






点击上方,选择星标或置顶,每天给你送干货!
MIND简介
个性化新闻推荐技术是诸多在线新闻网站和应用的关键技术,可以提升用户的新闻阅读体验并减轻信息过载。目前,许多有关新闻推荐的研究是在私有数据集上开展的,而已有的公开数据集往往规模较小。高质量基准数据集的缺乏限制了新闻推荐领域的研究进展。因此,微软亚洲研究院联合微软新闻产品团队在 ACL 2020上发布了一个大规模的英文新闻推荐数据集 MIcrosoft News Dataset (MIND[1]),并于2020年7月-9月在condalab平台举办了MIND新闻推荐比赛。比赛吸引了来自加拿大、法国、韩国等全球各地的技术团队,最终来自搜狗搜索的队伍以AUC 0.7131获得比赛冠军。我们也在赛后开源了比赛过程中的代码[2]。

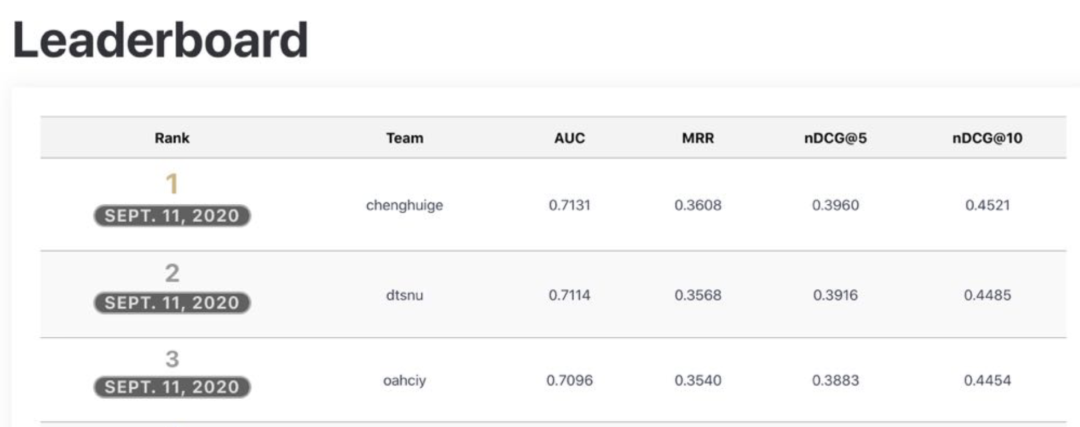
非常值得赞许的是赛后微软继续开放了MIND比赛系统允许提交测试结果并实时更新排行榜[3]。我们在近期提交了新的结果,相对比赛结果有了进一步提升,在截止到2021-01-04的榜单以AUC 0.7187的成绩排在第一位。
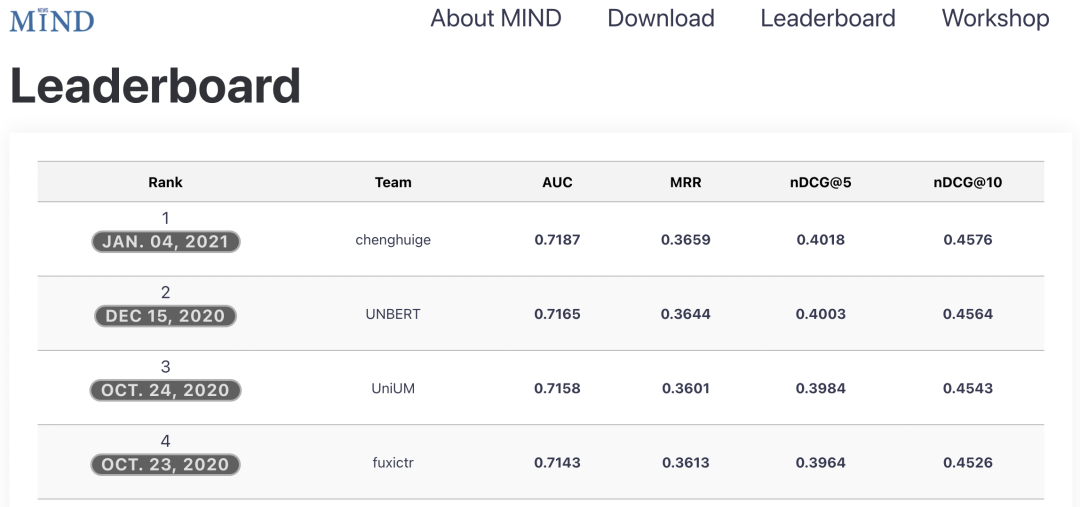
希望有更多的同学能参与到MIND这个高质量的新闻推荐数据集评测,目前的榜单成绩仍然有很大的提升空间。(个人觉得MIND真的是非常好的数据集,很奇怪并没有引起特别大的业界关注,也许是因为比赛放到了codalab平台而不是社区及分享更加完善的kaggle平台)。
新闻推荐简介
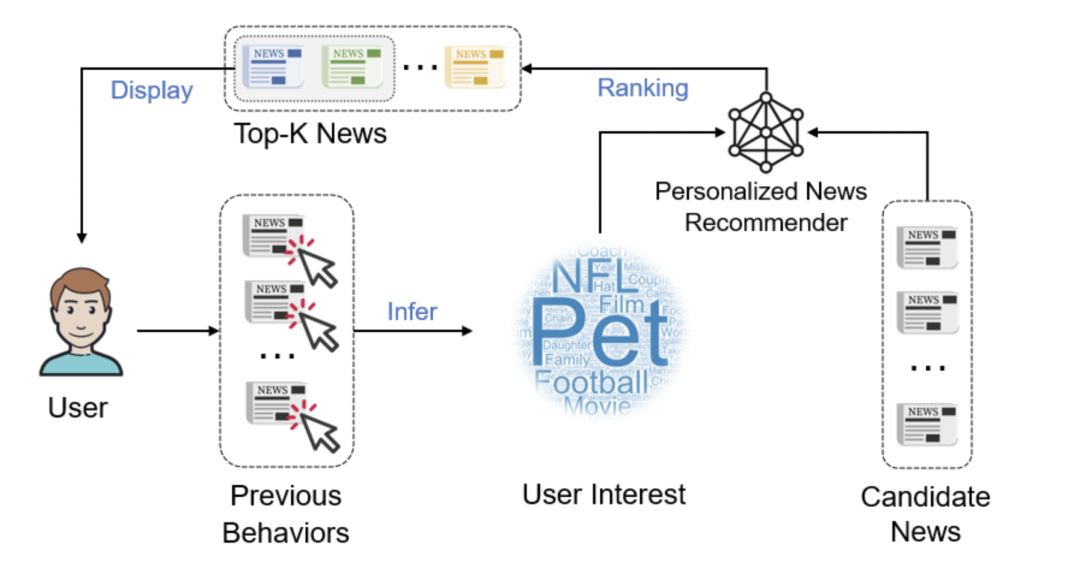
这里新闻推荐主要指基于用户的点击历史,预测用户对未来展现的新闻点击概率从而用于指导对于展现给用户的召回新闻排序。新闻推荐是一个经典的推荐排序问题,主要面临的困难包括新闻和用户的有效建模,新闻及用户冷启动等等问题。
MIND数据分析及处理
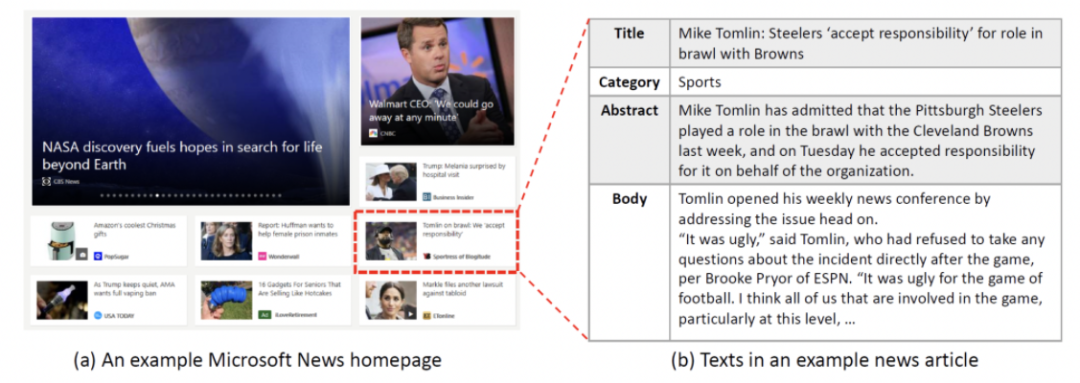
MIND数据集是从六周内 Microsoft News 用户的匿名化新闻点击记录中构建的,它包含16万多条新闻条目,1500 余万次展示记录,以及来自100万匿名用户的2400余万次点击行为。在 MIND 数据集中,每个新闻条目都具有丰富的文本信息,例如标题、摘要、正文、类别和实体。
下面介绍MIND数据的特点及处理策略:
ID失效
