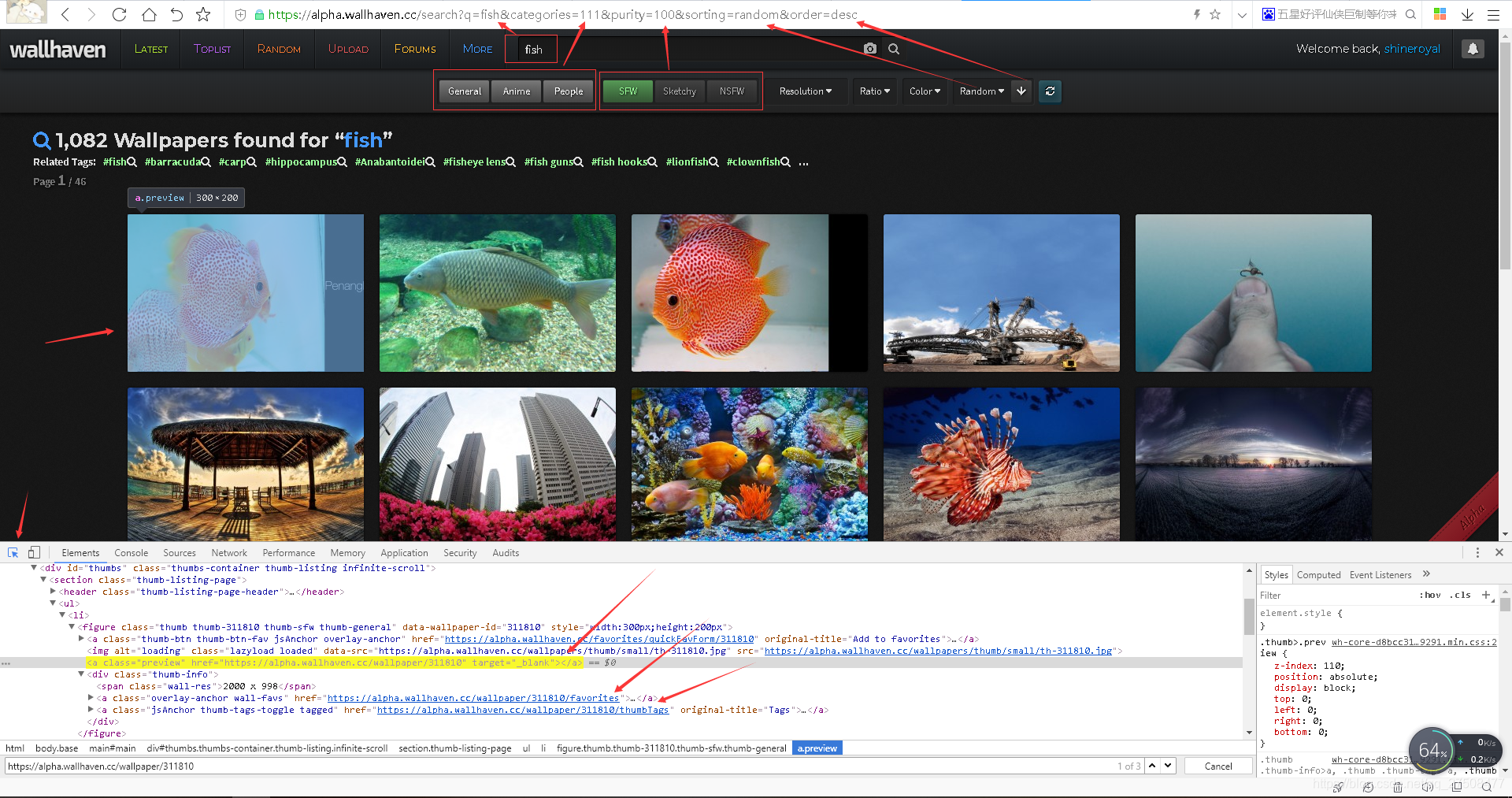
任意搜索关键字可以看到地址栏的搜索是有据可循的,F12查看可以发现指向一张图片标号同一个链接会出现三次(笔者正则用的不是很会),所以findall找到的三个相连链接都是相同的。
然后就是欢快的保存了~
import requests
import re
import os
def getImg(page):
url=r'https://alpha.wallhaven.cc/search?q=fish&categories=111&purity=100&sorting=random&order=desc&page='+str(page)
page_pattern=r'https://alpha.wallhaven.cc/wallpaper/\d+' #匹配图片page的正则
image_pattern=r'//wallpapers.wallhaven.cc/wallpapers.+?(jpg|png)' #匹配图片img的正则
path='D:/Mypicture'
r=requests.get(url)
r.encoding=r.apparent_encoding
mainpage=r.text
page_mattch=re.findall(page_pattern,mainpage) #查找主页中所有的img连接
print(len(page_mattch))
for i in range(len(page_mattch)):
if(i%3==0):
rr=requests.get(page_mattch[i])
rr.encoding=rr.apparent_encoding
mattch=re.search(image_pattern,rr.text)
if mattch:
print(mattch.group(0))
img=requests.get("https:"+mattch.group(0))
if(not os.path.exists(path)): #保存图片的路径不存在则创建
os.mkdir(path)
if(img.url.endswith('.jpg')): #不同格式的图片
with open('D:/Mypicture/'+re.search(r'wallhaven-\d+',mattch.group(0)).group(0)+'.jpg','wb') as f:
f.write(img.content) #将图片保存到本地
f.close()
elif (img.url.endswith('.png')):
with open('D:/Mypicture/'+re.search(r'wallhaven-\d+',mattch.group(0)).group(0)+'.png','wb') as f:
f.write(img.content)
f.close()
else:
print('爬取失败,图片后缀为:'+img.url[-4:])
print('第'+str(i+1)+'次爬取\t成功!')
else:
print("第{}次爬取\t失败!".format(i+1))
def main():
getImg(1)
getImg(2)
getImg(3)
main()

















 462
462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