MIND数据是来自于工业界真实的点击数据但是和传统的工业界实际的推荐系统使用的数据还是有较大的差异性,这种差异主要来自定位的不同,MIND更加强调推荐算法的泛化性,而实际工业界强调时效性实用性,因此工业界推荐系统最重要的特征往往是ID特征特别是docid特征,工业界的模型特别是ID对应的embedding基本也是实时快速更新的。
但对应MIND这个数据ID特征依然存在但不再是最重要的特征,甚至绝大部分的参赛队伍没有使用ID特征,这使得MIND数据更像是一个纯NLP比赛数据。为什么?这主要来自于Dev和Test数据的差异。
| Info | Dev | Test |
|---|---|---|
| 新用户 | 15.3% | 22.1% |
| 新文档 | 32.3% | 87.5% |
MIND数据的训练数据是5周的点击日志,除去最后一天作为Dev数据,而Test数据是要对第6周数据做预测。
由于新闻的时效性非常强,所以显然未来一周中的新文档的占比可以预见是非常多的(87.5%)。
由于这样的数据特点,因此主要依赖的ID的模型显然是失效的,传统的gbdt模型也不太适用这个数据。 这个数据的重点是如何能更好的对新闻内容建模。
这样的Dev和Test的划分,也带来了本地Dev验证和提交Test验证的不一致性,为了消除这个不一致性,如果在训练中使用了docid特征需要注意在验证的时候Mask掉92%(保持新文档比例和Test一致)或者干脆Mask掉全部的docid,当做UNK处理。
在比赛前期这个策略非常有效基本确保了验证和测试的一致性,但是比赛后期模型分数相对较高的情况下还是发现Dev和Test有较大不一致性,比如引入刷次(impression)内部的特征在Dev数据提升非常大但是在Test无效,加大正样本权重从1.0到4.0也能大幅度提升Dev AUC但是同样在Test无效。
因此更进一步的也许自行重新划分Train/Dev为4周数据训练第5周整周做Dev可以更好确保的Dev和Test的一致性,由于时间原因笔者没有做这个实验有兴趣的同学可以测试一下。
样本不均衡的处理
MIND数据的另外一个重要特点是类别不均衡,正样本率很低只有4%。
处理类别不均衡的样本有很多策略,比如
正样本加权
正样本过采样
负样本降采样
等等,这里考虑到训练样本量非常大,模型计算较为耗时,综合多种因素和实验结果我们采用了无放回的负样本随机采样,将原始训练数据的负样本划分成5个部分,配合全部的正样本构造了5个不同训练数据集,Dataset0-4,每个数据集的正样本率约为16.5%。
这样我们的单模型训练只基于Dataset0实验,这极大的降低了模型训练时间(不使用bert只需要45-60分钟完成单模型训练并在不使用Dev数据的前提下达到Test AUC 0.7074,而使用bert-tiny的模型可以在大约7-8个小时完成训练),同时提交结果显示相对使用全量训练数据,降采样数据训练的单模型的效果并没有明显下降。
而当需要最佳榜单成绩的时候我们采用了同样策略针对Train+Dev数据整体构造5个数据集,并且并行训练5个基于不同Dataset的模型,将结果平均作为最终结果。实验表明训练数据多样性带来的模型集成收益非常明显。
单模型与集成模型的定义
单模型:基于Dataset0(1/5负样本+全部正样本,不包含Dev数据)训练的单一模型。
集成模型:基于Dataset0-4(包含Dev数据)5份数据训练的5个模型结果的平均。
模型结构
我们采用了经典的推荐系统中的精排模型架构,而没有采用官方基线模型提供的各种基于双塔向量匹配的模型结构(NRMS,NAML等等)。
我们认为双塔结构更加适合召回阶段,因为新闻和用户分别建模向量虽然快速灵活但是由于其分开独立建模缺乏前期交互,整体效果一般是不如完整的所有特征统一交互建模的方式。
我们使用的结构基本和Facebook提出的DLRM模型结构一致,与DLRM只用到特征交叉不同,考虑到特征组不是特别多,这里同时采用特征交叉和特征合并两种组合方式,保证MLP层的输入有足够的信息量(当然也可以考虑引入更多组合信息如max pooling,attention pooling,self attention pooling等等)。
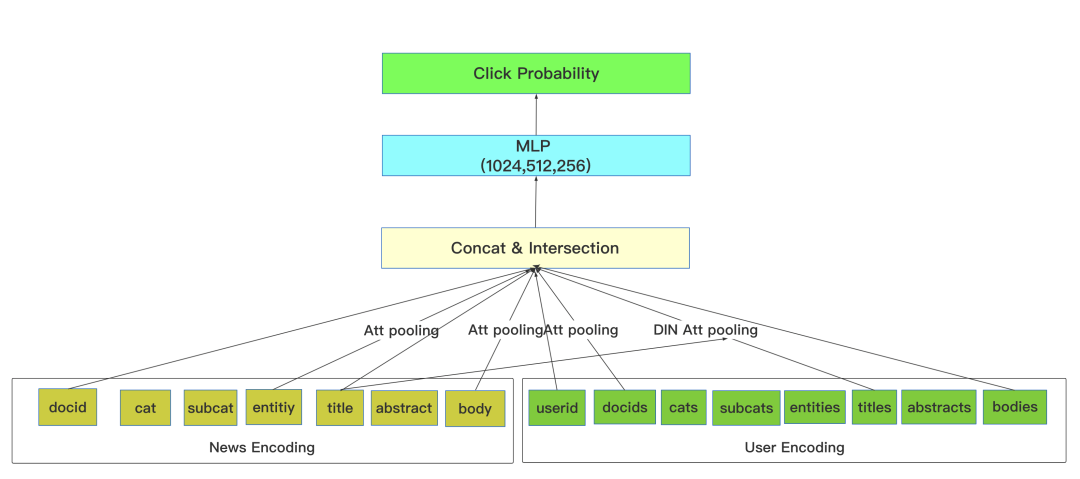
在对应对具体文本建模的时候,我们采用了基于glove预训练的词向量,文本分词采用了bert bpe切词器。
我们针对ID表示的向量采用了简单的自注意力(attention pooling)方式建模,而针对复杂文本如正文,标题,摘要采用了DIN attention pooling的方式,以便更好的动态建模当前新闻和用户阅读历史新闻的相关性。
单特征重要性分析
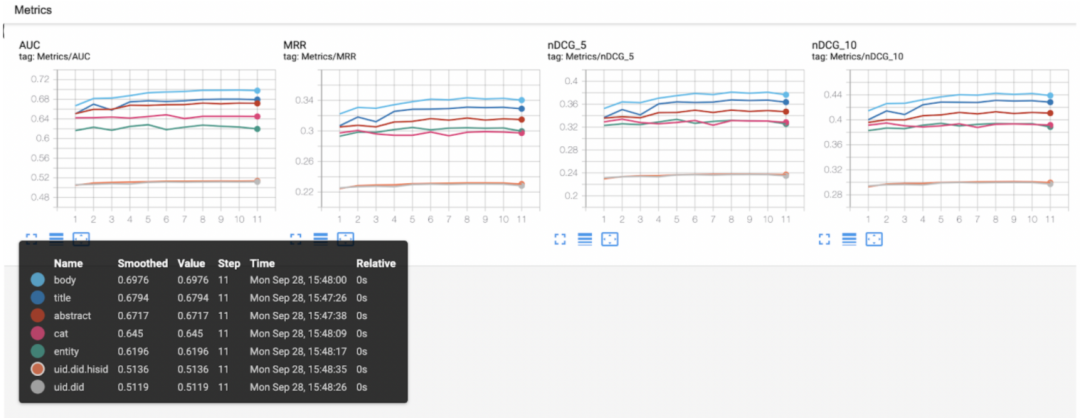
通过验证集合来看文本正文是最重要的信息,有点出乎意料是不是,最重要的特征是正文而不是标题。
整体特征重要性顺序依次是:正文,标题,摘要,类别,实体,ID。
ID特征的重要性
在比赛中我们和其他队伍的一个重要区别是,其他队伍大都基本基于官方基线做的改进,并没有使用ID特征,而我们在训练中使用了ID特征。
在验证中Mask掉了ID特征来保证验证和Test的一致性,在Test的时候我们保留在训练中出现的docid而mask掉了其他docid。
尽管Test的有效docid比例非常之少,但是我们得到一个很重要的结论,就是训练数据中的docid可以帮助更好的进行整体建模,ID特征和文本特征的交互能够帮助学习得到更好的文本表示。
| Single Model | Test AUC |
|---|---|
| No ID | 0.6988 |
| With ID | 0.7074 |
Bert Encoder
显然单纯的词向量模型在NLP相关的竞赛中已经是属于上古时代了,现在是属于bert的时代,但是MIND这个数据由于需要对用户历史新闻的正文,标题,摘要建模,假设取top50的历史这个计算量是非常巨大的,因此大的bert模型并不是非常实用。
在比赛过程中我没有采用bert作为encoder。赛后我尝试使用小的bert模型比如bert-tiny,在经过MIND语料continue train 语言模型之后,作为文本encoder。
实验结果似乎相对词向量优势也并不是很明显(后面的模型迭代部分会贴出实验结果),当然这个原因可能是多方面包括参数的调整(特别的比如bert模型finetune对于学习率异常敏感)以及bert-tiny本身的表示能力不够强大,再或者和推荐数据特点有关等等需要更进一步的分析。
我相信这部分显然还可以做的更好,也许目前榜单第二第三的UNBERT和UniUM在这方面做的更好(猜测使用UniLM)期待后续有机会交流以找到更好的bert打开方式。
尽管没有取得特别惊艳的单模型效果,bert模型依然带来了很好的模型多样性,这帮助我们取得了目前MIND dataset的STOA,当然这也说明MIND榜单的提升空间显然还是很大的。
迭代过程
比赛中
| Model | Dev AUC | Test AUC |
|---|---|---|
| uid,docid,history_docids | 0.514 | 0.5272 |
| +cat,entity | 0.6829 | 0.6763 |
| +title,abstract | 0.6987 | 0.6979 |
| adjust parameters | 0.7004 | 0.7036 |
| +body | 0.7042 | 0.707 |
| +dev data | NA | 0.7104 |
| ensemble(5 datasets) | NA | 0.7131 |
赛后
赛后的集成模型提升主要是来自于模型差异性的引入,从比赛过程中的单一算法模型变成了多算法模型(引入了bert)。
那么单模型提升在哪里呢?
单模型方面并没有做大的调整,主要提升点是两个细节:
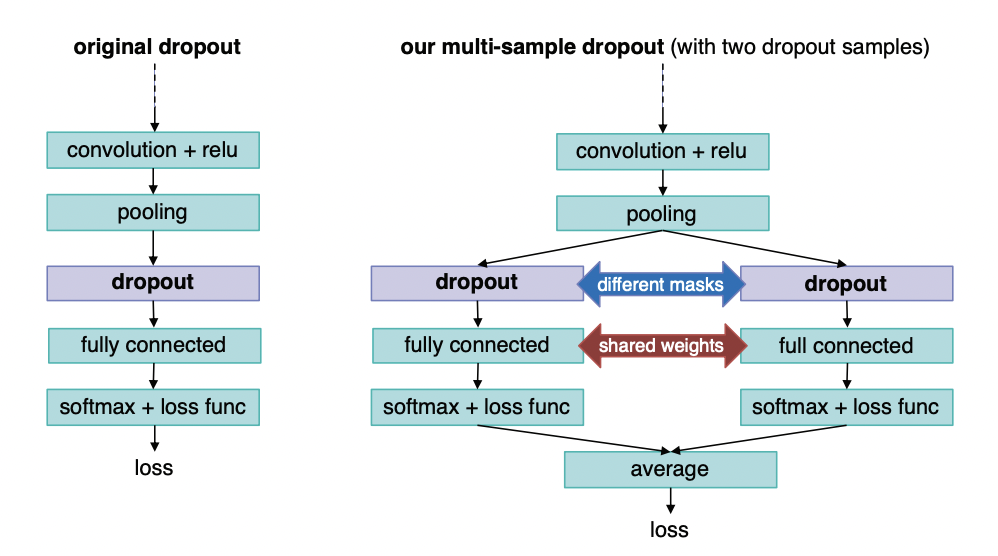
Multi-Sample Dropout降低过拟合提升模型泛化能力。
不只是MIND数据,Multi-Sample Dropout是一种通用且时空代价极小的方法,在很多场景下用其取代最终的Linear层都能带来效果提升,感兴趣可以在kaggle搜索相关的分享。
Batch size 调整, 从2048调小到256。
batch size减小会使得训练速度变慢一点,并且val loss会变高,但是Test指标会提升,可能原因是更多的梯度迭代次数,特别是当前采用1轮训练方式,另外小的batch size对应单一模型不同Dataset可能有更高的单模型差异性从而有利于模型集成。
以下只列出Test的指标,注意集成模型base复现的起点0.7124比比赛中最终的模型0.7131低一些,可能源自tf1,2的切换和一些随机性因素,暂未查明。
单模型
| Model | AUC | MRR | NDCG@5 | NDCG@10 |
|---|---|---|---|---|
| base复现 | 0.7074 | 0.3554 | 0.3895 | 0.4460 |
| +multi-sample dropout | 0.7086 | 0.3557 | 0.3900 | 0.4464 |
| +smaller batch size | 0.7089 | 0.3574 | 0.3916 | 0.4478 |
| bert-tiny | 0.707 | 0.3563 | 0.3902 | 0.4464 |
| base add bert-tiny | 0.7085 | 0.3577 | 0.3920 | 0.4482 |
集成模型
| Model | AUC | MRR | NDCG@5 | NDCG@10 |
|---|---|---|---|---|
| base复现 | 0.7124 | 0.3598 | 0.3949 | 0.4512 |
| +multi-sample dropout | 0.7139 | 0.3614 | 0.3967 | 0.4529 |
| +smaller batch size | 0.7145 | 0.3625 | 0.3976 | 0.4537 |
| bert-tiny | 0.7145 | 0.3622 | 0.3973 | 0.4533 |
| base add bert-tiny | 0.7158 | 0.3630 | 0.3983 | 0.4544 |
| avg of above 3 | 0.7187 | 0.3659 | 0.4018 | 0.4576 |
注:base add bert-tiny表示模型的文本表示在同一个模型同时保留glove词向量和bert-tiny encode作为特征。其实采用单一模型结构多数据集/多fold的模型平均某种意义上也是单模型,从上面的结果来看,base add bert-tiny应该是相对base表现更好的模型结构。
TODO
更好的文本表示,如UniLM等,这也是MIND数据集合的根本意义所在,期待找到效果更好效率更高的文本表示方法。
更好的用户历史阅读序列表示,当前没有引入位置信息,没有考虑用户历史顺序,没有做复杂的历史建模。
更好的模型泛化,从实验来看test集合的提升很大概率来自模型泛化效果的提升,更好的集成方法(当前只是简单平均),包括单模型自身集成方法如SWA等等应该可以进一步提升效果。
更多轮次迭代?由于使用了ID特征容易过拟合,当前只采用了1轮训练的方。
降采样负样本是否是最好的方案?显然值得更多的尝试,至少在单模型效果使用全量负样本做一定正样本过采样但是同时注意避免过拟合应该理论上能得到更好的单一模型,毕竟当前的单模型都只用了部分训练数据。
作者简介

程惠阁,搜狗搜索专家研究员。
曾任百度贴吧和信息流反作弊,图片搜索部图文相关性技术负责人。
数据挖掘,深度学习爱好者,曾多次单人参赛并获得AI竞赛冠亚军:
NAIC 2020 全国人工智能大赛 AI+遥感影像语义分割 第二名。
ACL 2020 MIND 新闻推荐 第一名。
AI Challenger 2018 美团细粒度情感分类 第一名。
AI Challenger 2017 Image Caption 第二名。
目前是Kaggle Expert,个人梦想是退休后成为Kaggle Grandmaster。
参考资料
[1]
MIND: https://msnews.github.io/
[2]代码: https://github.com/chenghuige/mind
[3]排行榜: https://competitions.codalab.org/competitions/24122#results
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
推荐两个专辑给大家:
专辑 | 李宏毅人类语言处理2020笔记
整理不易,还望给个在看!


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









